Microsoft Fabric : Gestion avancée des rapports Power BI dans Fabric



Introduction
L’objectif de cet article est de présenter la totalité du parcours de la donnée, de l’ingestion des fichiers Excel jusqu’à la data visualisation dans Power BI. On utilisera des données simples, permettant de faire quelques filtres et un classement dynamique. C’est un cas d’usage simple mais concret de l’utilisation courante de tous les outils de Fabric et de quelques fonctionnalités de Power BI.
Contexte et création des ressources
Nos données sont 2 fichiers Excel. Le premier contient une liste de personnes dont on connait l’ID, le nom, la localisation (id_uga), le type de zone à laquel il est rattaché (type_geo) et ses scores sur chacun des produits.
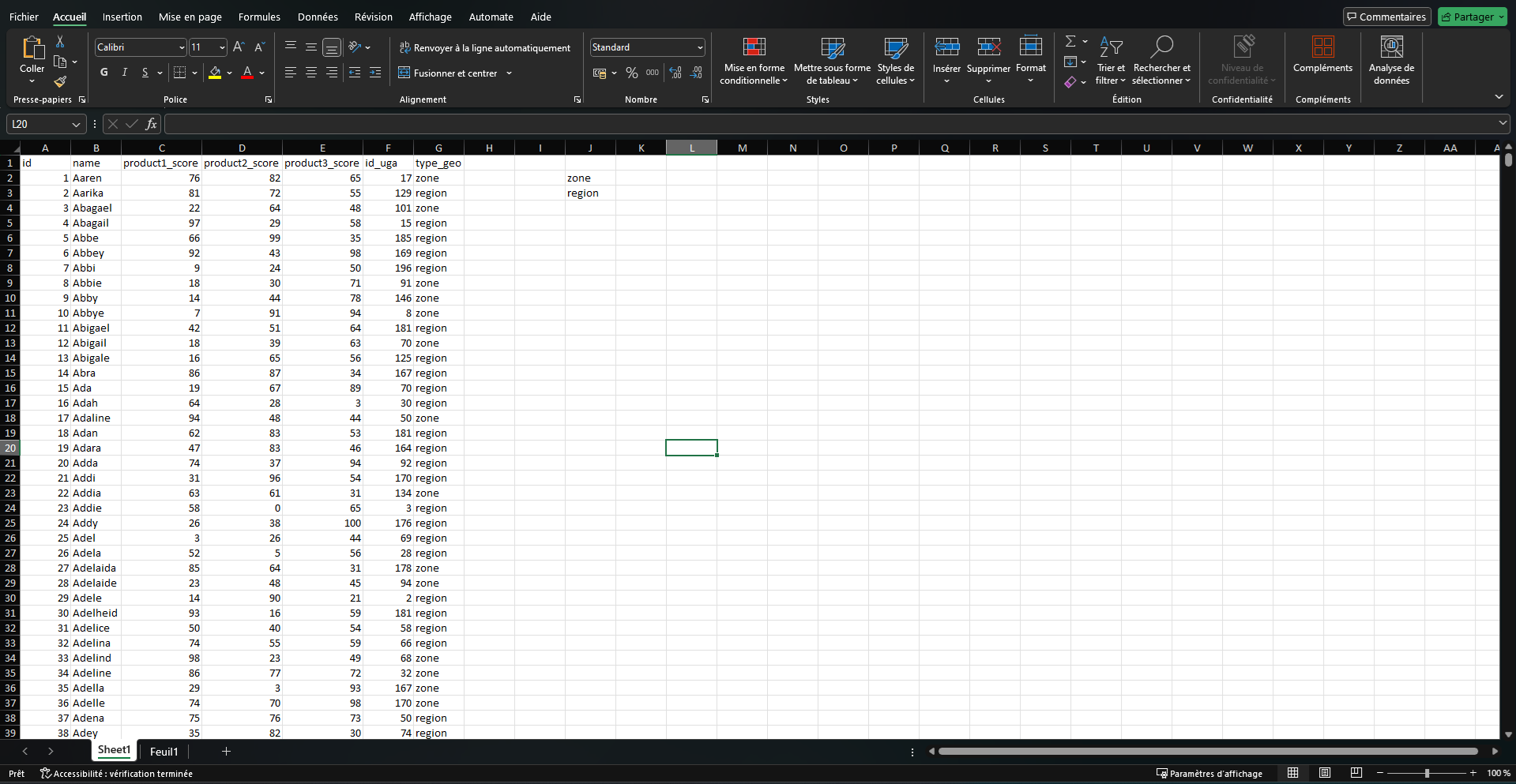
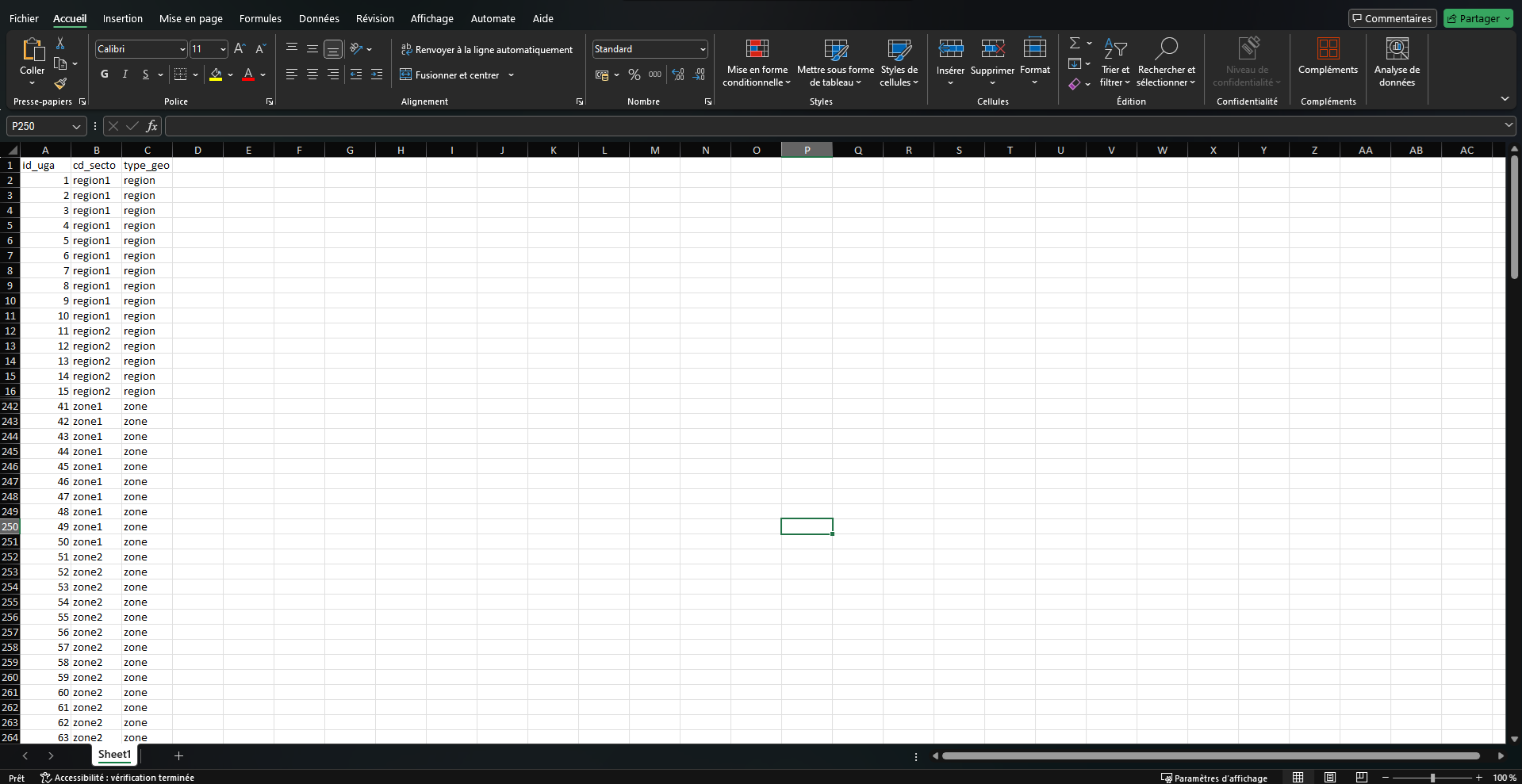
Le second fichier est la dimension géographique. La France est divisée en unité géographique d’analyse (UGA), et ces UGA sont regroupés de façon arbitraire en zone ou en région (colonnes cd_secto et type_geo). Ainsi une personne dans un UGA est à la fois dans une zone et dans une région, qui sont 2 découpages différent de la France en secteur.
On n’utilise pas de Capacité Premium pour cet article, seul un compte d’essai suffit. Dans un workspace on va créer nos ressources de stockage, à savoir un lakehouse et un warehouse.
Le but étant de pouvoir filtrer sur le type de géographie, puis sur le secteur souhaité et d’avoir un classement des personnes du secteur filtré suivant leur score sur chacun des produits.
Alimentation du Lakehouse
Dans le lakehouse on importe nos fichiers manuellement. On pourrait utiliser un pipeline de recopie à partir d’un storage cloud, ce qui est décrit dans l’article https://blog.atawiz.fr/microsoft-fabric-data/ mais dans le cadre de cet article on simplifie les choses.
Nos données sont maintenant sur OneLake et nous resterons sur Fabric et OneLake jusqu’à la restitution des données lors de la publication du rapport où nous pourrons partager le résultat de façon contrôlée avec une bonne gestion des accès.
Une fois les fichiers chargés, on souhaite travailler de façon plus structurée en créant des tables (sous format Delta). On peut le faire automatiquement à partir des fichiers, en prenant garde au typage des colonnes.
Alimentation du Warehouse
Afin de se rapprocher d’une gestion industrialisée du parcours de la donnée, on pousse les données dans un warehouse. Dans un contexte plus réel, on pourra retrouver des étapes de nettoyage ou de déduplication de la donnée par exemple. Ici on se contente de copier les données du lakehouse au warehouse, via un pipeline Data Factory et des activités de Copy.
On peut utiliser la fonctionnalité « Use copy assistant » plutôt que de configurer soi-même l’activité de Copy.
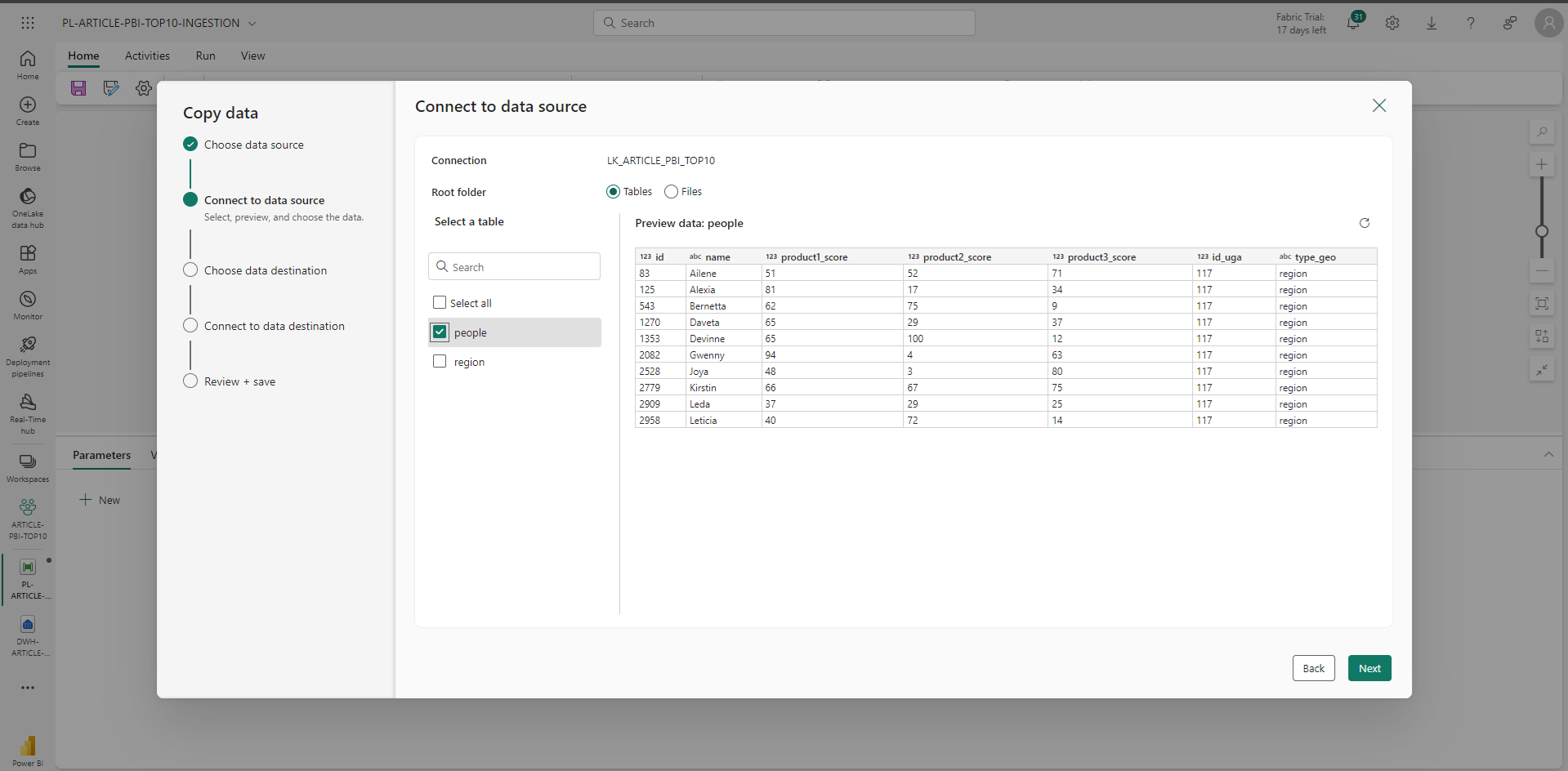
Via un wizard, on configure la source et la destination avec une preview des données.
Fabric propose directement un mapping dans le cas où la table de destination d’existe pas (ce qui est notre cas).
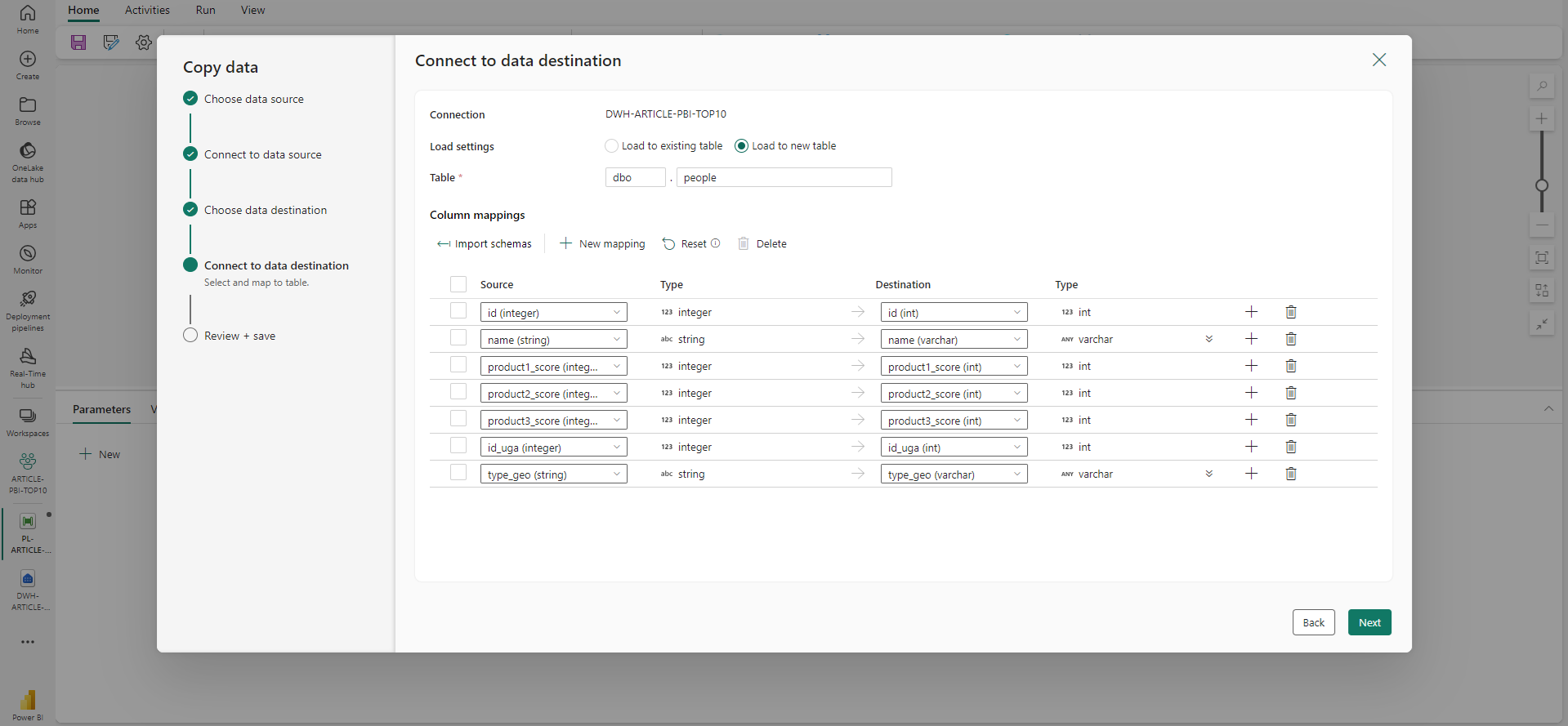
Avec ce formulaire on peut faire l’ingestion des 2 tables d’un coup, ce qui créera une activité de boucle autour le liste des tables sélectionnées et exécutera la copie à chaque tour de boucle. Sauf cas où le nombre de table est conséquent, il est préférable de le faire séparément pour chaque table. Ainsi on contrôle l’ordonnancement et la parallélisation ou non de chacune des alimentations, ce qui donne plus de flexibilité ainsi qu’un monitoring facilité.
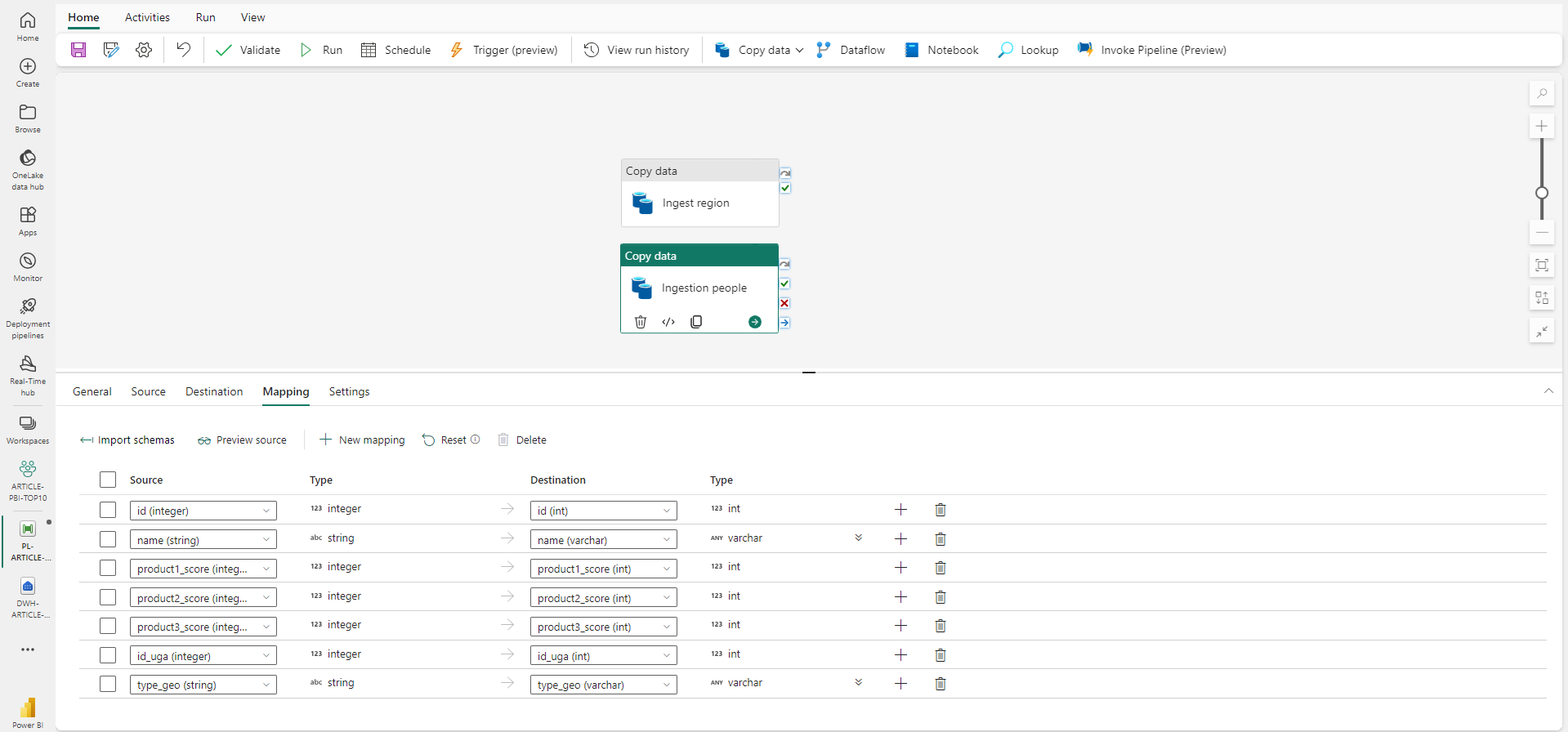
Une fois le pipeline sauvegardé et exécuté on retrouve bien nos tables et nos données dans le warehouse.
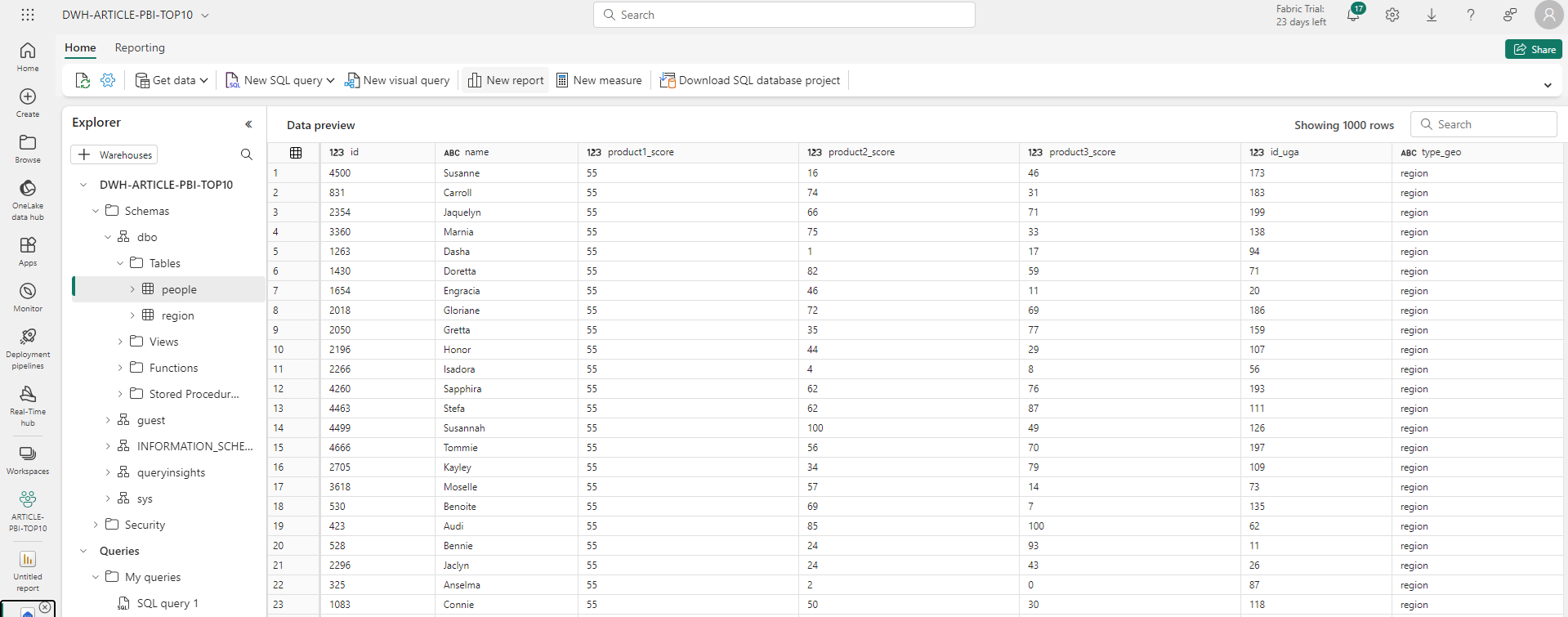
Connexion du rapport aux données
Le mode de connexion le plus populaire est le mode Import. Dans ce mode, les données utilisées par le rapport sont directement contenues dedans. Cela diminue les temps de chargement une fois le rapport chargé, mais augment le poids du rapport, et donc le chargement initial du rapport. Il est donc à conseillé uniquement sur des modèles contenant peu de données.
2 autre modes de connexion sont possibles, permettant au rapport de requêter les données lorsqu’elles sont nécessaires. Comme cet article vise la simplicité et le cas le plus courant, nous resterons sur le mode import et ne détaillerons pas plus les autres modes ici.
Afin de créer un rapport en mode import, il faut quitter Fabric pour travailler sur Microsoft Power BI Desktop. On se connecte aux données via OneLake datahub et dans notre cas en sélectionnant notre warehouse. On valide en sélectionnant « Connect to SQL Endpoint ».
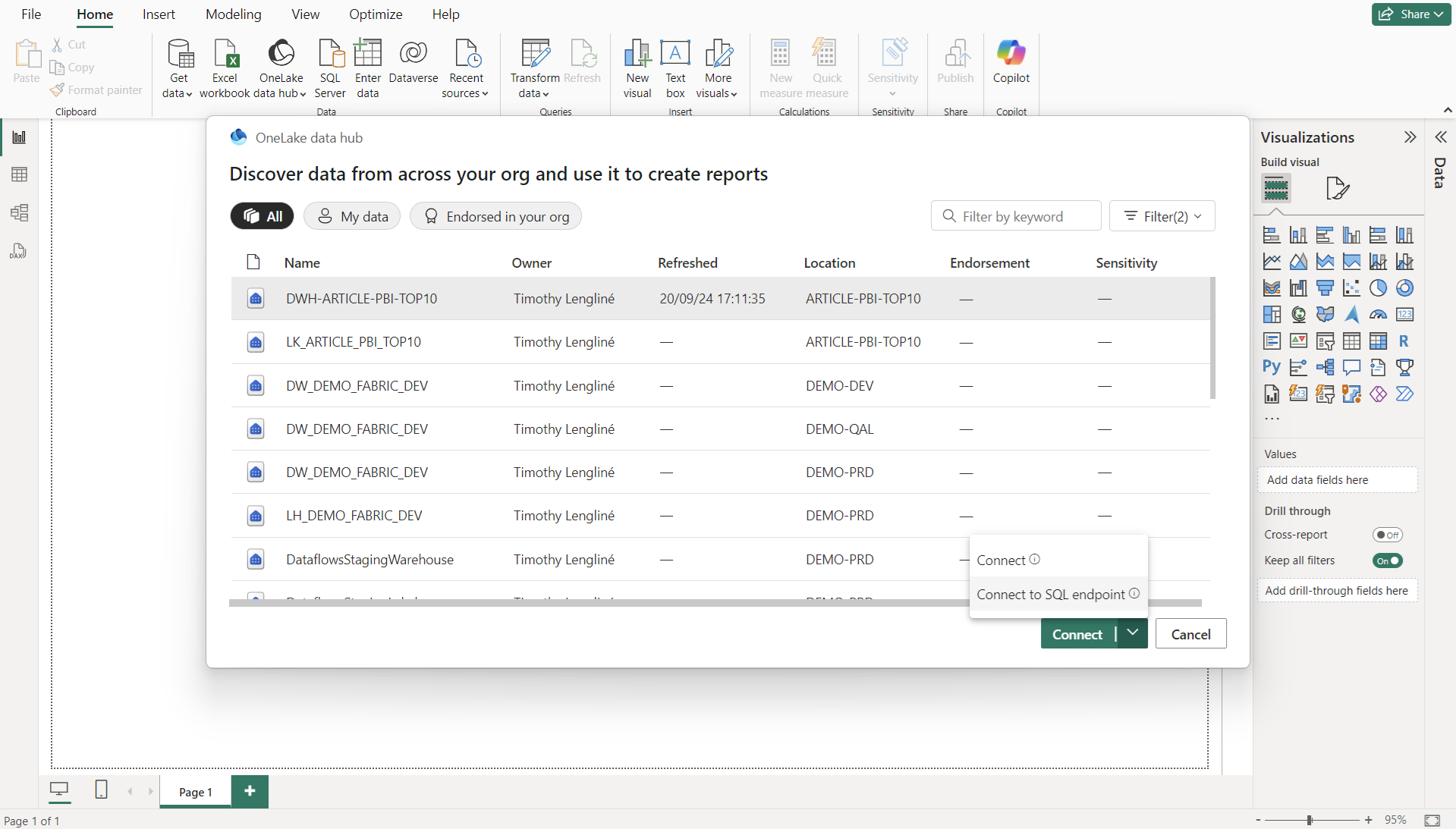
Cela permettra de pouvoir choisir les tables et en cliquant sur Transform data, d’avoir le choix du mode de connexion et donc pouvoir accéder à la transformation du modèle dans Power BI Desktop.
Gestion du modèle sémantique
Dans la partie « Transform data » on obtient bien nos 2 tables, et afin d’avoir d’une colonne de jointure entre nos tables satisfaisante pour ce qu’on souhaite faire, on va créer une nouvelle colonne. Pour ça, dans l’onglet « Add Column » et en sélectionnant les colonnes id_uga et type_geo, on peut les concaténer (fonctionnalité « Merge Column » (on fait cela sur les 2 tables)
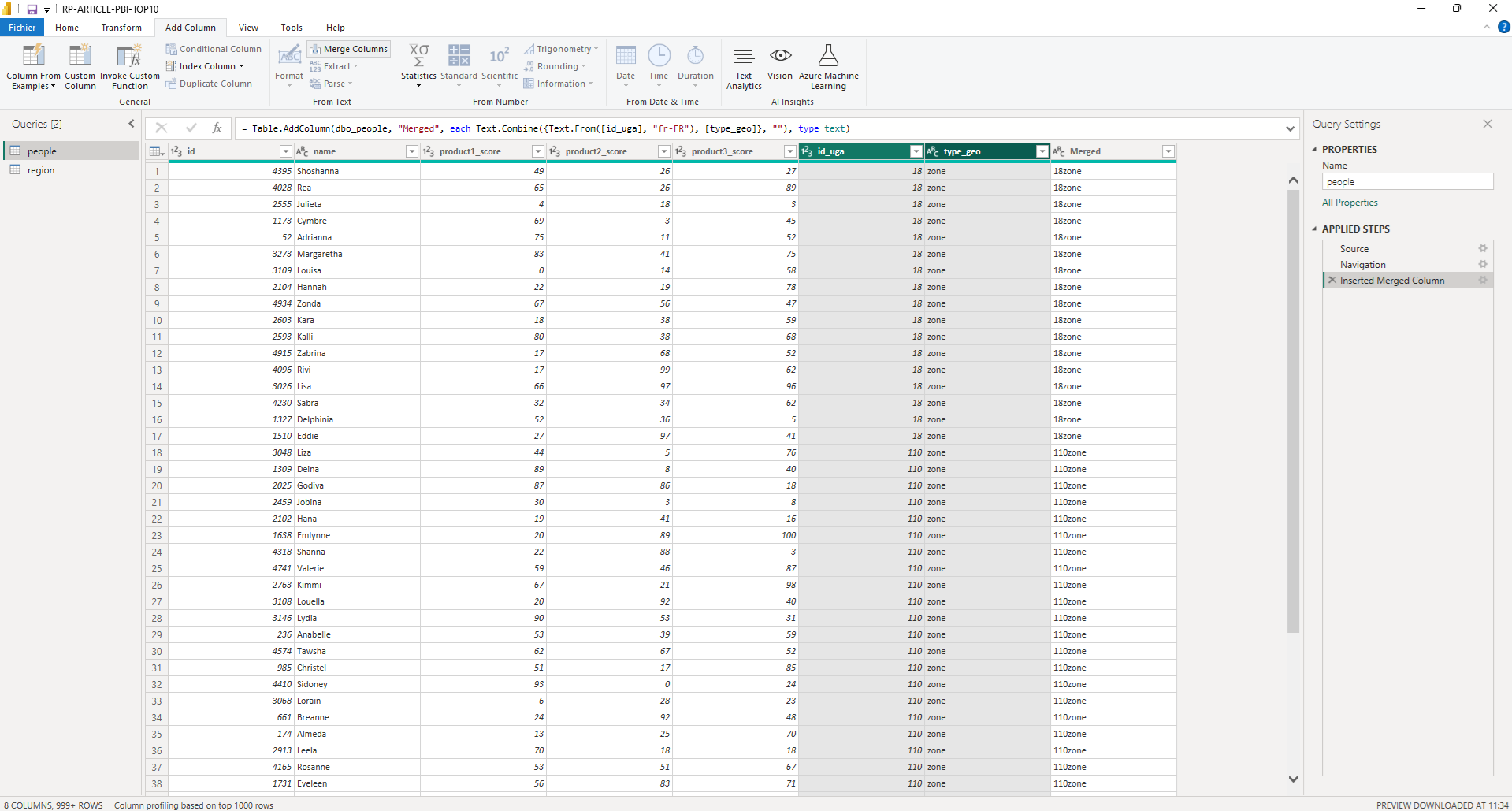
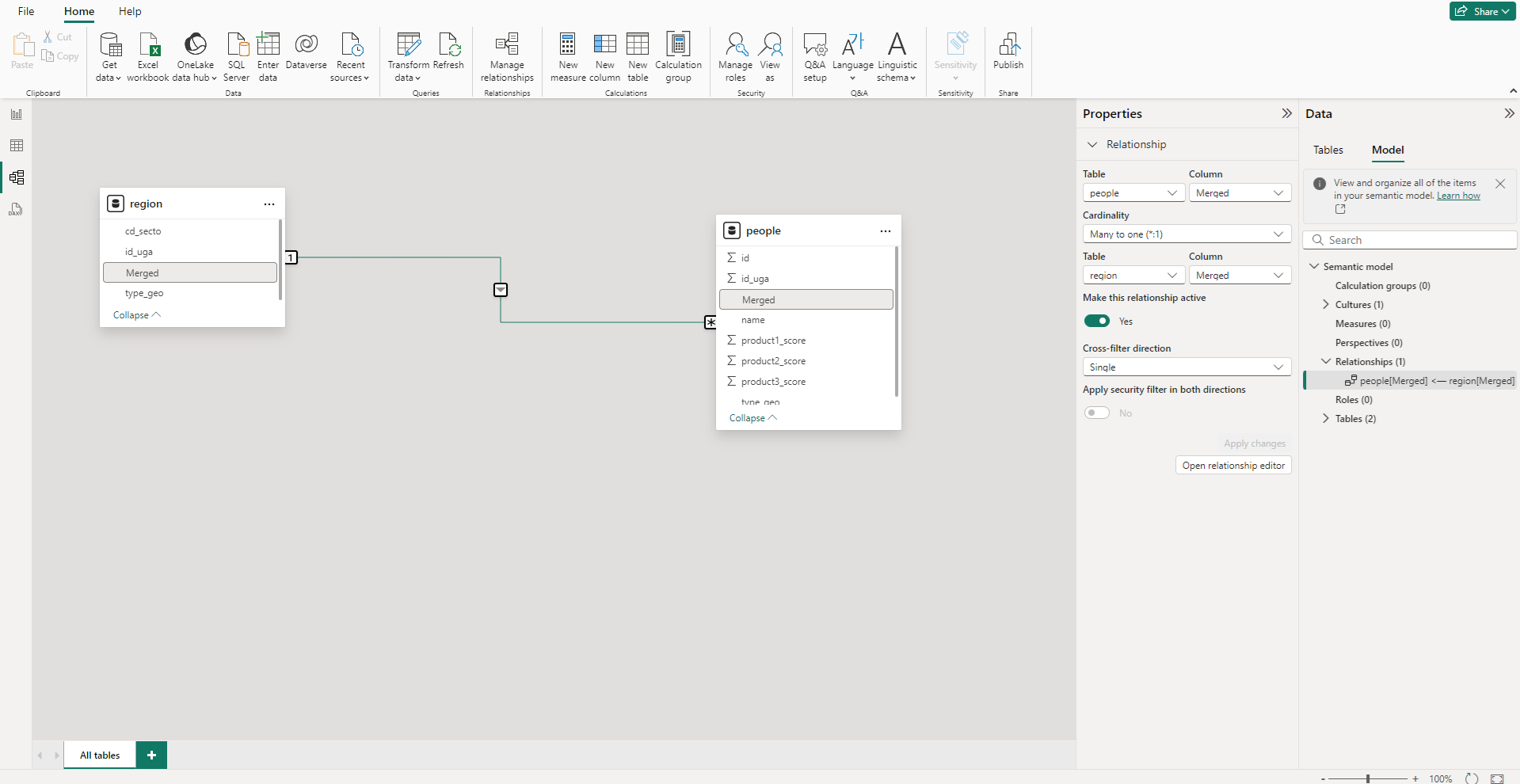
Une fois les modifictions appliquées, dans le panneau « Model view » on peut faire le lien entre nos tables (si il n’a pas déjà été fait automatiquement par Power BI) entre nos 2 nouvelles colonnes en faisant un drag&drop. La relation est un OneToMany pour que la région puisse filtrer les personnes.
Création des filtres
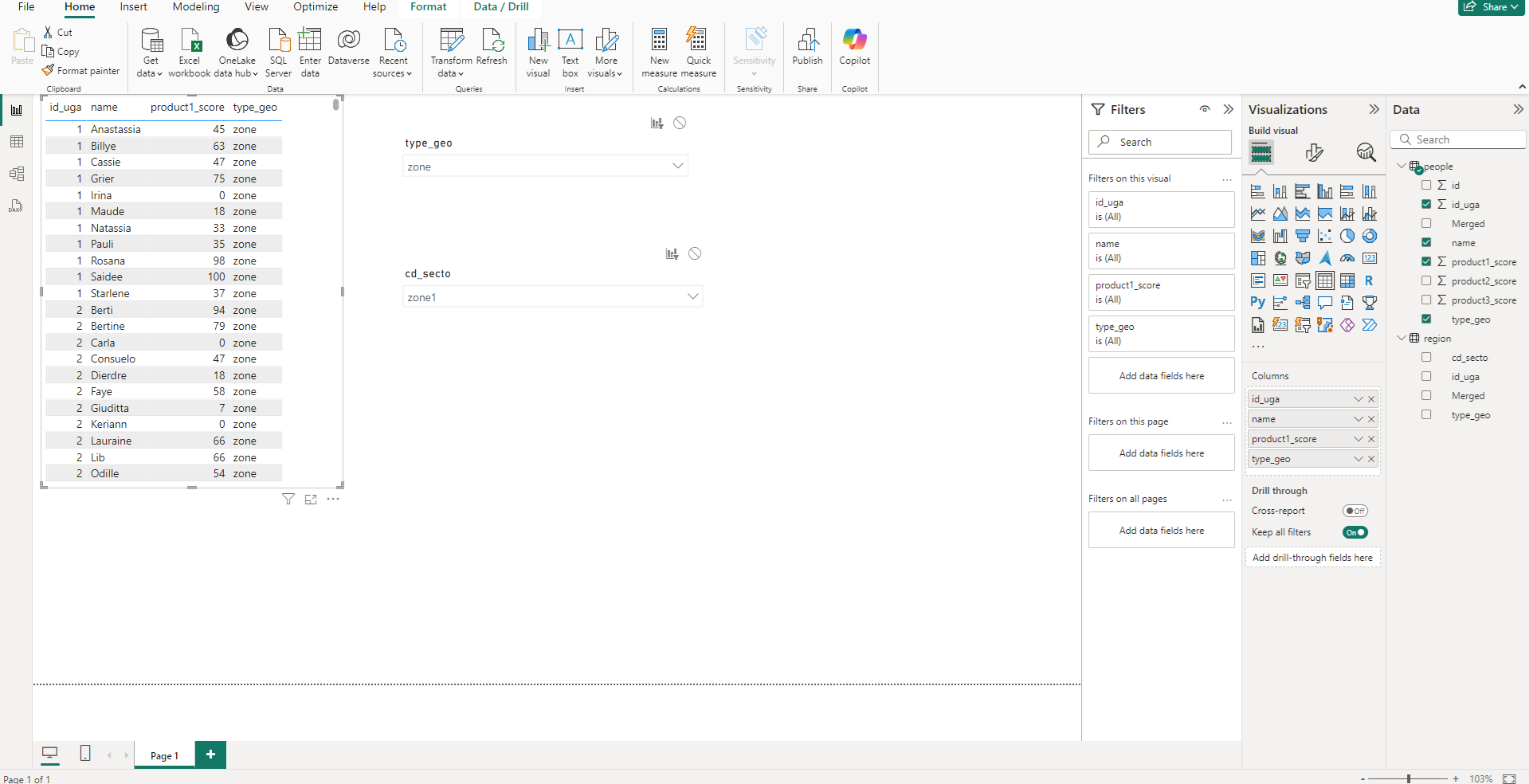
On commence par créer une table les données des personnes afin de contrôler que nos filtres fonctionnent.
On crée ensuite 2 slicers, le premier sur le type_geo de la table région, et le second sur cd_secto de la table région.
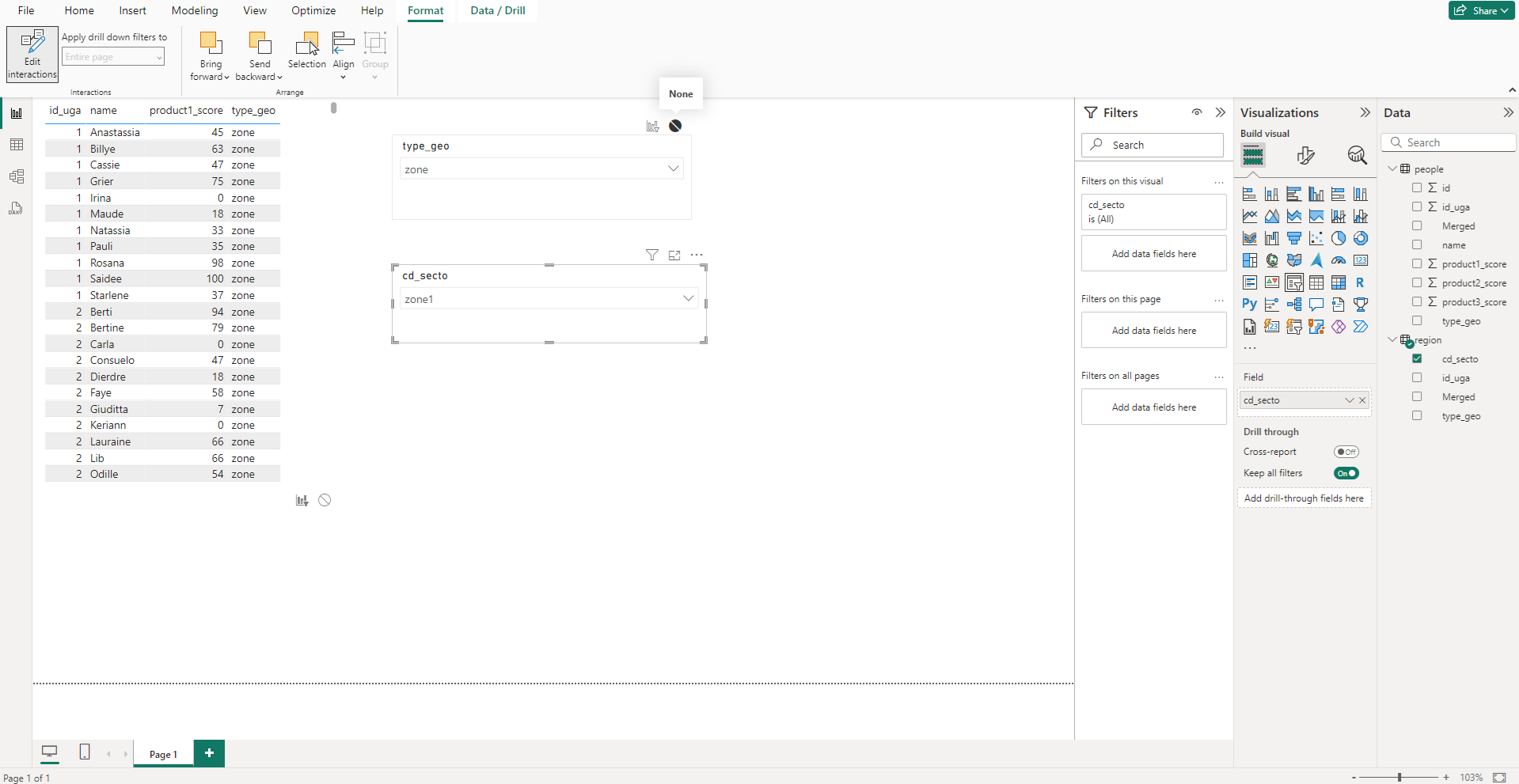
Cela fonctionne mais une fois le secteur choisi, on n’a plus de choix sur le type de géographie, car le second filtre à filtrer les personnes mais aussi le premier slicer. On souhaite donc que le second filtre n’affecte pas le premier. Pour cela on sélectionne l’onget Format, puis l’option « Edit interactions ». De nouvelles icones apparaissent maintenant autour des visuels, en les cochant on informe que le visuel sélectionné ne doit pas impacter le visuel coché. Ici on sélectionne le second filtre et on coche le premier filtre.
Création des mesures et du classement
Les 2 grands types d’ajout à une table sont les mesures et les colonnes calculées. Les colonnes calculées peuvent être vu comme une colonne dont les valeurs sont statiques, qui aurait pu être ajouté au niveau de la source de données. Les mesures sont quant à elle dynamiques, elles sont recalculées en permanence dépendamment du contexte.
Dans notre cas, on aurait pu faire un classement des personnes de façon global, sans prendre en compte les divisions géographiques dans une colonne calculée, car ce classement ne change jamais. En revanche pour avoir un classement qui se modifie aux changements de filtre, il nous faut des mesures.
On crée 2 mesures, une pour chaque produit dont on veut le classement, avec la requête DAX ci-dessous. On pourrait la traduire par : on veut le rang (RANKX) avec une agrégation sur les noms, donc pas d’agrégation dans notre cas (ALLSELECTED(people[name])), sur la base de son score (CALCULATE(MAX(people[product1_score]))). Ici MAX est présent car la formule RANKX prévoit une agrégation. Dans notre cas il y a autant de groupe que de personnes donc peu importe la fonction d’agrégation utilisé nous devrions avoir le même résultat.
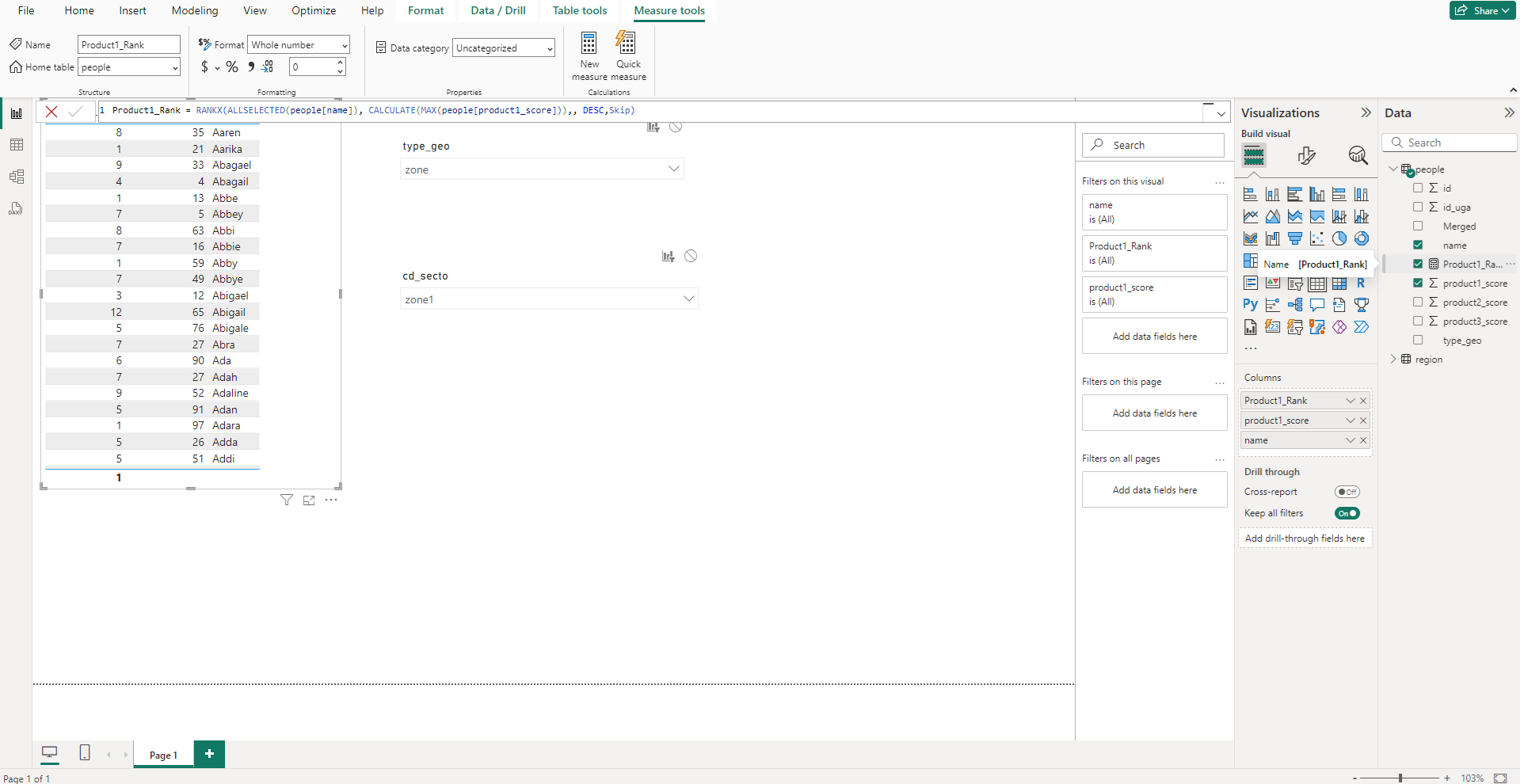
En n’ajoutant que le nom et le rang (la nouvelle mesure) dans la table, on obtient le résultat souhaité en triant sur la colonne du rang.
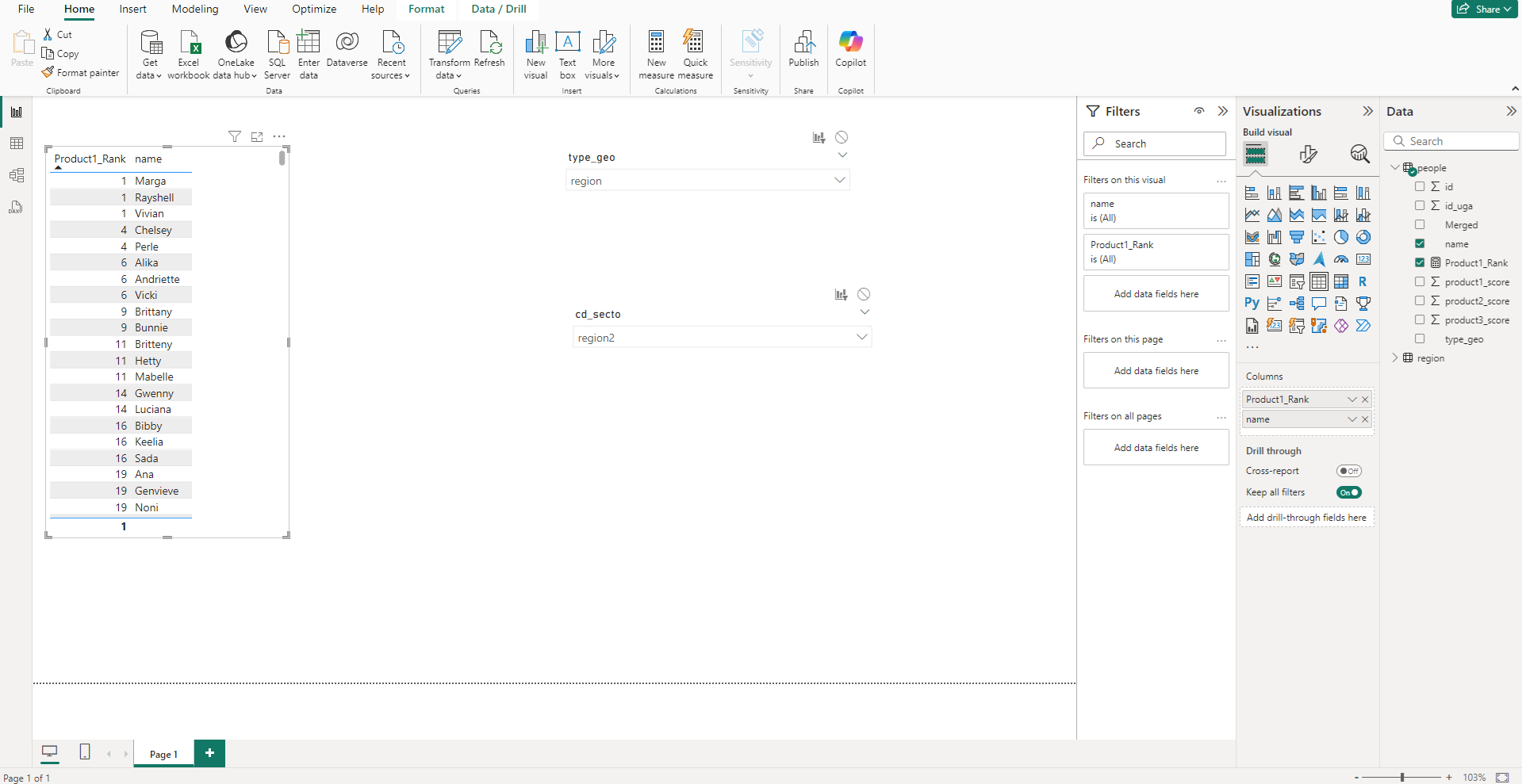
Pn fait de même pour le produit 2, on crée la même mesure en changeant la colonne utilisée pour le classement, et on crée une nouvelle table qui utilise cette nouvelle mesure. Pour avoir un rendu plus digeste, on peut ajouter sur nos tables un filtre pour n’avoir que les X premiers du classement (ici les 30 premiers)
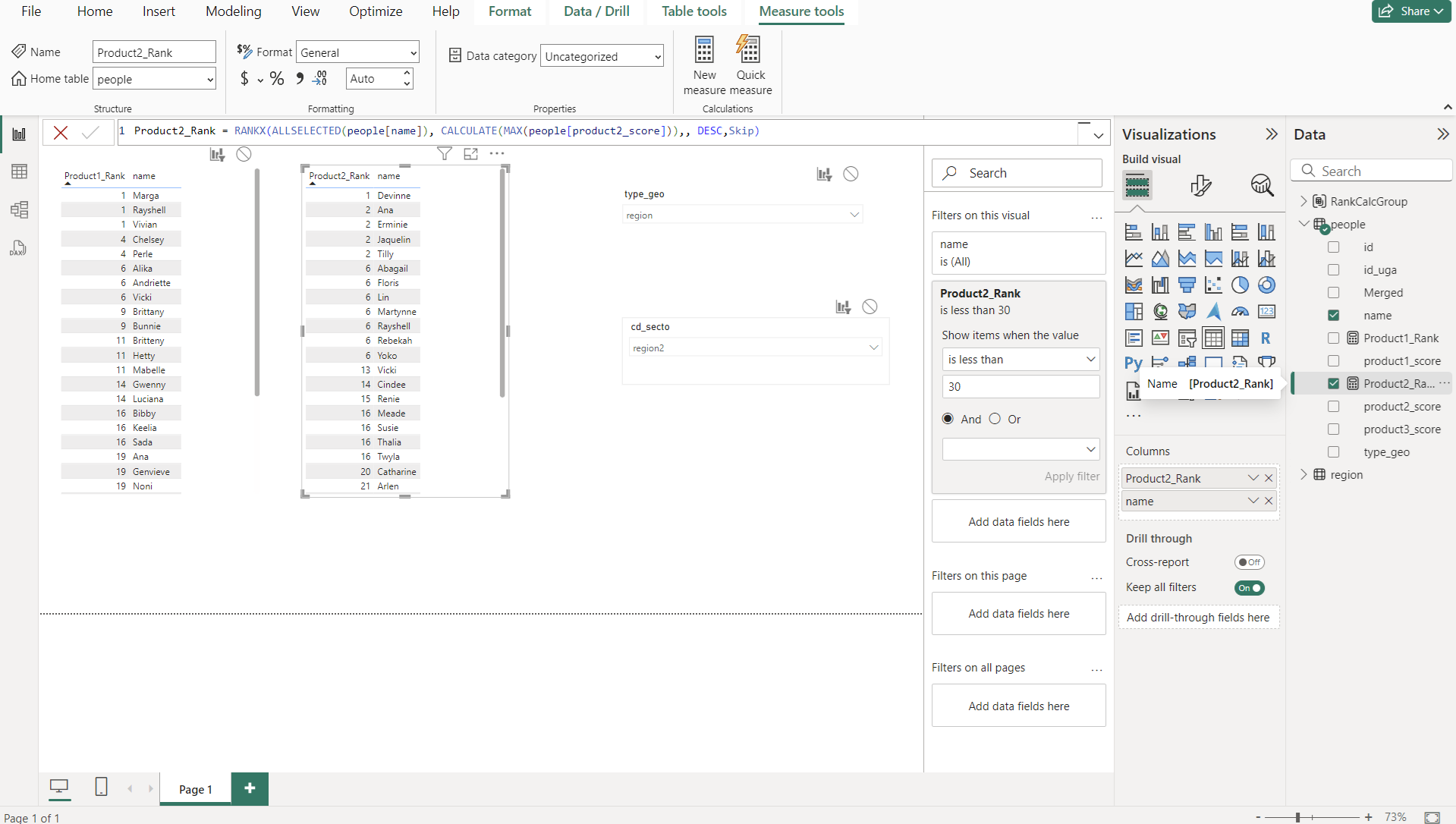
Création du groupe de calcul
Dans l’optique de présenter une nouvelle fonctionnalité, on va maintenant ajouter un groupe de calcul. D’ordinaire ce genre de fonctionnalité a plutôt sa place dans des rapports avec de nombreuses mesures, surtout avec des agrégations à plusieurs niveaux temporelles (calculs aux mois, aux trimestres, à l’année). Les groupes de calculs permettent de ne gérer le calcul de la mesure qu’une seule fois et de laisser Power BI appliquer ce calcul à toutes les mesures, suivant le contexte.
Cette fonctionnalité st très puissante mais dans un souci de simplicité nous allons l’utiliser pour un cas non-réaliste qui aurait pu être fait autrement sans groupe de calcul.
L’objectif est de pouvoir alterner entre les 2 classements sur une même table, sans avoir à écrire de DAX, et en laissant le groupe de calcul choisir quelle mesure de calcul de rang utiliser.
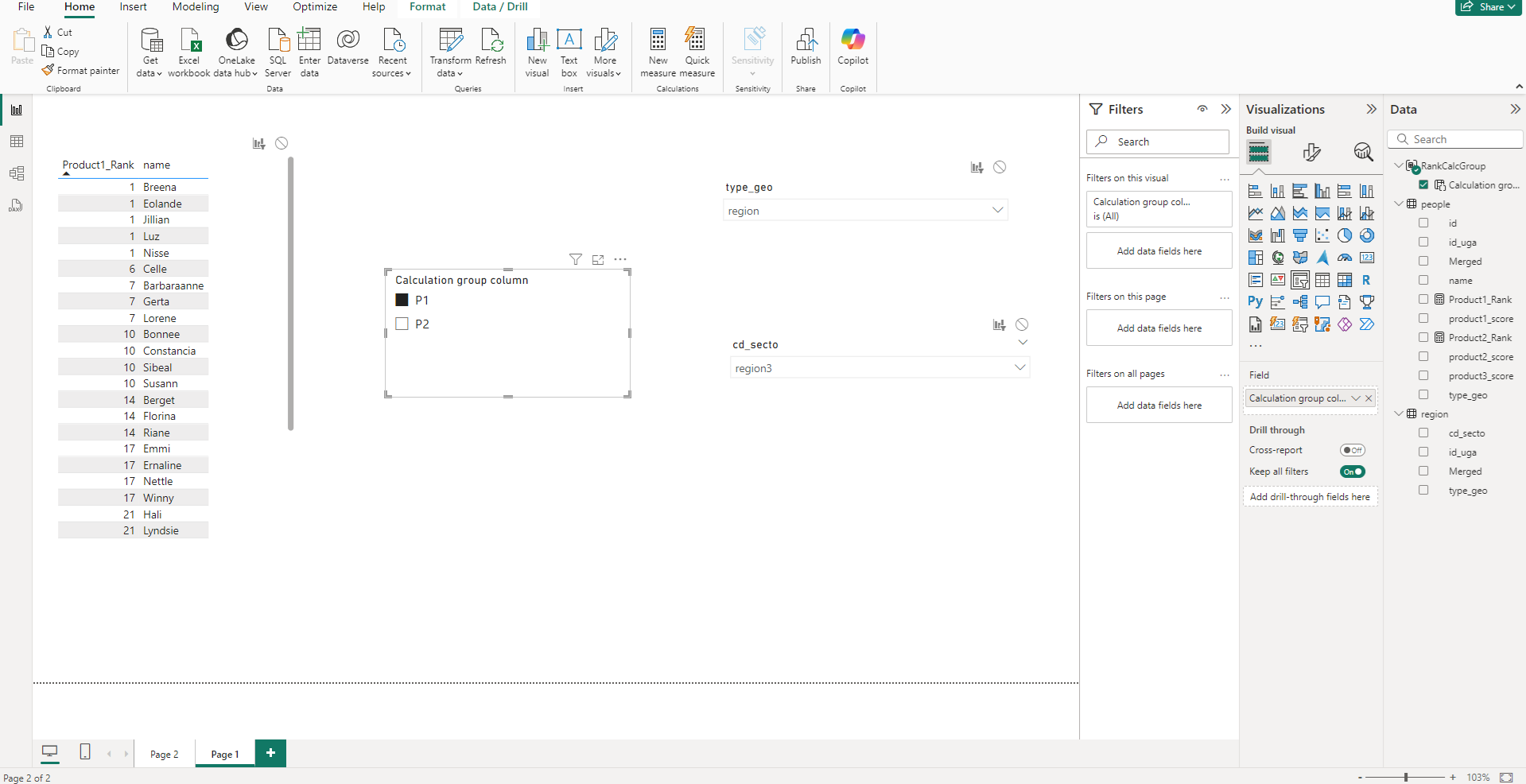
Dans le panneau Model view, sur l’onglet Model à droite, on a la liste des items existants. On peut y ajouter un calculation group (et le renommer), et créer 2 calculation items (pour nos 2 mesures de classements). Ces calculations items auront la formule extrêmement simple ci-dessous (l’item est égal à la mesure)
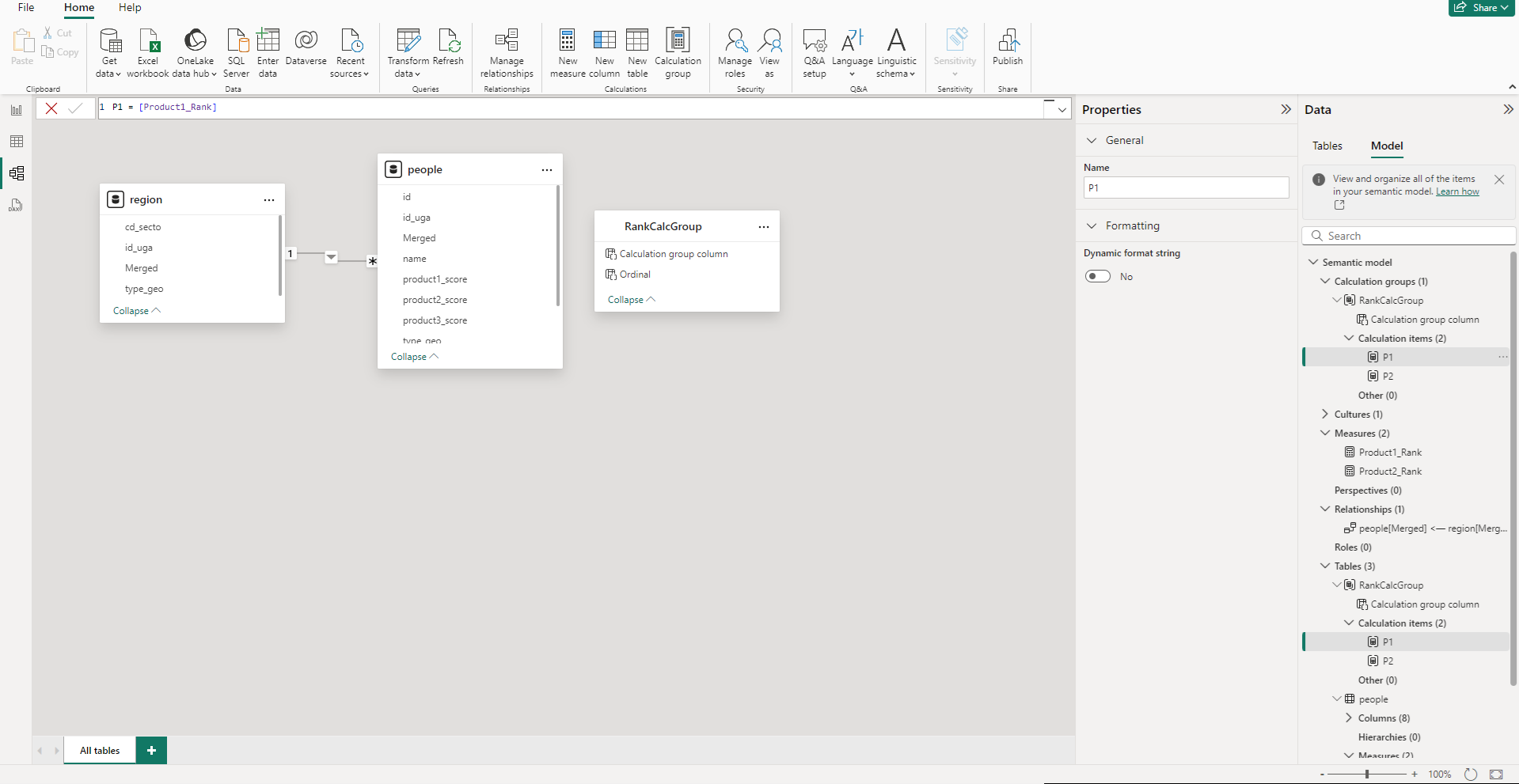
De retour sur le rapport, on peut créer un slicer avec comme valeur le groupe de calcul (les valeurs seront les calculation items), et la table changera automatiquement la mesure de classement utilisée dans notre table.
Publication du rapport
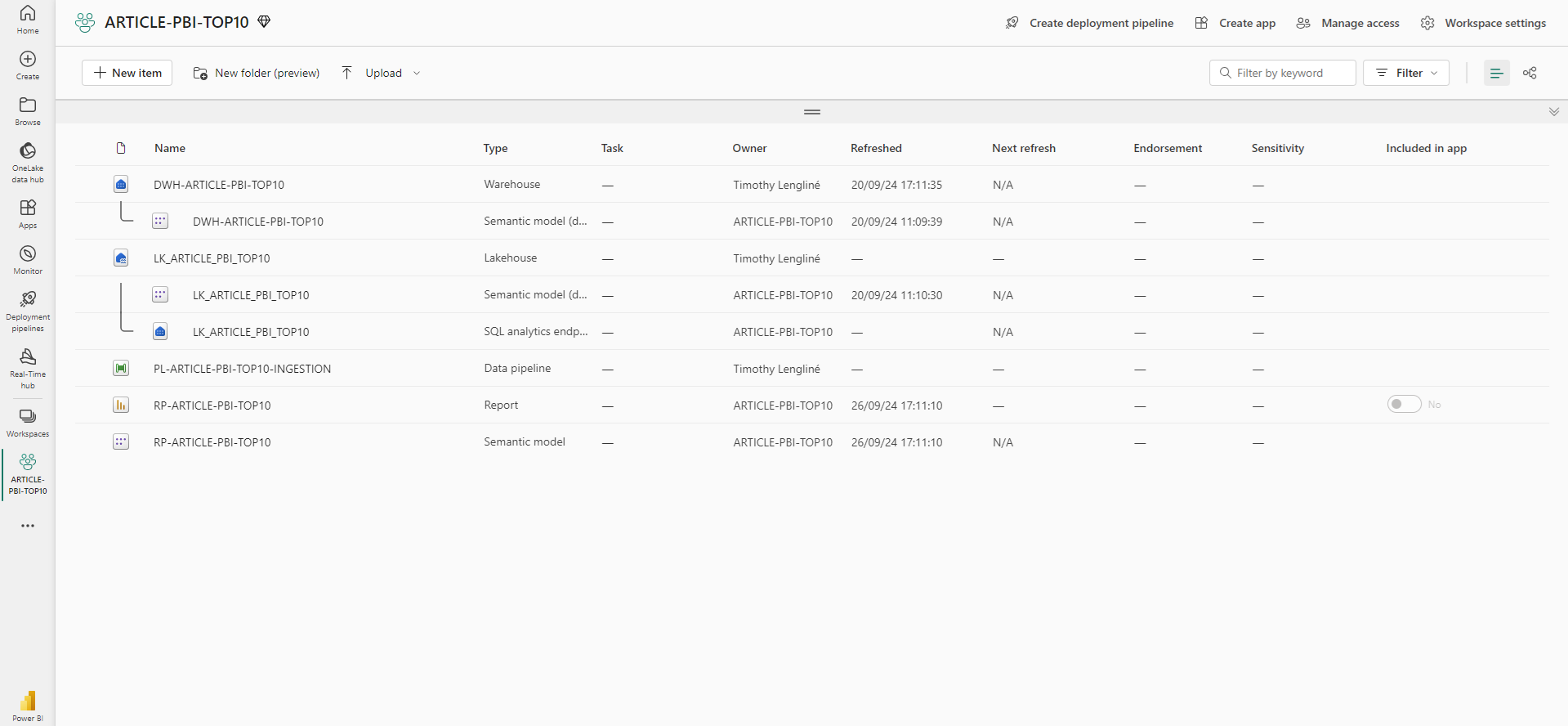
Une fois satisfait du rapport, la dernière étape est de le sauvegarder et de le publier. Dans l’onglet File, on peut cliquer sur Publier le rapport et on choisit dans quel workspace il sera hebergé.

Une fois publié, on le retrouve bien ainsi que son modèle sémantique associé dans le workspace.
Lors de la première publication, il faudra choisir une façon dont le rapport pourra rafraîchir les données. Jusqu’à présent, sur Power BI Desktop, la connexion aux données s’est faite via le compte personnel sur lequel on était connecté. Dans un contexte industriel, il faudrait créer une Gateway, ce qui sera abordé un prochain article.
Sans choix d’authentification de notre part à ce niveau-là, la seule façon de rafraîchir les données est de le faire en local via Power BI Desktop et de publier le rapport à nouveau avec les nouvelles données.
Conclusion
On a vu dans cet article un cas concret d’ingestion de données et de leur utilisation dans un rapport, ainsi qu’une présentation des groupes de calcul. Les prochains articles couvriront les aspects manquant à cet article, à savoir la gestion industrielle d’un rapport partagé.
Les thèmes à approfondir seront donc la gestion des gateways, la création et la gestion d’une application et la gestion des accès.
