Microsoft Fabric, la solution Data tout en un.



Introduction
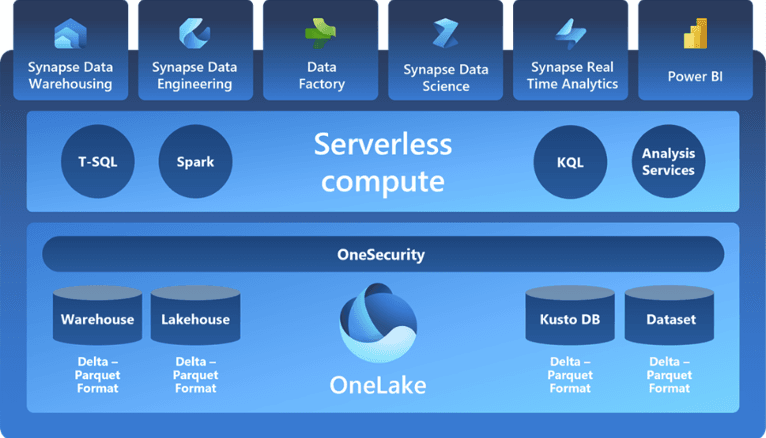
Lors de son évènement annuel Build en mai 2023 Microsoft a annoncé Microsoft Fabric, une solution avec laquelle on peut faire à la fois de l’intégration et du stockage des données, du Machine Learning, et de la business intelligence.
Dans cet article, je vais vous présenter comment créer un Pipeline dans Microsoft Fabric pour lire des données à partir d'un espace de stockage, les transformer en utilisant Dataflow gen2 et Pyspark, et les stocker dans un Lakehouse (OneLake). Ensuite, toujours au sein de Microsoft Fabric, nous verrons comment analyser ces données dans un rapport Power BI.
Prérequis
Pour reproduire les étapes de cet article, il faudra d’abord :
- Une activation du Preview du service
- Une licence de Power BI Pro
Création du Workspace
Un Workspace est un espace de travail dans lequel les utilisateurs peuvent collaborer pour créer des Lakehouses, des Warehouses et des rapports. Il leur permet de gérer l'accès, les paramètres et les activités liées à ces éléments dans un même endroit.
Pour en créer un, je clique sur « Workspace » à gauche dans la page d’accueil’, puis sur ‘’New workspace’’ dans la nouvelle fenêtre.
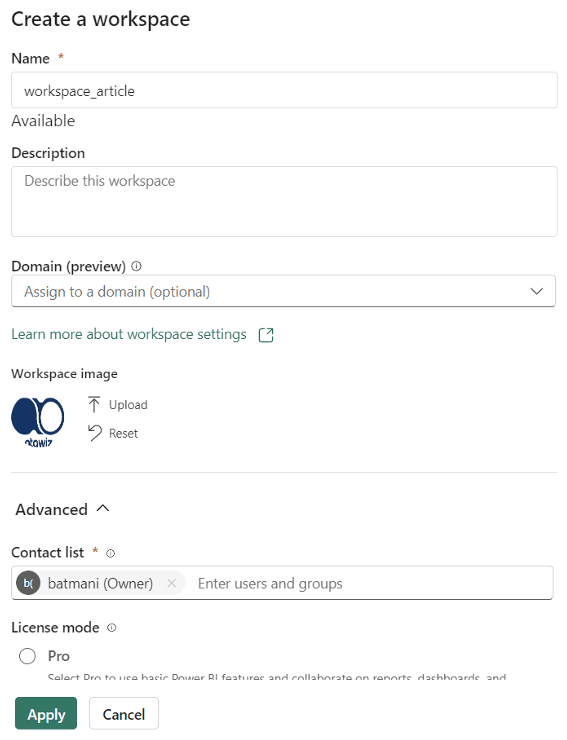
Je saisis les informations de mon Workspace comme indiqué ci-dessous. Une fonctionnalité intéressante est celle liée à l'ajout d'une image. Une autre option encore plus captivante est la capacité de partager l'espace de travail avec d'autres membres.
Création du Pipeline
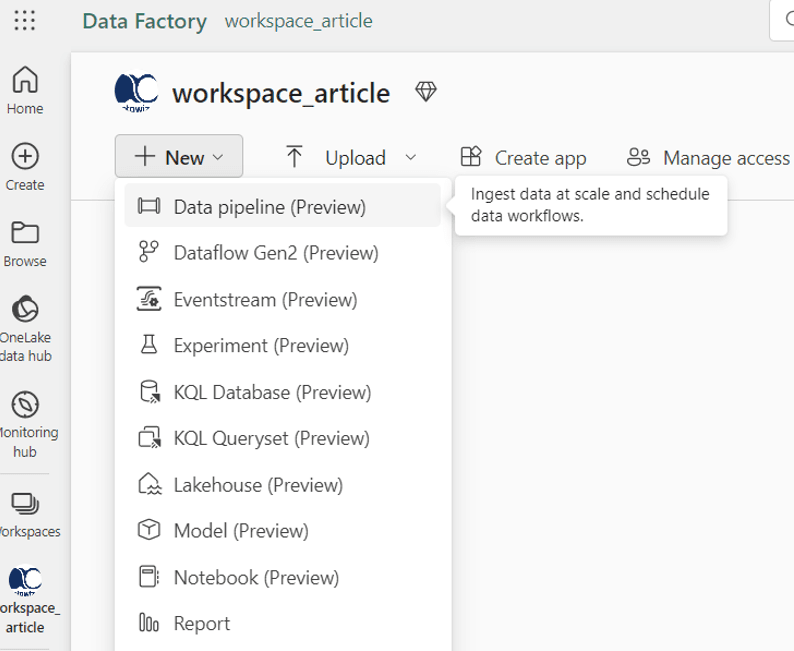
Maintenant je peux commencer à travailler dans mon Workspace ‘’workspace_article’’. Je commence par créer un Pipeline en cliquant sur le bouton ‘’New’’ et en sélectionnant l'option dans le menu déroulant. Je le nomme ‘’pipeline_article’’ :
1. Création de l’activité ‘’Copy’’
Je choisis l’activité ‘’Copy data’’ :
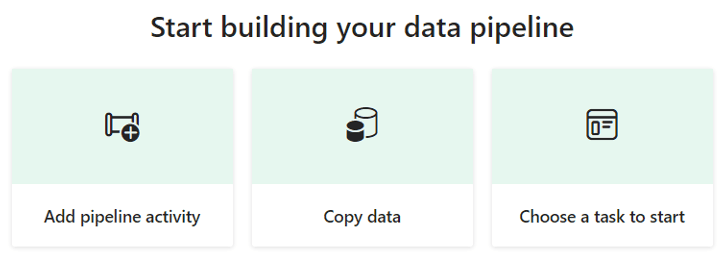
Une nouvelle fenêtre apparaît pour configurer l’activité du Copy. J’ai plusieurs options de connecteurs disponibles. J’ai le choix de filtrer par catégorie ou d’effectuer une recherche pour trouver le connecteur qui me convient. Dans mon cas, les données que je souhaite copier sont sur Azure Data Lake Storage Gen2 (ADLS gen2).

2.Création d’une connexion ADLS :
Maintenant vient l’étape de la connexion entre ADLS et Microsoft Fabric. Ci-dessous les champs requis :
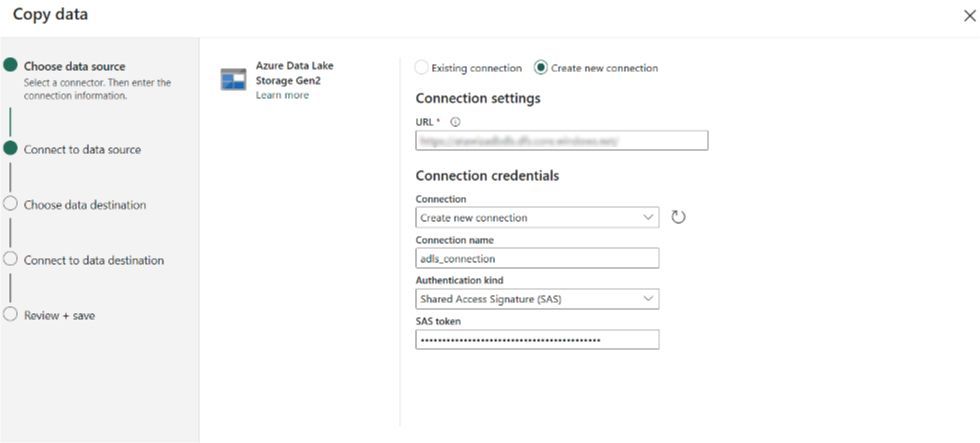
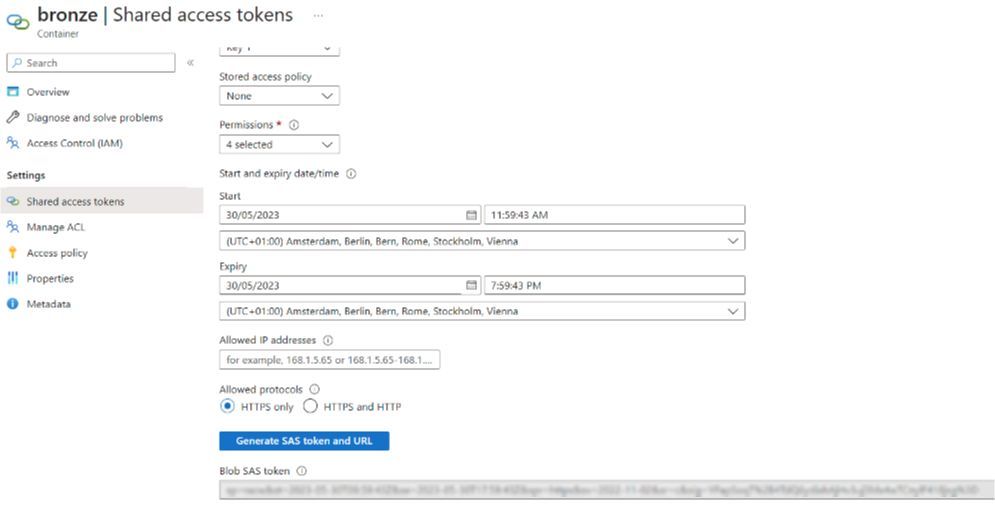
Parmi les types d’authentification, je choisis SAS. Pour cela, je génère un Token depuis le portail Azure :
La connexion que je viens de créer est sauvegardée et peut être utilisée ultérieurement. Elle peut être partagée entre plusieurs Workspaces, voire avec d'autres utilisateurs, un grand atout ! Est-ce que l’on peut donc considérer une connexion comme un produit ?
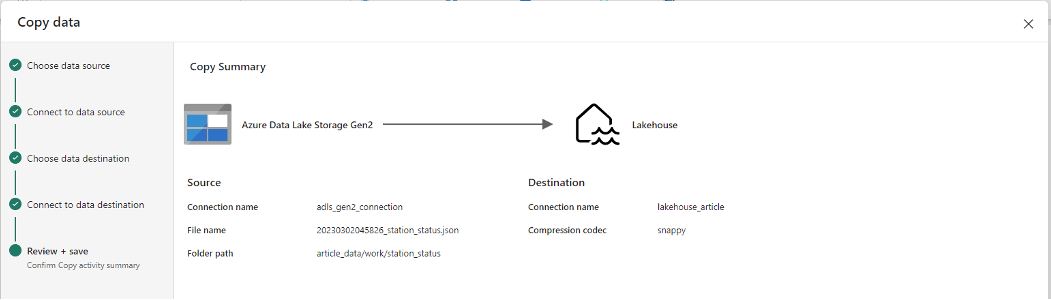
Une fois connecté, je sélectionne les données à copier en format JSON :
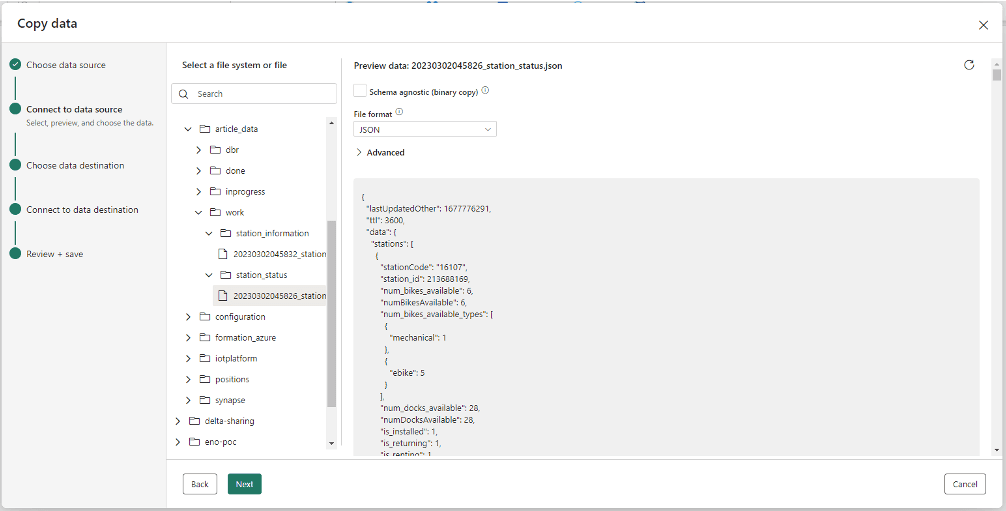
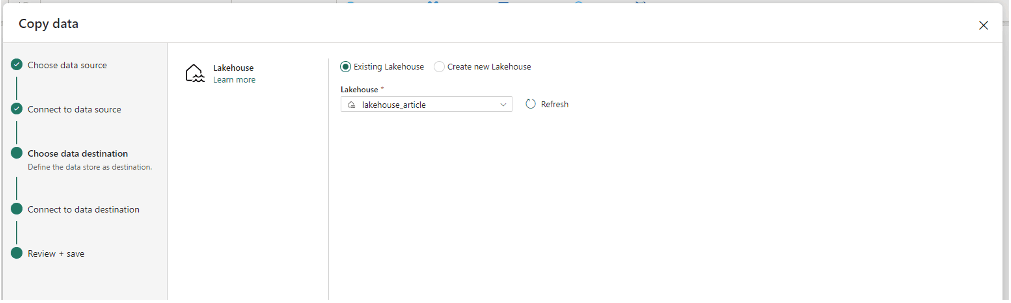
Un large panel de connecteurs de destination est proposé. Je choisis "Lakehouse". Dans l'étape suivante, je sélectionne ensuite "lakehouse_article", un Lakehouse que j'avais préalablement créé :
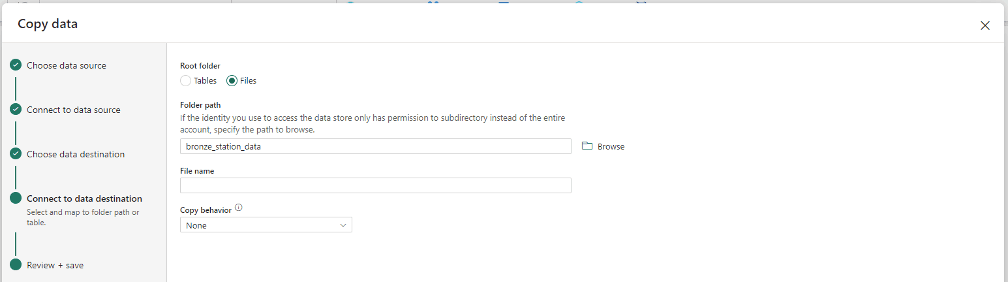
Ensuite, je sélectionne le format de destination pour les données (deux options : table ou fichier). Je décide d'opter pour le format fichier, Parquet. Je copie les données dans un dossier que j'ai nommé "Bronze_station_data". Pour cette ingestion, j'ai en effet choisi de mettre en place trois niveaux (bronze, silver et gold).

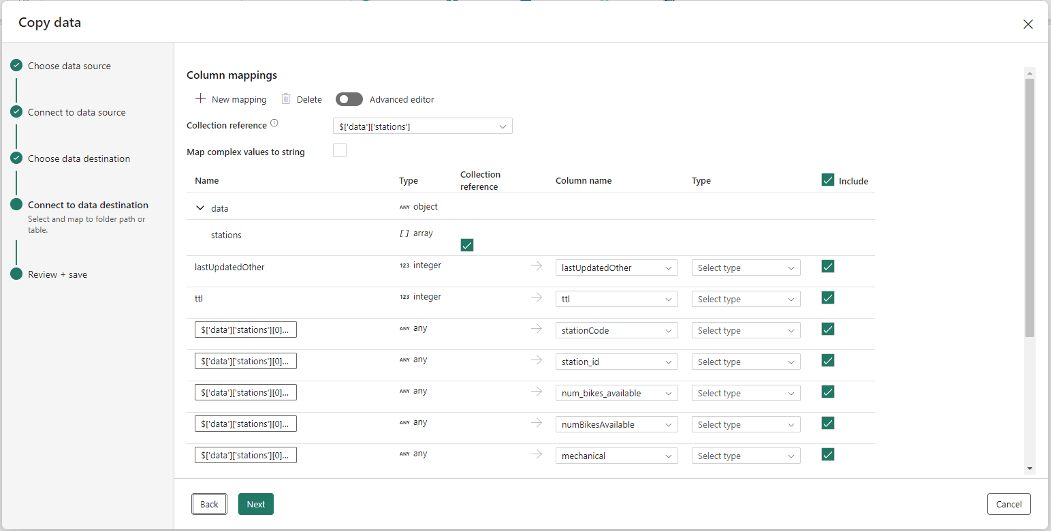
Enfin je paramètre les mapping des colonnes comme ci-dessous :
3.Création de l’activité ‘’Dataflow’’ :
Une fois les données copiées, je souhaite effectuer quelques transformations. Pour cela, plusieurs options s'offrent à nous. Je vais effectuer une première transformation à l'aide d'un Dataflow Gen2 (également en Preview), puis une deuxième transformation à l'aide d'un Notebook Pyspark.
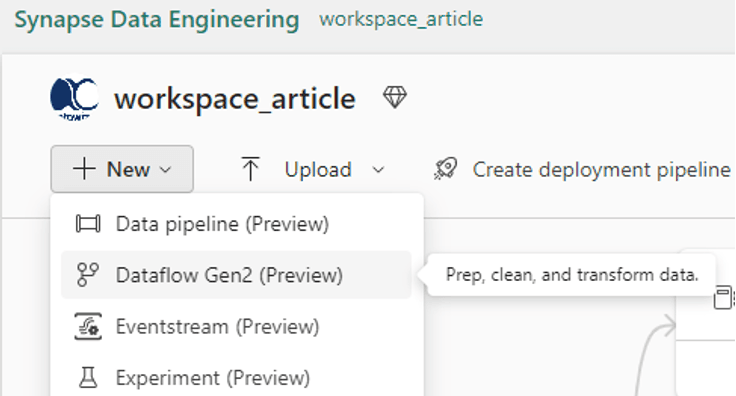
Pour créer un Dataflow je vais sur mon Workspace, puis sur ‘’New’’ comme ci-dessous :
Et je lis mes données depuis mon Lakehouse ‘’lakehouse_article’’
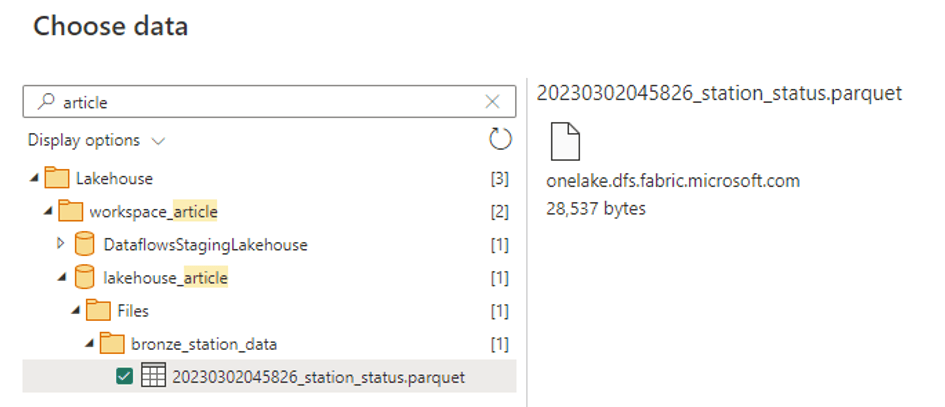
Une fois mes données sélectionnées au format Parquet depuis ma zone "bronze", une fenêtre Power Query s'ouvre. Ceci diffère de ce à quoi nous sommes habitués dans ADF.
Dans cette interface je vais renommer deux colonnes et en supprimer deux autres. Pour cela rien de plus simple : il suffit juste de faire un clic droit sur la colonne en question et de choisir l’action à faire.
À ce stade, je souhaite stocker le résultat des transformations faites dans une table delta. Pour ce faire, il suffit de cliquer sur l’icône ‘’Add data destination’’ et de choisir le chemin vers mes tables Lakehouse :
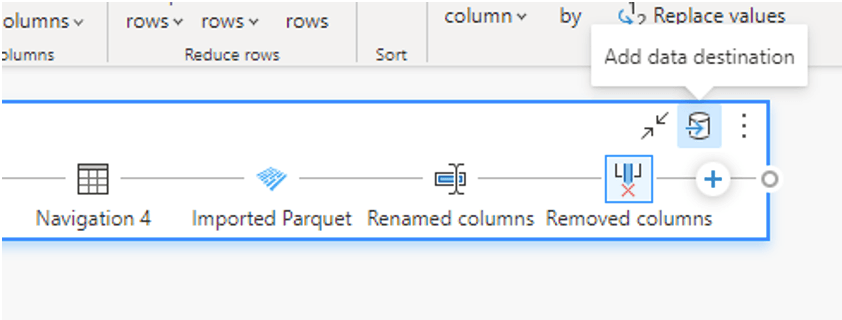
Il est possible à cette étape de choisir de ‘’Append’’ ou de ‘’Remplace’’ avec le nouvelles données. Il est également encore possible de filtrer sur les colonnes souhaitées.

Une fois le Dataflow publié, je le rajoute dans mon Pipeline ‘’pipeline_article’’
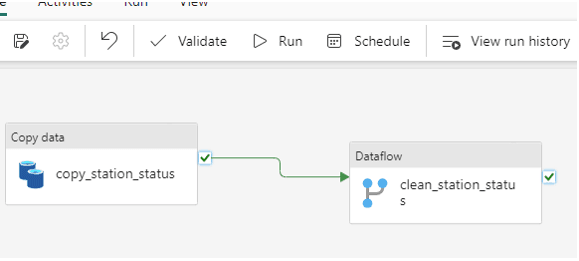

Après exécution du Pipeline, ci-dessous le résultat. Une table Silver :
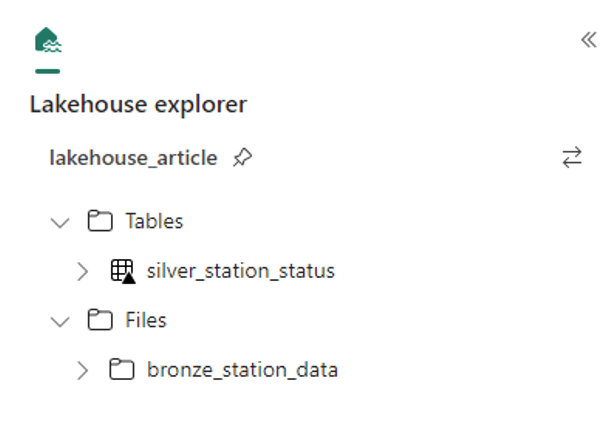
4.Création de l’activité ‘’Notebook’’ :
Dans la prochaine activité Notebook du Pipeline je fais une autre transformation avec Pyspark et je stocke, cette fois-ci, les données dans une table Gold.
Pour lire la table, j’ai le choix de spécifier ou non le nom du Workspace :
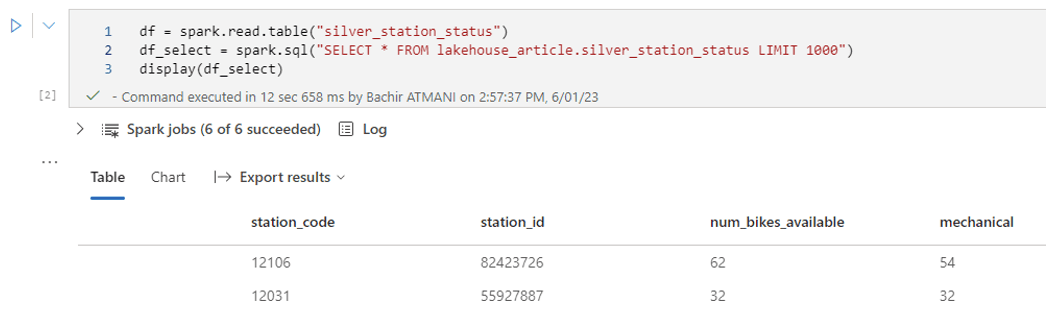
Je souhaite créer une table "gold" qui représente les stations de vélos ayant plus de vélos en réparation que de vélos disponibles à la location. Cela permet de cibler et de mettre l’accent sur les stations qui nécessitent une rapide intervention. Pour cela, je calcule un ratio et je filtre sur les valeurs supérieures à 50%.

Ci-dessous les trois étapes de mon Pipeline :
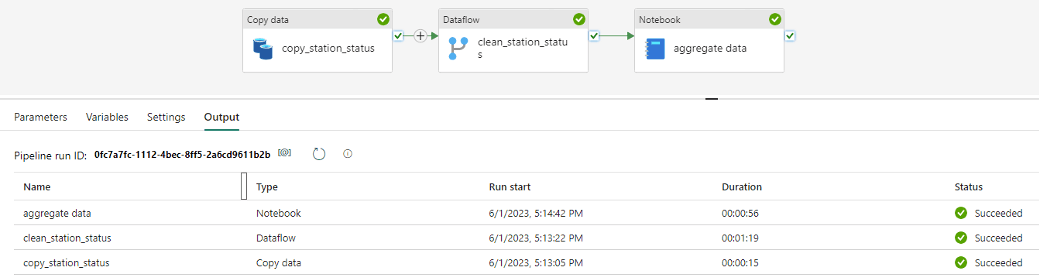
Une fois l'exécution complétée, deux tables sont créées.
En effet, j'ai souhaité observer la différence entre les deux formats, Parquet et Delta, dans Microsoft Fabric.
La table Delta a la particularité d’un petit triangle (encadré en rouge dans l’image ci-dessous), mais également un répertoire de log ‘’_delta_log’’, et donc de bénéficier des avantages offerts par les tables Delta:
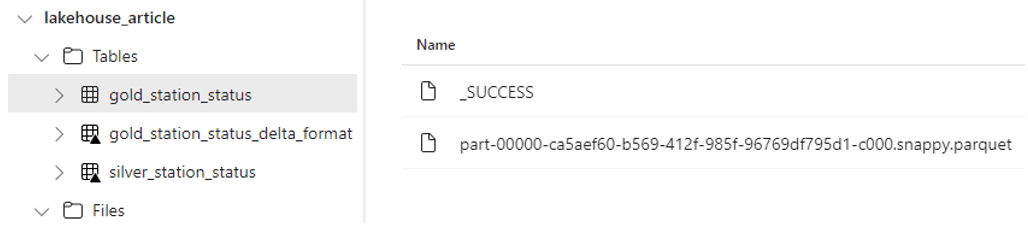
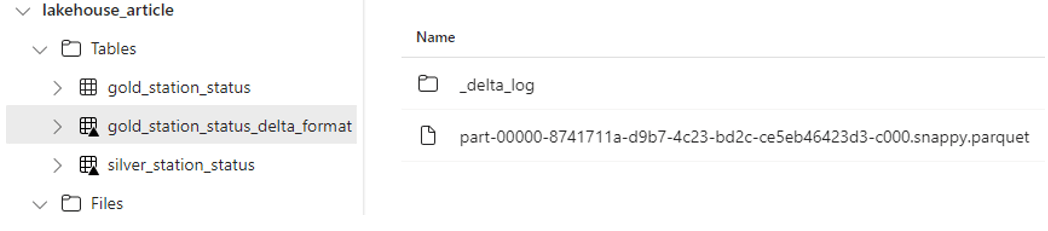
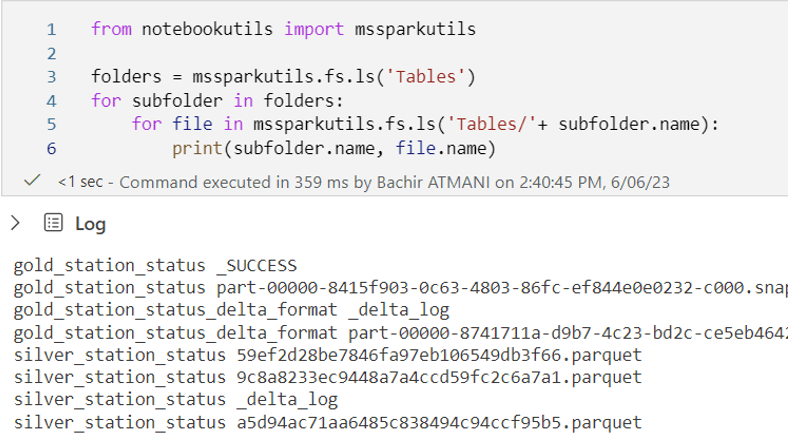
De la même façon j’ai la possibilité, grâce à MSSparkUtils (un package intégré), de consulter le répertoire Table et son contenu comme suit :
DataViz avec Power BI
Afin d'avoir une meilleure visualisation de la table "gold", je crée un rapport Power BI en utilisant le jeu de données. Pour cela, il suffit d’aller dans mon Workspace et de faire un clic droit sur le Dataset :
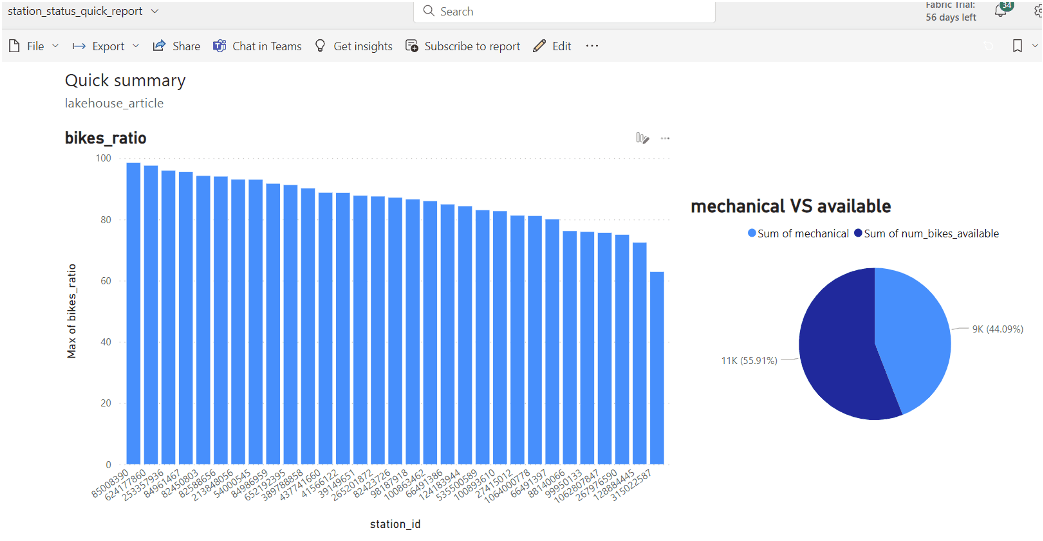
Au total, en dehors des vélos déjà en location, plus de la moitié (56,91%) se trouvent dans des ateliers de réparation.
Certaines stations ont très peu de vélos disponibles pour être proposés à la location. C'est notamment le cas de la station ayant l'ID 85008390, qui ne dispose que de 1,47% de ses vélos disponibles.
Le Lineage
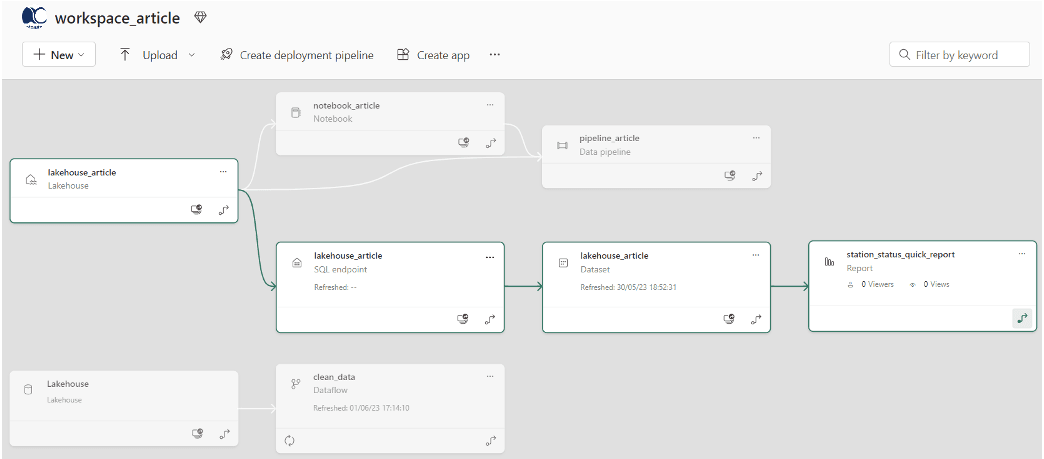
Une autre fonctionnalité intéressante que je trouve dans Microsoft Fabric est la vue Data Lineage. Cette fonctionnalité nous permet de visualiser toutes les dépendances entre les différents composants d'un Workspace.
Cependant, j’ignore la raison pour laquelle le Dataflow "clean_data" n'est pas lié au Pipeline "pipeline_article" comme l'est le "notebook_article". A explorer !
Conclusion
Microsoft Fabric est une plateforme analytique SaaS regroupant plusieurs outils de données et d'analyse en une seule suite. Elle facilite l'extraction d'insights à partir des données et leur présentation.
Un pilier clé de Microsoft Fabric est Microsoft OneLake. Ce lac de données centralisé basé sur Apache Parquet élimine les silos de données tout en simplifiant le stockage et la récupération des données.
Fabric offre des fonctionnalités avancées telles que l'intégration de l'intelligence artificielle générative (Copilot sera également intégré) et la prise en charge multi-cloud avec les Shortcuts (objets dans OneLake qui pointent vers d’autres emplacements de stockage) qui permettent une connexion aux sources de données comme Azure ou AWS.
L’ensemble de ces fonctionnalités peut rendre Microsoft Fabric attrayant pour les entreprises recherchant simplicité et rapidité d'utilisation.
