Introduction à dbt sur Microsoft Fabric



Qu'est-ce que dbt
Data Build Tool (dbt) est un outil de data engineering, facilitant la fiabilité de toute la chaine d’ingestion et de traitement des données.
Le gain en qualité de donnée provient de plusieurs facettes de dbt :
Toute la modélisation, les traitements, les tests unitaires, la documentation, etc. sont concentrés dans l’outil, sous forme de simples fichiers SQL ou YAML. Cela permet une maintenance claire, et un versionning simplifié.
dbt est intégrable dans la plupart des outils Cloud, comme Azure Synapse, Microsoft Fabric, Databricks ou Snowflake par exemple. Les migrations d’un environnement à l’autre consistent donc presque uniquement à modifier le fichier de configuration pour y modifier les chaînes de connexion et tout le projet fonctionnera à nouveau sur le nouvel environnement.
Une version Cloud existe également pour permettre une collaboration entre membres d’une équipe directe, une gestion du versionning, de la documentation ou même de l’intégration native avec les environnements Cloud (BigQuery, SnowFlake, Synapse, etc…).
Dans cet article nous n’aborderons que dbt Core, qui nécessite de travailler en local et non pas sur un IDE en ligne. La plateforme de data warehousing choisie pour cet article est Microsoft Fabric, qui peut s’utiliser avec un compte Trial gratuit.
Installation
Afin de faire tourner dbt en local, sur Windows, connecté à Microsoft Fabric, plusieurs installations sont nécessaires :
Une version de Python comprises entre 3.7 et 3.11 : https://www.python.org/downloads/windows/
L’extension dbt Power User de VS Code (nous utiliserons VS Code comme IDE)
Le driver ODBC Driver for SQL Server : https://learn.microsoft.com/en-us/sql/connect/odbc/download-odbc-driver-for-sql-server?view=sql-server-ver16
Une fois les outils installés, on peut créer (et activer) notre environnement virtuel, et y installer la bibliothèque dbt-fabric avec les commandes suivantes :
python -m venv dbt_venv
.\dbt_venv\Scripts\Activate.ps1
pip install dbt-fabric
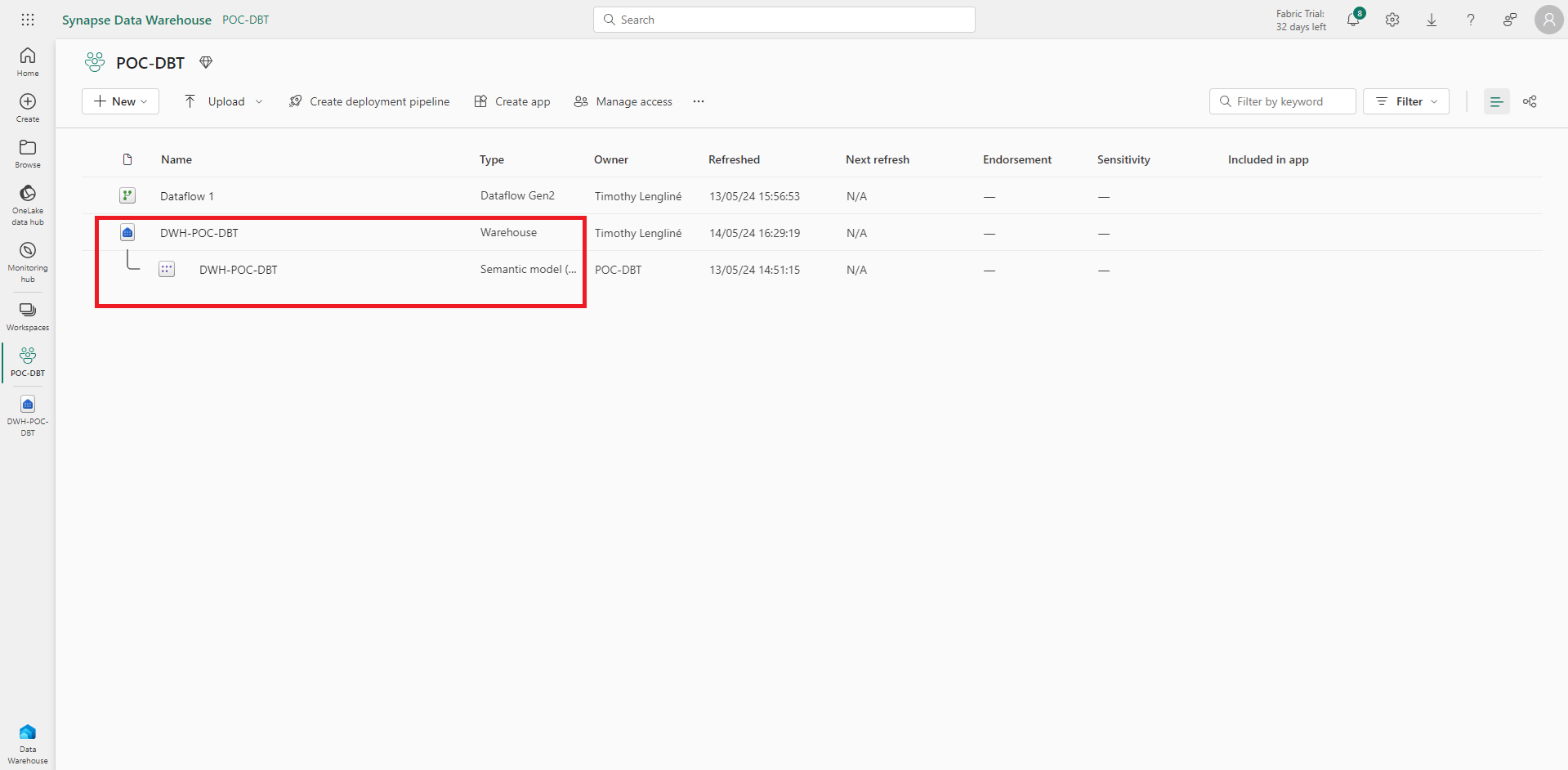
Coté Microsoft Fabric, le data warehouse cible doit être créé afin de pouvoir récupérer les chaînes de connexion.
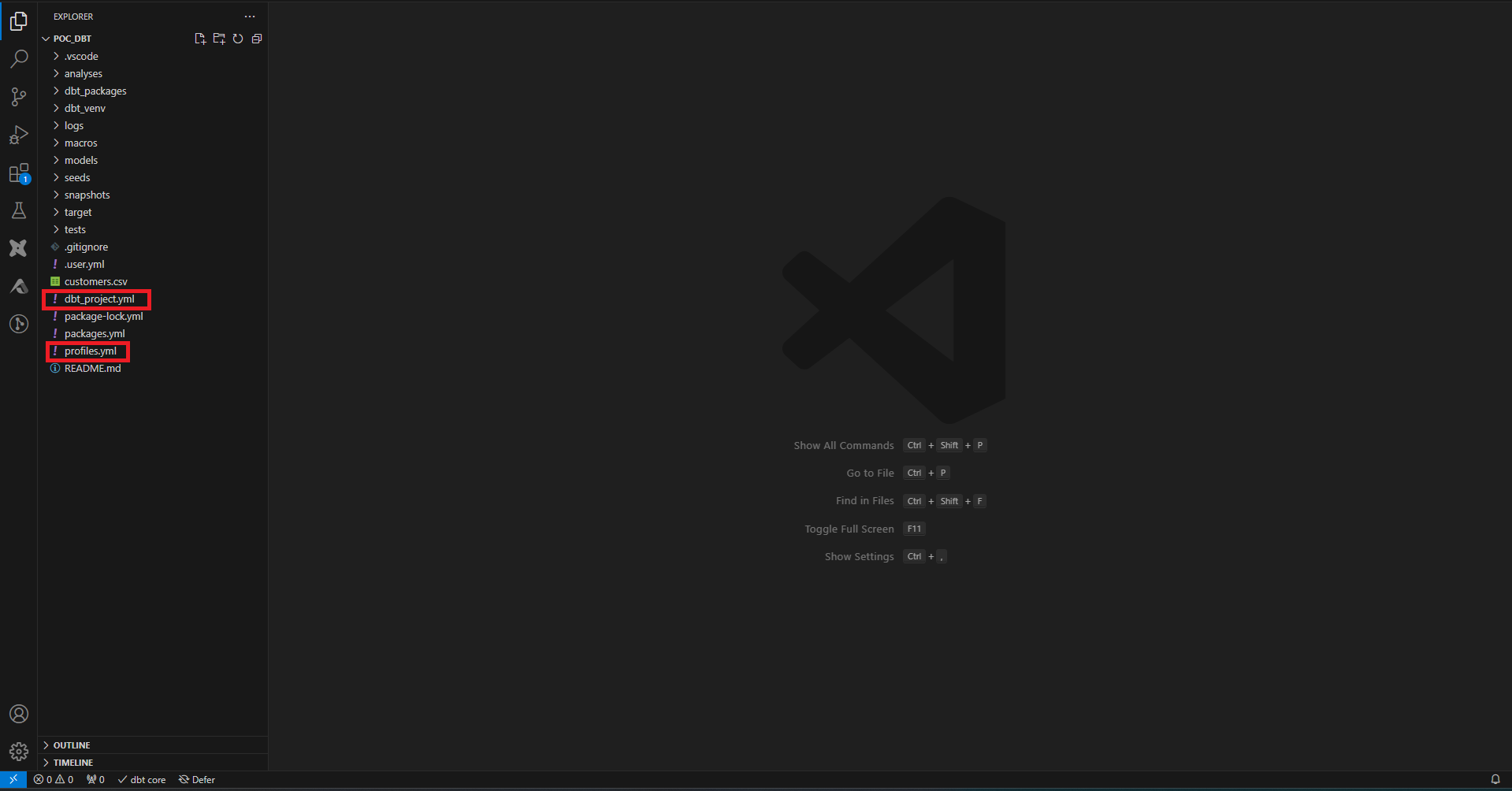
Avec la commande dbt init, on initialise les fichiers de base du projet. Par défaut, le fichier gérant les profils dbt est placé à la racine du dossier utilisateur. On peut spécifier avec des flags d’autres emplacements. Les fichiers de configuration sont automatiquement lus depuis le dossier courant et si non trouvé, dans les dossiers parents. Pour cet article j’ai placé tous les fichiers de configuration à la racine du projet.
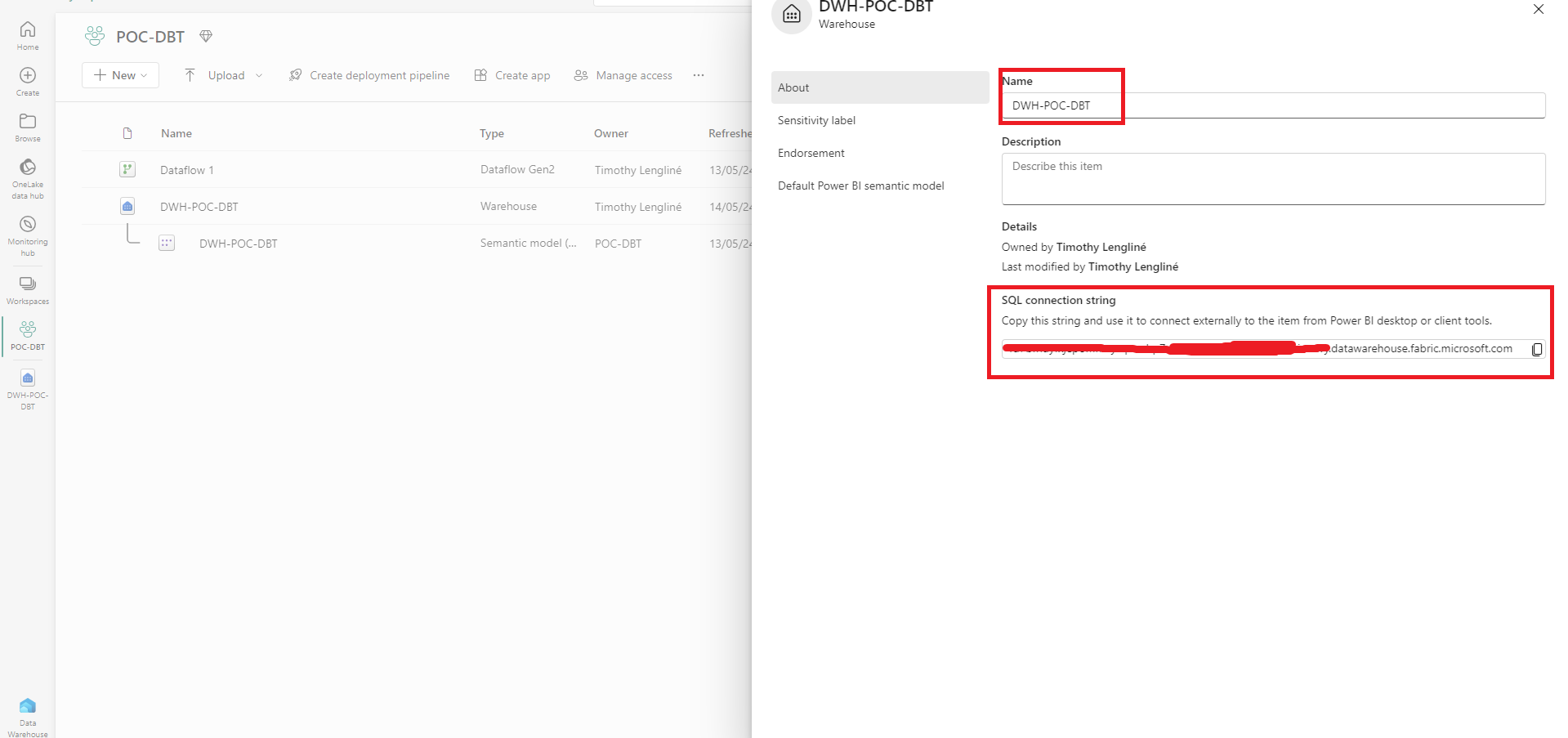
Dans le fichier profile.yml, il faut entrer la configuration de notre data warehouse. Pour un data warehouse sur Fabric, on trouve les informations nécessaires ici :
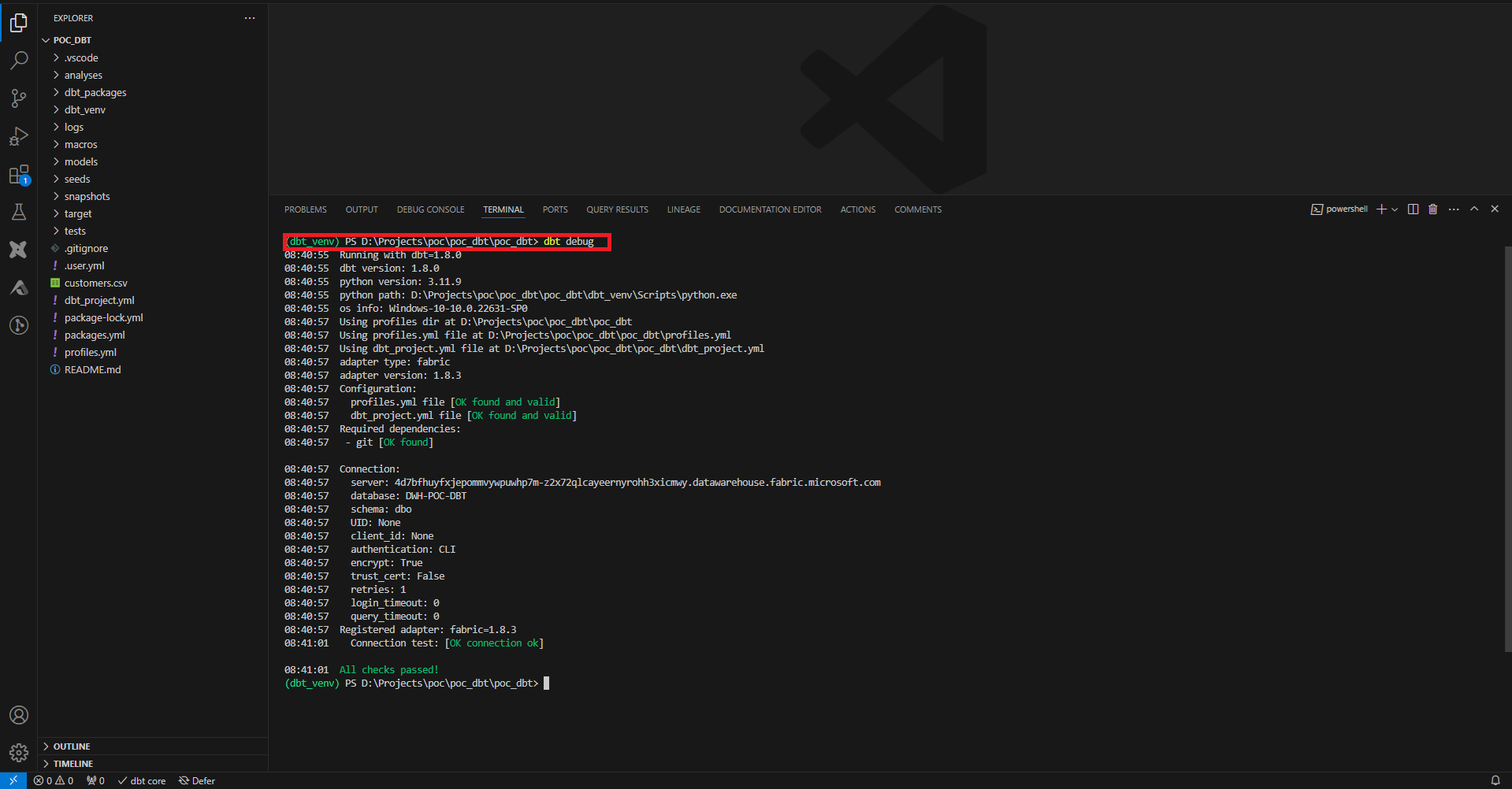
Pour vérifier que la configuration initiale est OK, on joue la commande dbt debug.
Seeds, Analyses & Models
Après avoir joué la commande dbt init, en plus des fichiers de configuration, des dossiers ont dû être créés (comme les dossiers, seeds, models ou analyses par exemple). Ces dossiers contiendront des fichiers pour créer des tables, vues ou requêtes SQL.
Pour commencer, on souhaite peupler notre data warehouse.
dbt ne gère pas l’extraction de données et suppose que les données sources existent déjà dans le data warehouse. dbt fait une exception à cela en permettant d’intégrer des fichiers, via les ‘seeds’. L’usage de ces seeds devrait être limité au maximum, notamment dans le cas où il s’agit de fichiers statiques, ou de données qui ne changent pas fréquemment.
Ici nous allons peupler 2 tables avec les fichiers CSV suivants.
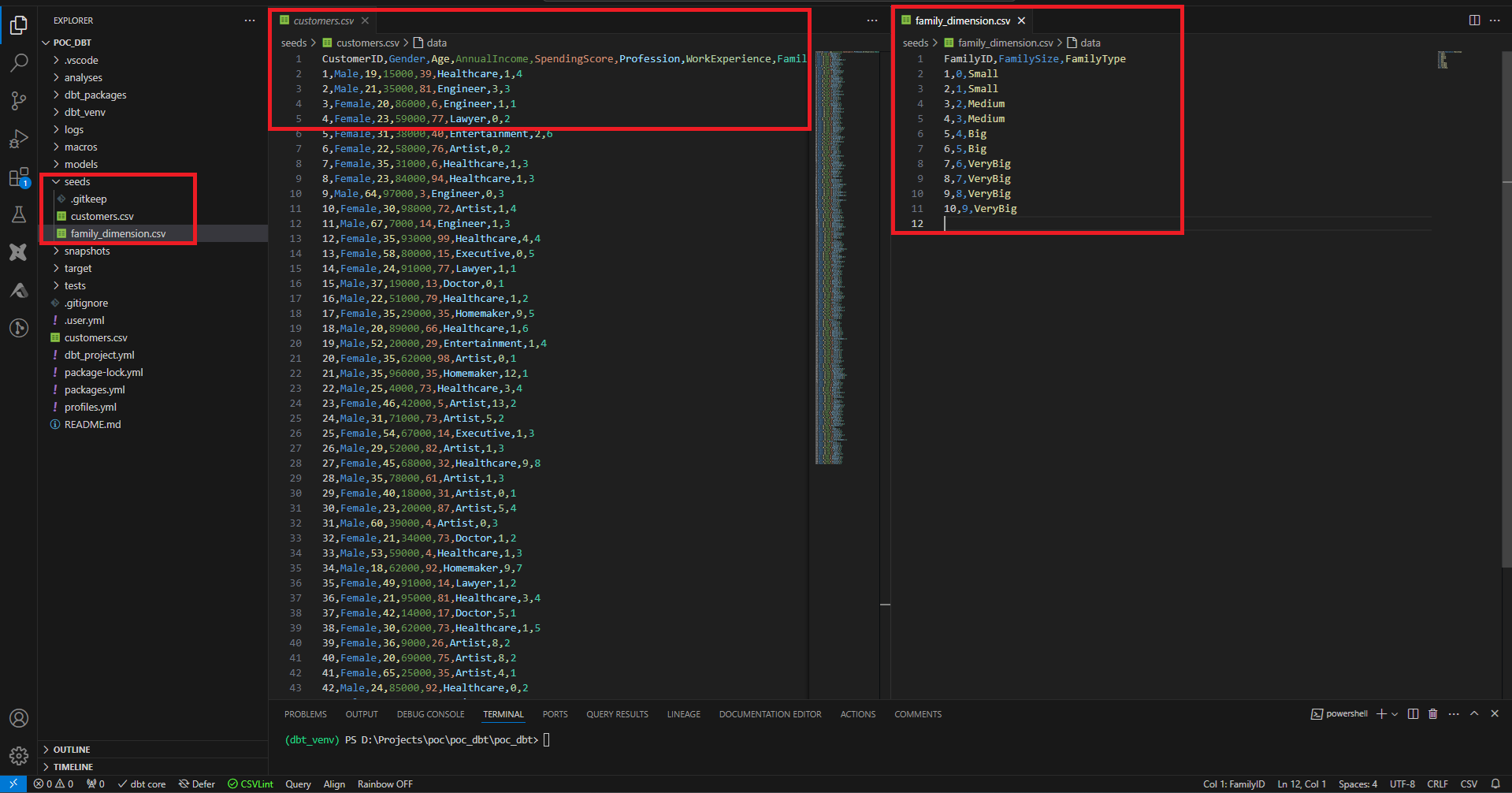
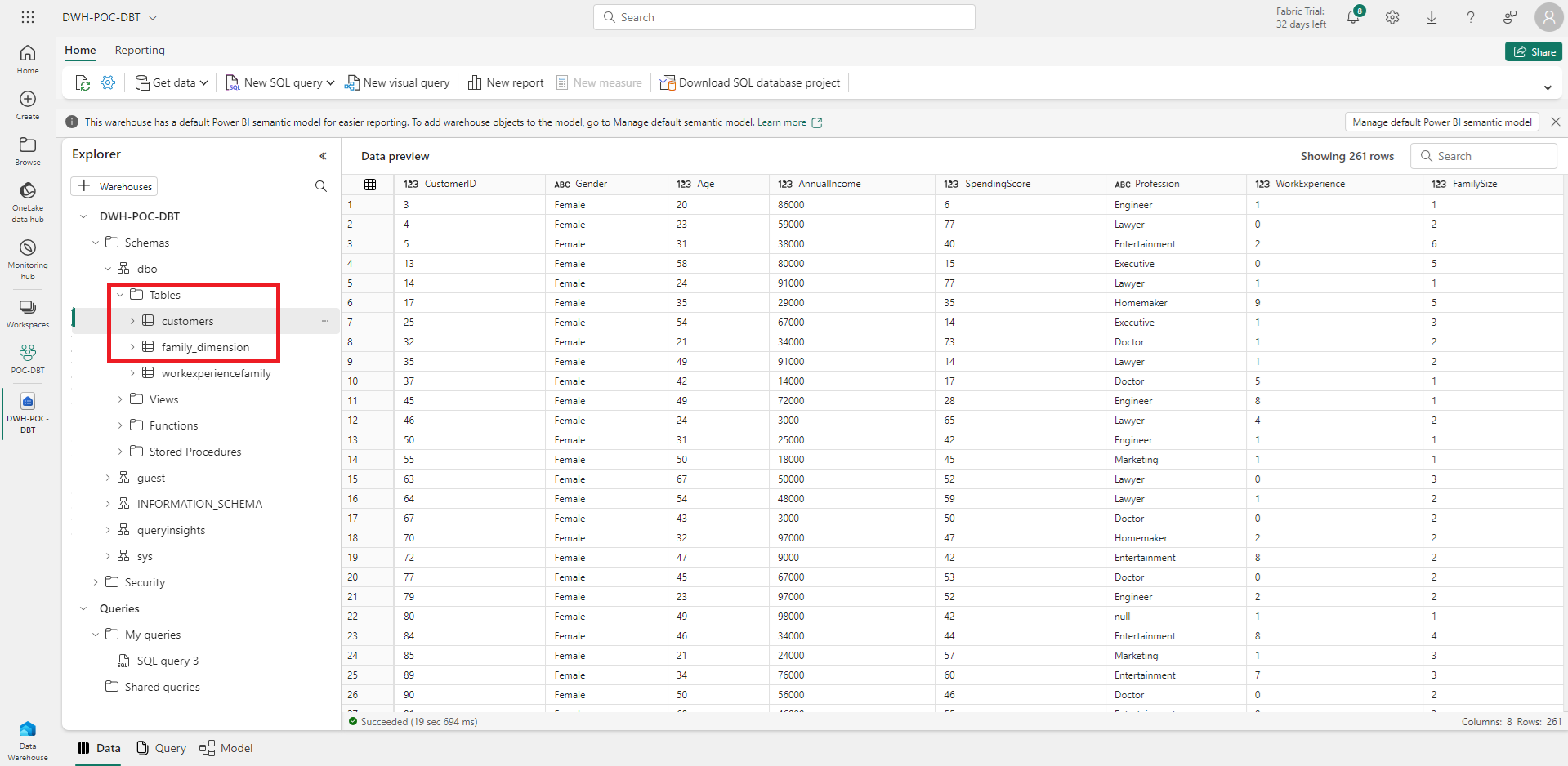
On dépose les fichiers CSV dans le dossier seeds, et on joue la commande dbt seed, pour charger les fichiers dans le data warehouse. Par défaut les données seront chargées dans des tables se nommant en fonction du nom du fichier.
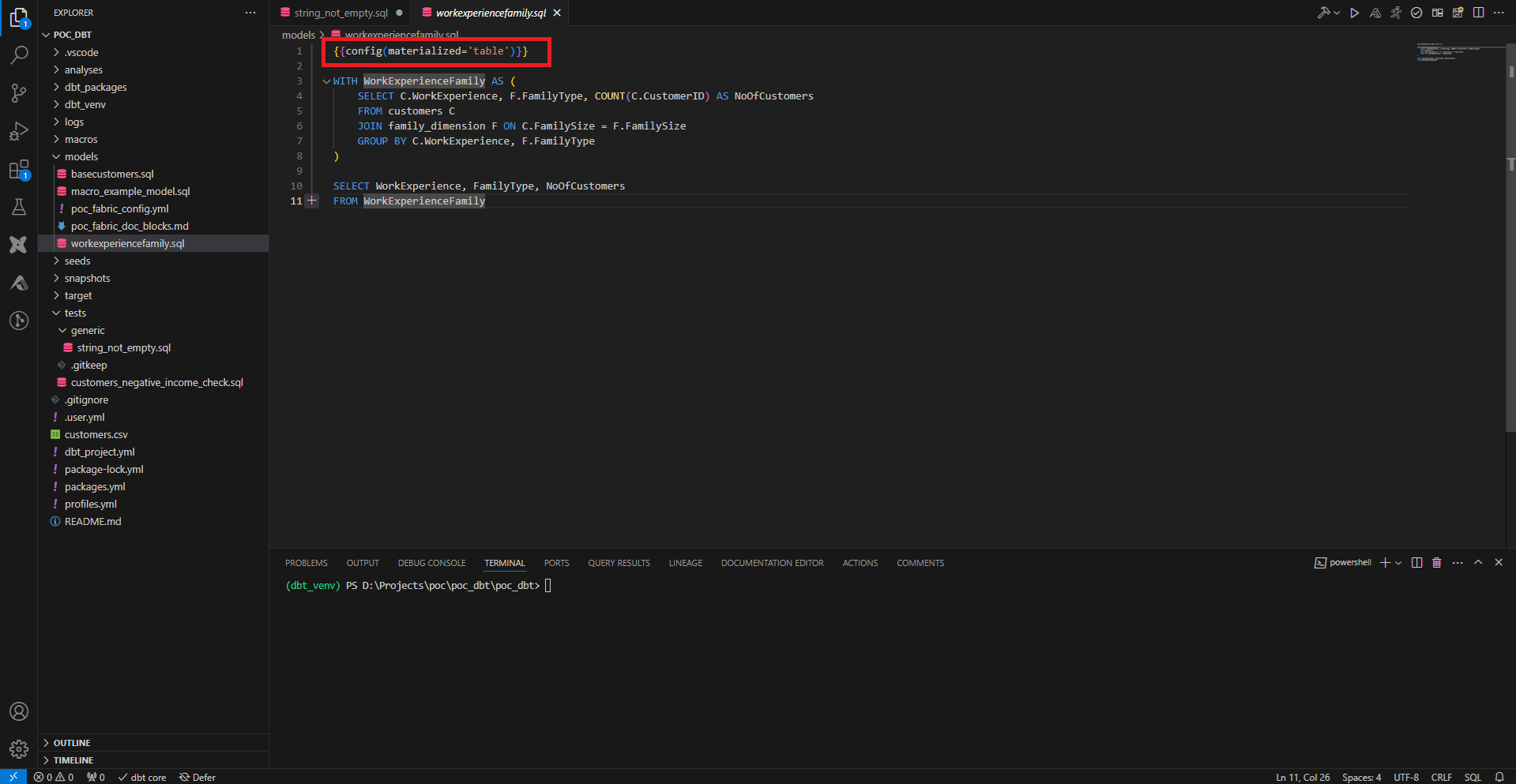
Dans le dossier models, les fichiers SQL qui contiennent des requêtes SELECT seront interprétés comme des créations de ressources (tables, vues). dbt gère mieux les CTE que les requêtes complexes, on préfèrera donc faire systématiquement des CTE. Par défaut la ressource créée est une vue, on peut forcer la création d’une table en ajoutant la configuration suivante en début de fichier :
{{config(materialized=’table’)}}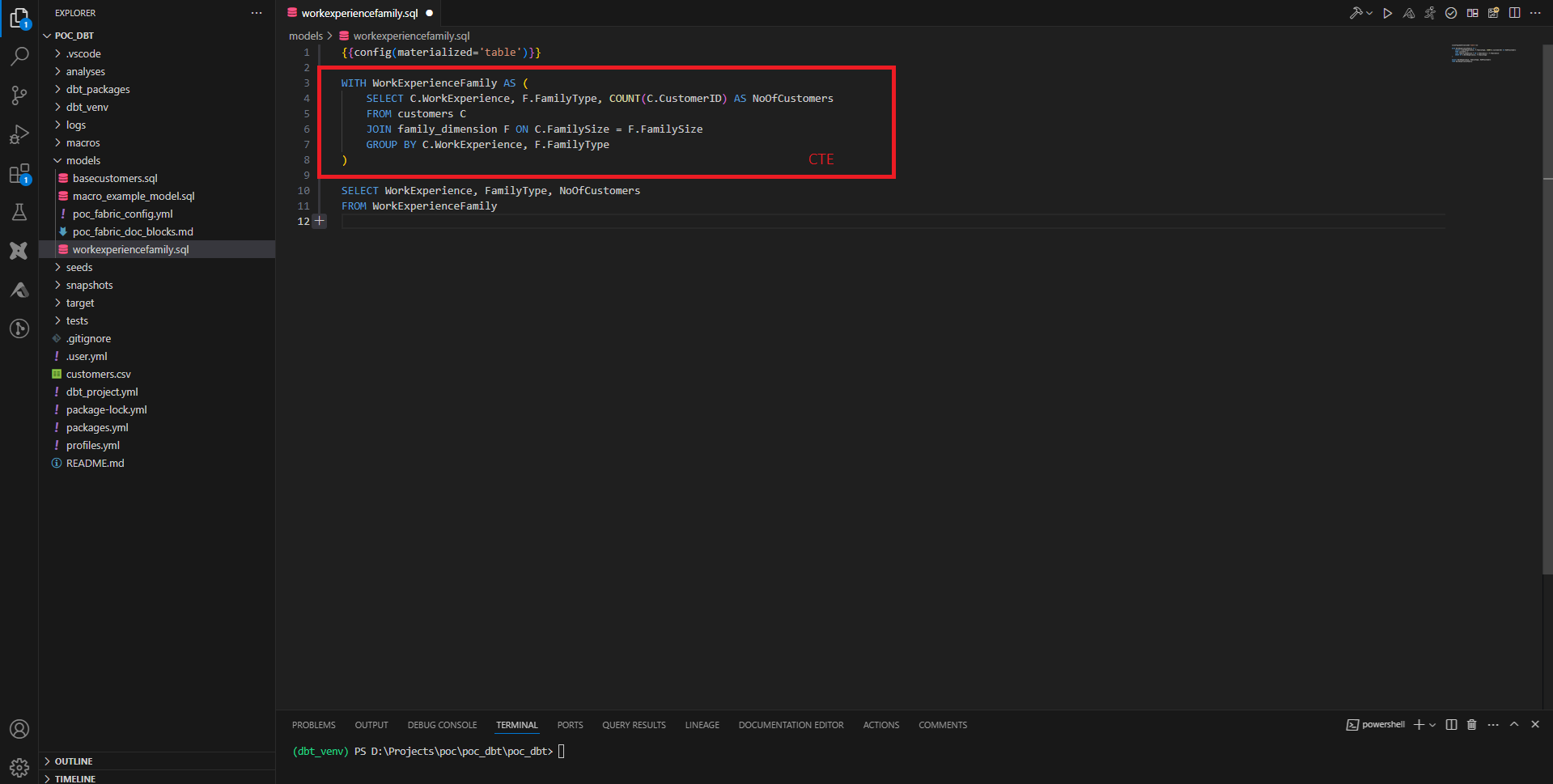
La commande dbt run parse l’ensemble des fichiers models et mets à jour le data warehouse avec les fichiers SQL dans models.
Pour faire des tests avant de créer nos ressources, on utilise la partie Analyses. On y crée des fichiers SQL de la même façon que dans models, et on a la possibilité sur VS Code de faire tourner la requête, sans créer la ressource.
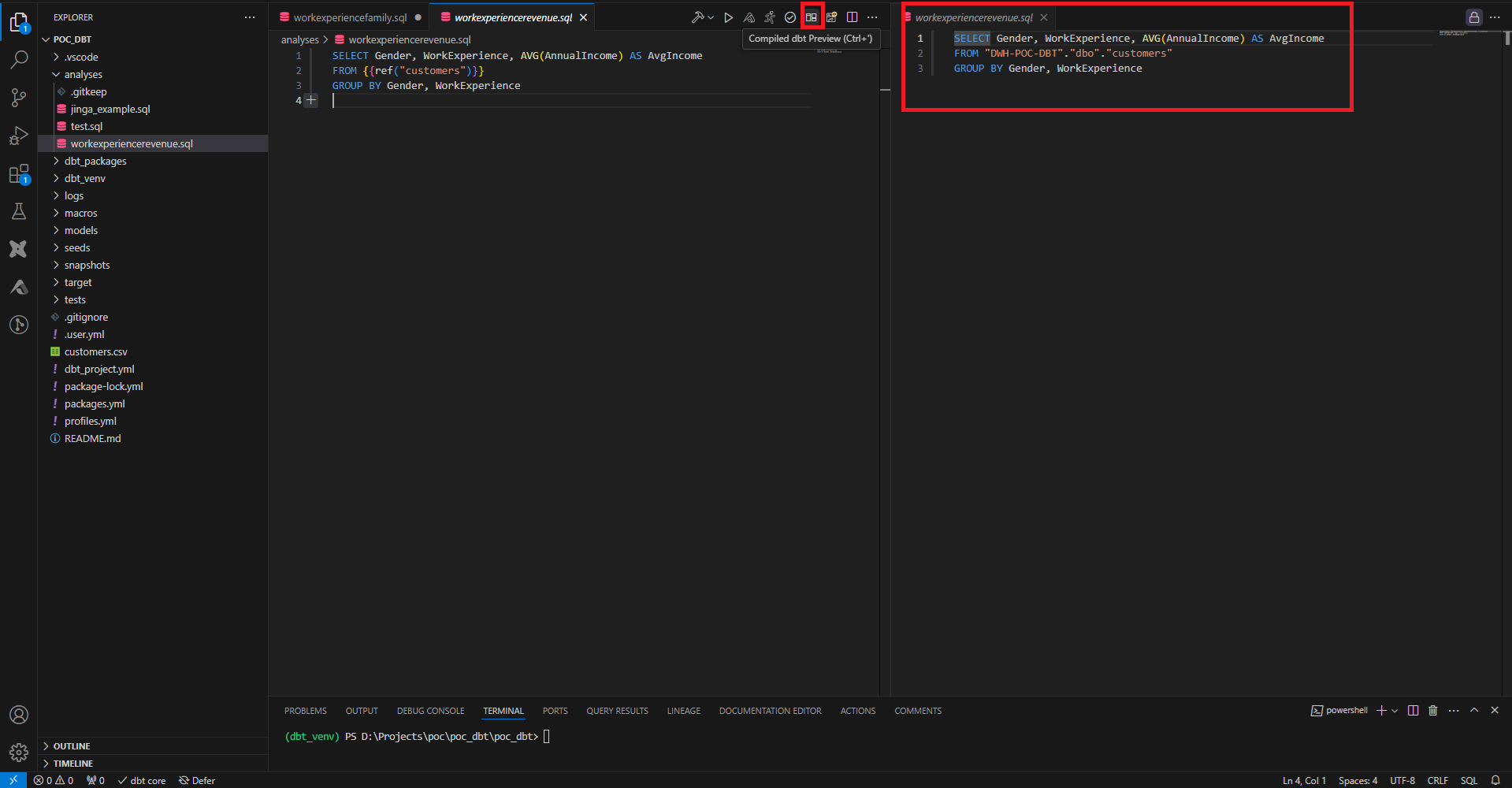
On peut aussi consulter la requête compilée, utile dans les cas où la requête fait des références dynamiques à des tables, ou dans le cas où des morceaux de la requête ont été factorisés dans d’autres fichiers. Cet outil permet un debug efficace lors de traitement de données complexes afin de ne pas envahir le data warehouse de données non fiables.
Jinja & Macros
Dans dbt on utilise 3 langages : le SQL pour les requêtes au data warehouse, le YAML pour les fichiers de configuration, et le jinja pour l’insertion de code dans les fichiers YAML et SQL.
Dans les fichiers, si on a {% xxx %}, alors xxx est une déclaration que ce soit d’une variable, d’une condition (if), ou d’une boucle (for) par exemple.
Dans des doubles curly braces {{ xxx }}, le code à l’intérieur sera évalué, il s’agit dont d’expression, comme la valeur d’une variable ou l’appel à une fonction.
{# xxx #} permet d’ajouter des commentaires, qui ne seront ni interprétés ni compilés.
Le code sans aucun bracket sera donc considéré comme du texte et non interprété par jinja, et donc considéré comme du pur SQL ou du pur YAML.
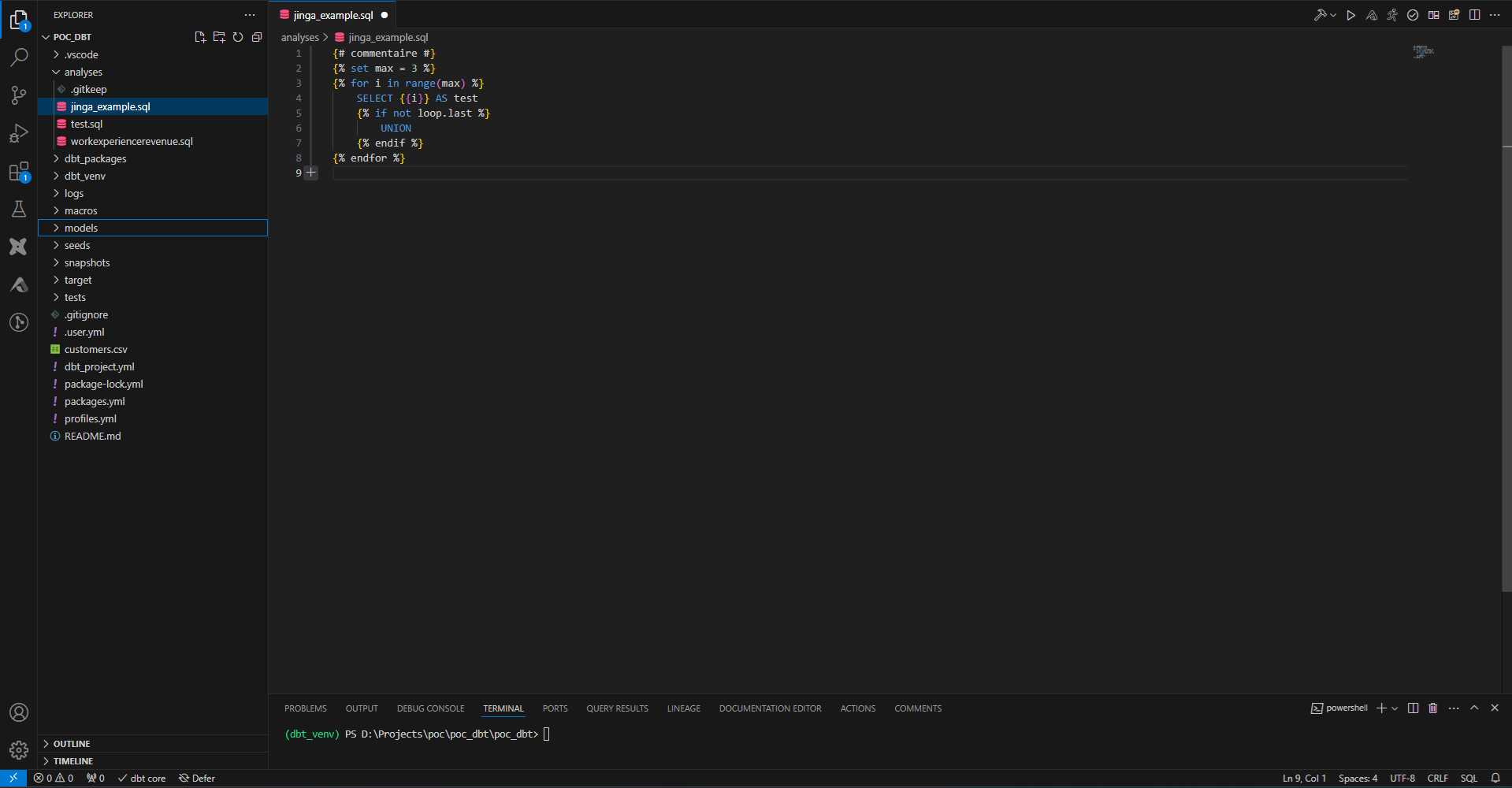
Le Jinja se retrouve dans presque tous les fichiers car c’est l’outil principal pour factoriser le code, intégrer du dynamisme dans les requêtes et les config ou référencer des ressources (comme de la documentation, des configurations, des fichiers, des fonctions, etc.)
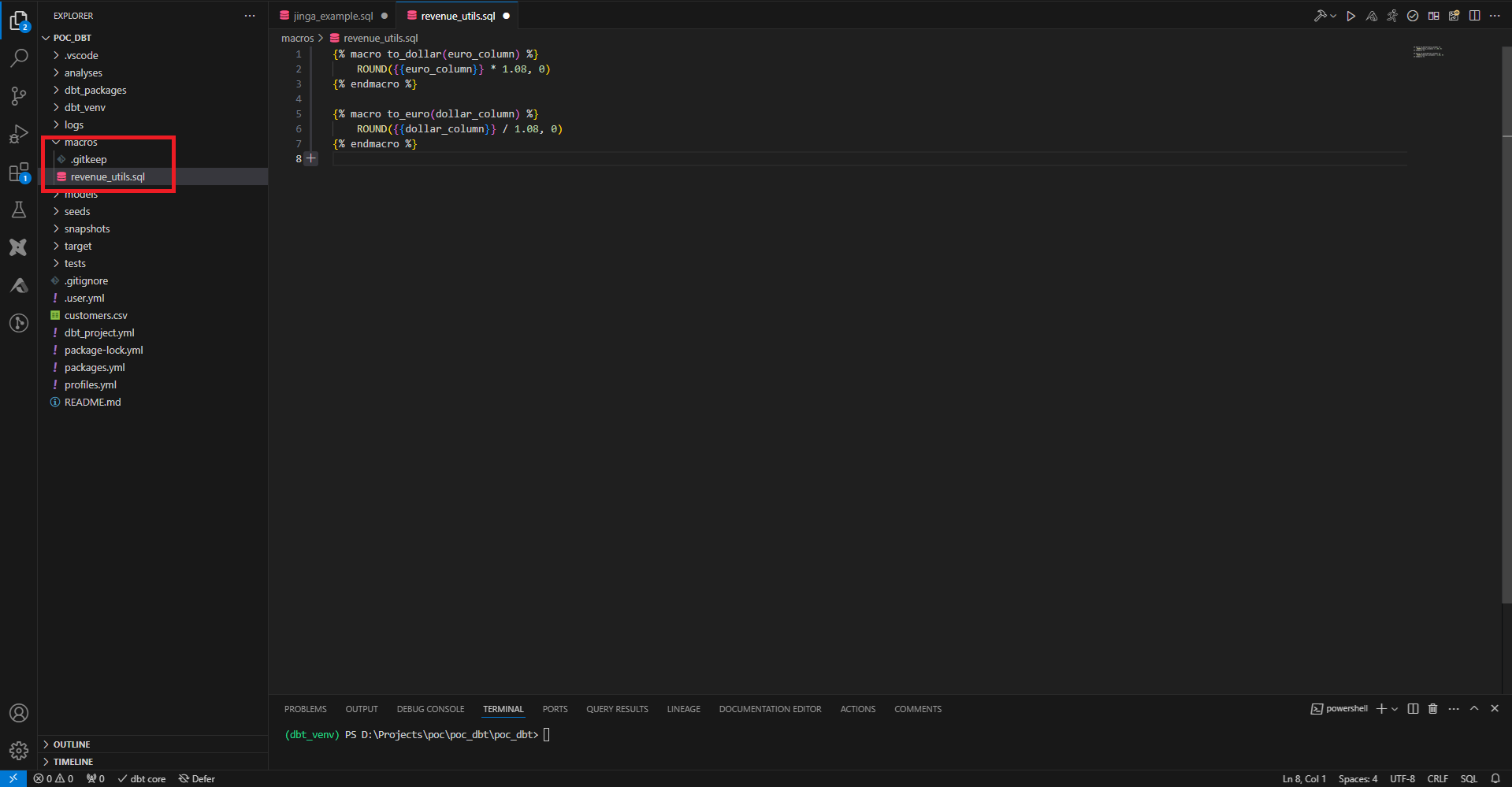
Une autre façon de factoriser le code est d’utiliser les macros. Le dossier macro peut contenir des fichiers SQL dans lesquels on définit, entre balises Jinja macro, des morceaux de code SQL.
Une macro se déclare avec un nom, des paramètres et le code SQL de la macro. Cela permet de déporter du code que l’on aurait à répéter dans plusieurs model en un seul endroit. Ici on crée des macros pour convertir des dollars en euro et des euros en dollar.
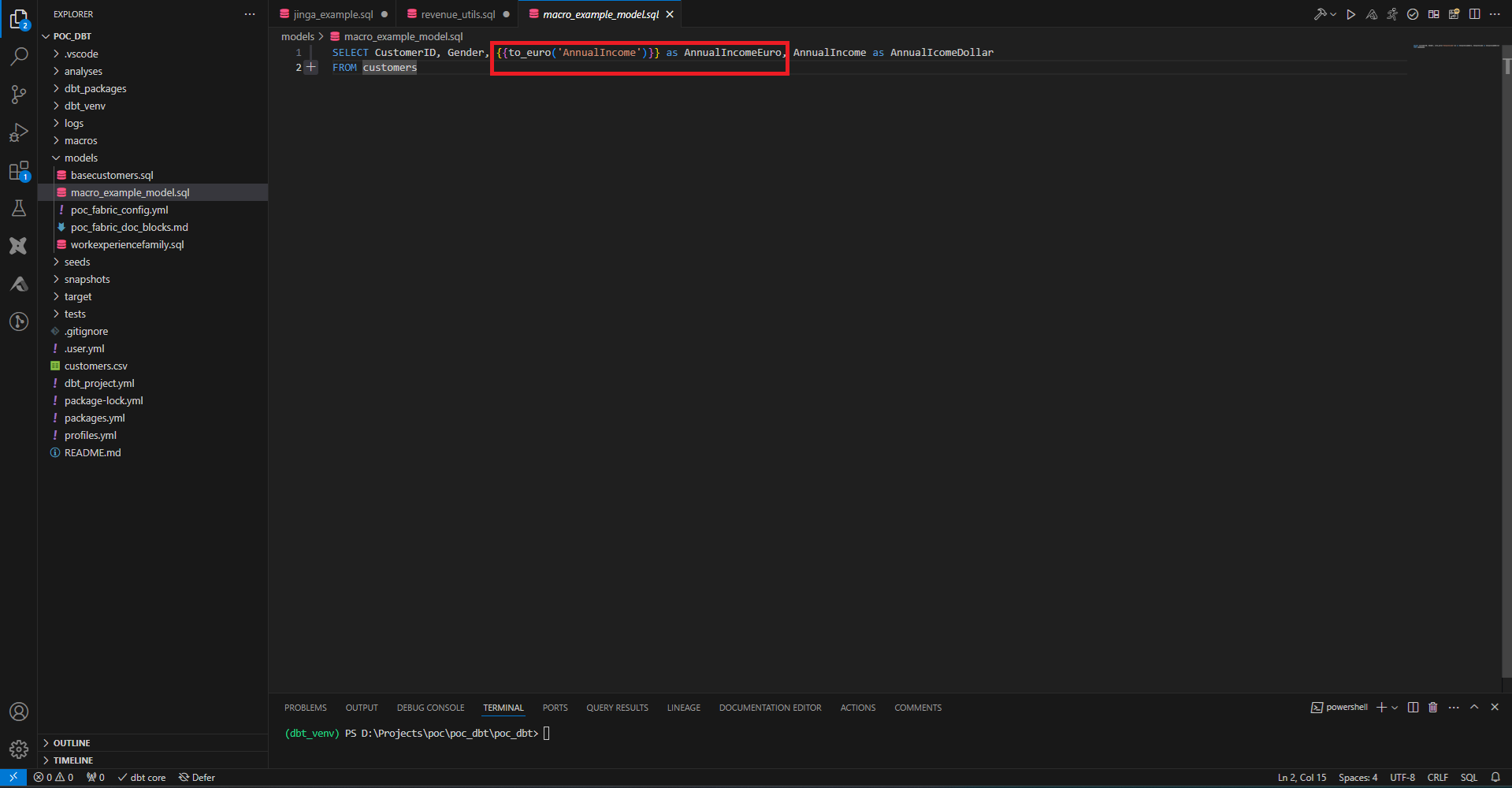
On crée un model qui fait appel à cette macro. Le code Jinja qui appelle la macro est directement remplacé par le code contenu dans la macro lors de la compilation. C’est pourquoi les macros ne contiennent pas de ‘return’, contrairement aux fonctions utilitaires classiques des langages de programmation (Jinja est un langage de templating).
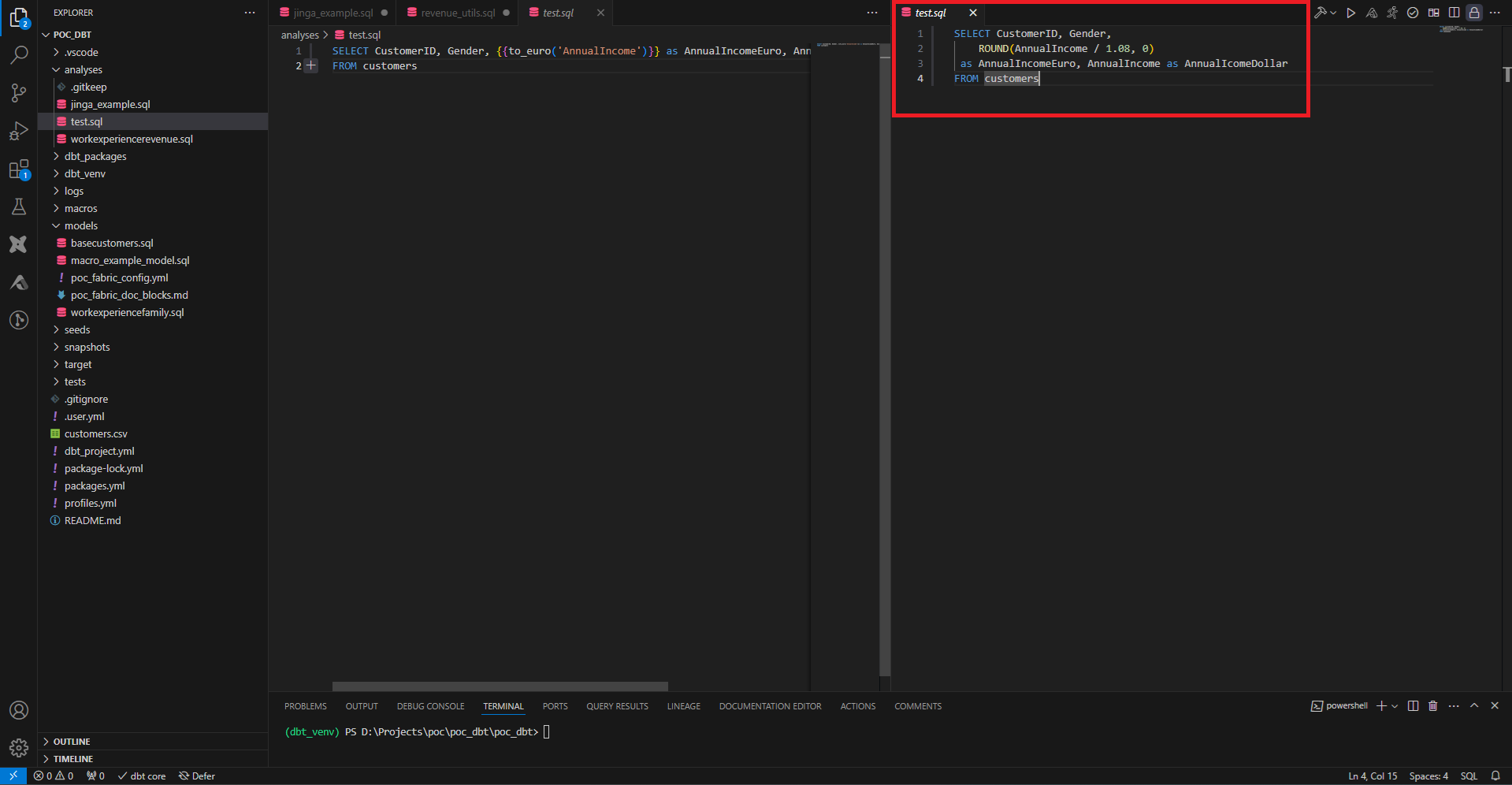
On peut consulter ceci en recopiant cette requête dans la partie analyse.
Tests unitaires & documentation
Afin de contrôler la qualité des données traitées, on peut ajouter des tests. Ces tests peuvent être spécifiques à une table, ou génériques pour pouvoir être réutilisés facilement sur de multiples colonnes à travers tous les models.
Ici on définit un test sur notre table customers afin de vérifier que toutes la valeurs d’AnnualIncome sont bien positives.
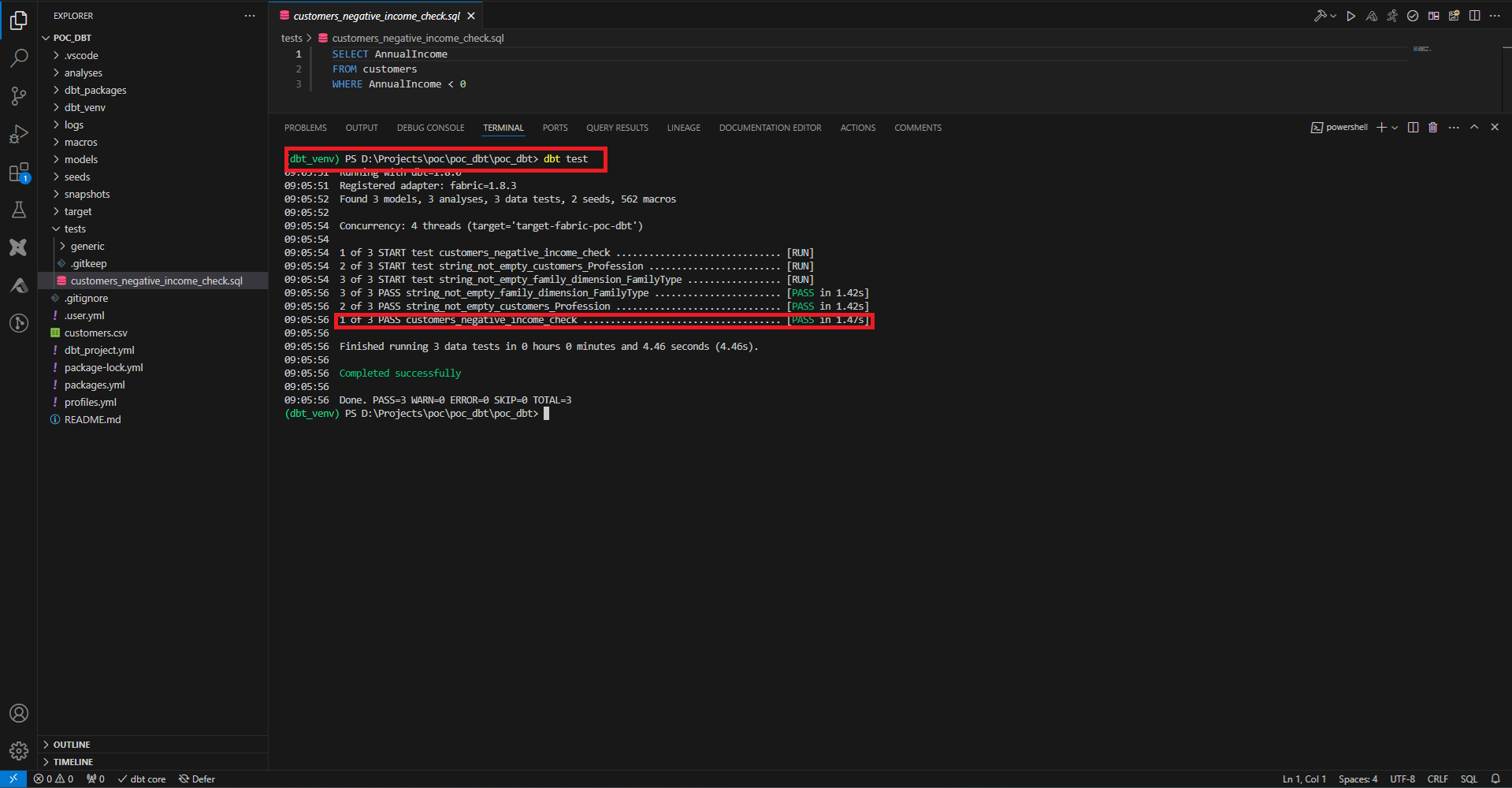
Pour faire tourner les tests, on joue la commande dbt test.
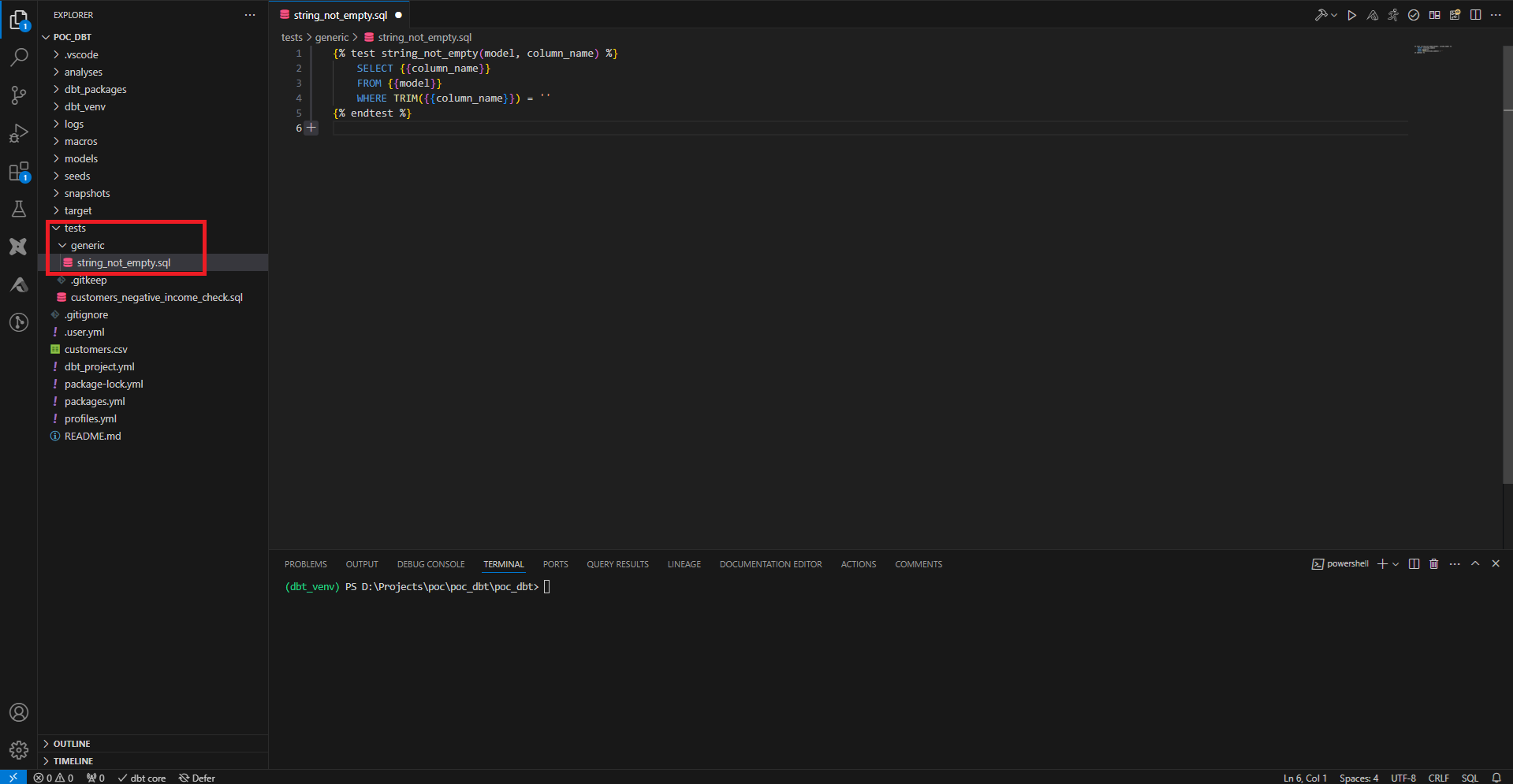
Pour créer des tests génériques, on crée un fichier SQL, qu’on range ici dans un sous-dossier tests/generic. Comme la plupart des ressources dbt, on déclare le test entre balise Jinja. On donne un nom à notre test et on donne en paramètre le model et le nom de la colonne. Ici on vérifie que le texte de la colonne n’est pas vide.
Pour utiliser ce genre de test, on doit passer un fichier de configuration.
3 types de configuration existent. Le plus direct consiste à inscrire la configuration directement en en-tête du fichier comme on a pu le faire pour notre premier model.
On peut aussi inscrire la configuration de toute l’application dans le fichier de configuration pré-rempli (avec dbt init) dbt_project.yml. Des configurations générales y sont déjà présentes, et les bonnes pratiques recommandent d’y ajouter toutes les configurations qui toucheront l’ensemble du projet.
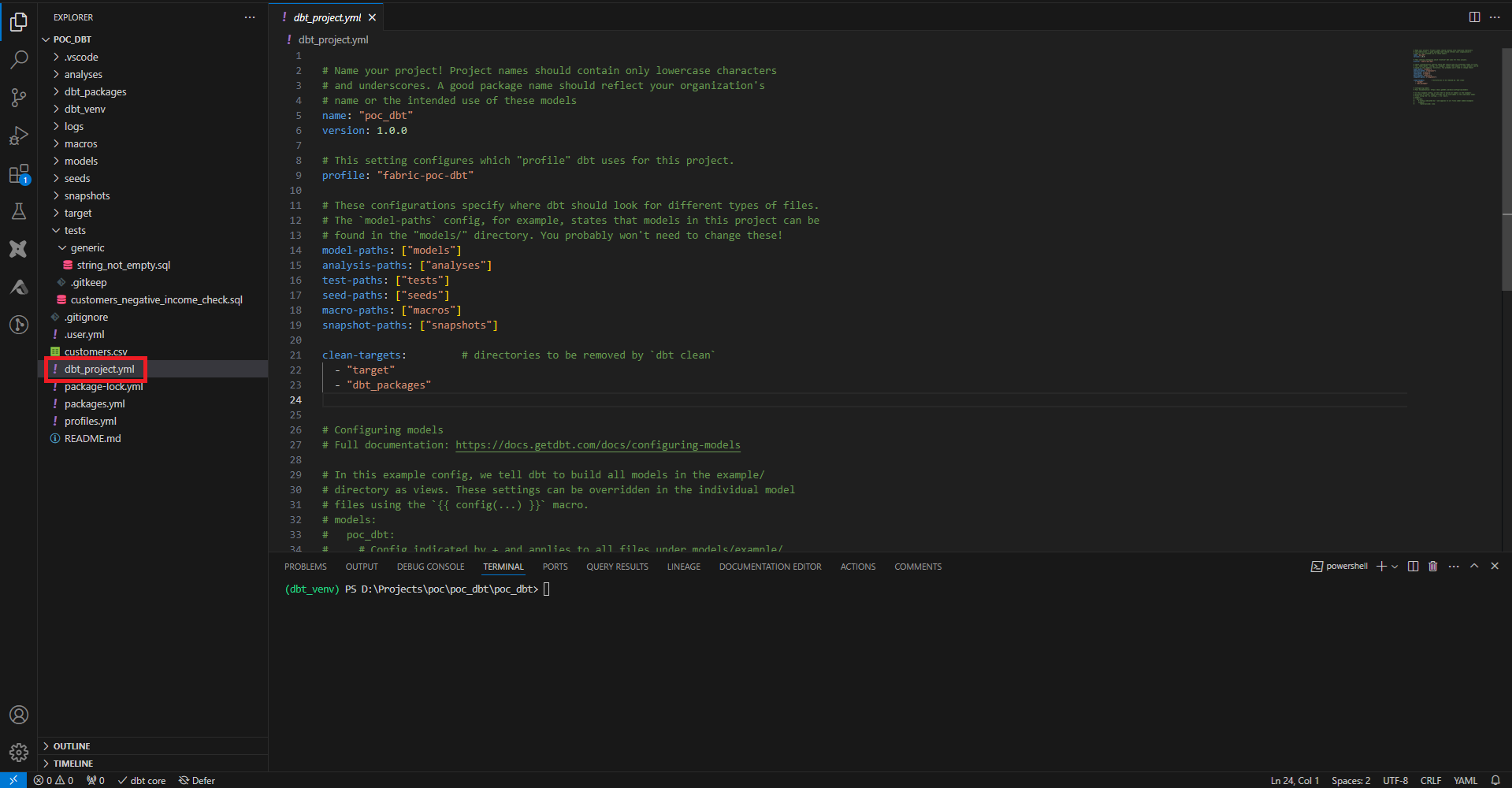
La dernière façon de configurer les ressources est de créer des fichiers YAML dans les sous-dossiers concernés par les configurations. Par exemple dans models, on crée un fichier poc_fabric_config.yml avec les tests que l’on souhaite appliquer sur chaque model et chaque colonne.
On peut ainsi facilement ajouter notre test de vérification de colonne non vide à toutes les colonnes que l’on souhaite, en spécifiant uniquement le nom du test.
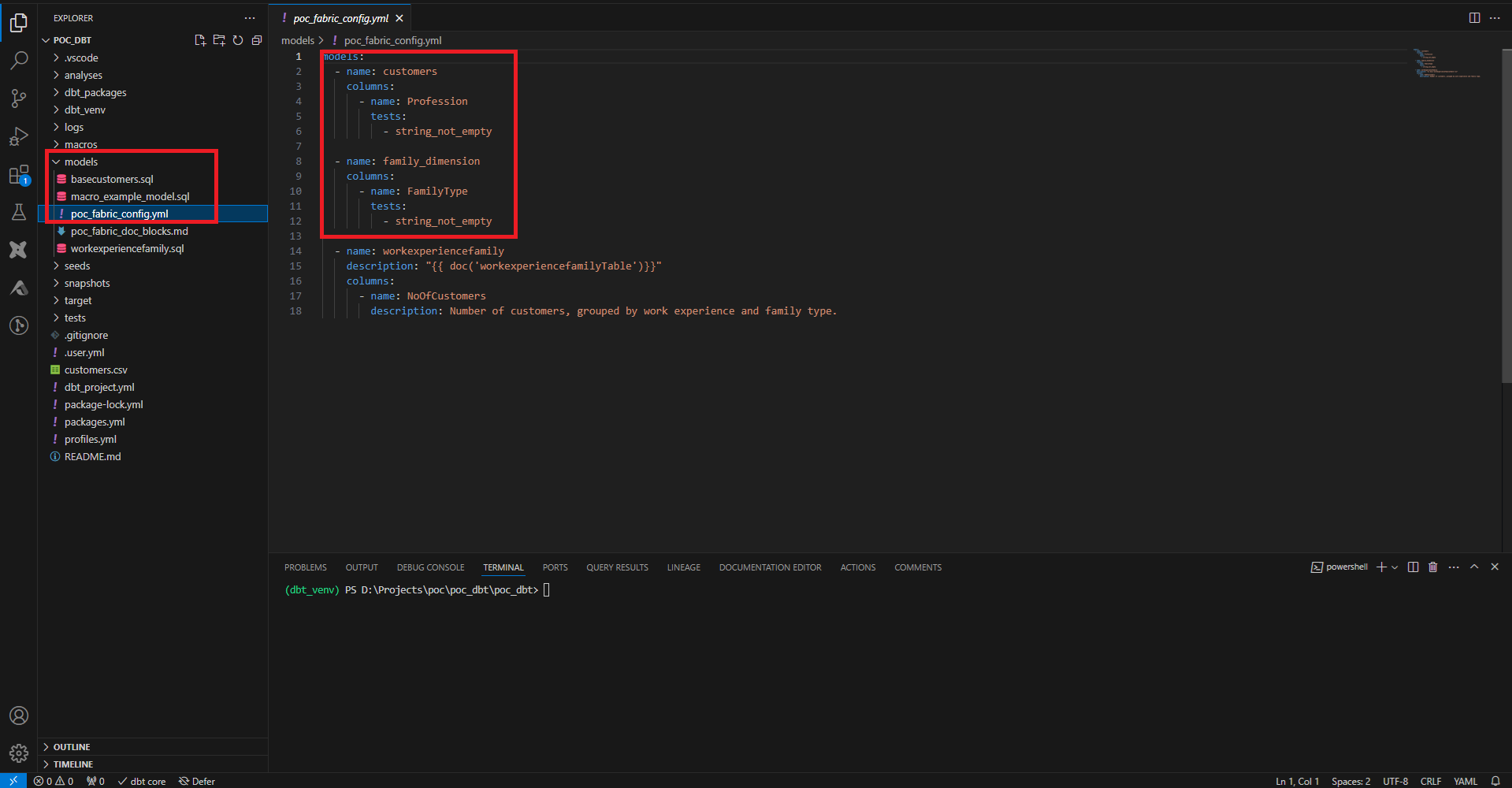
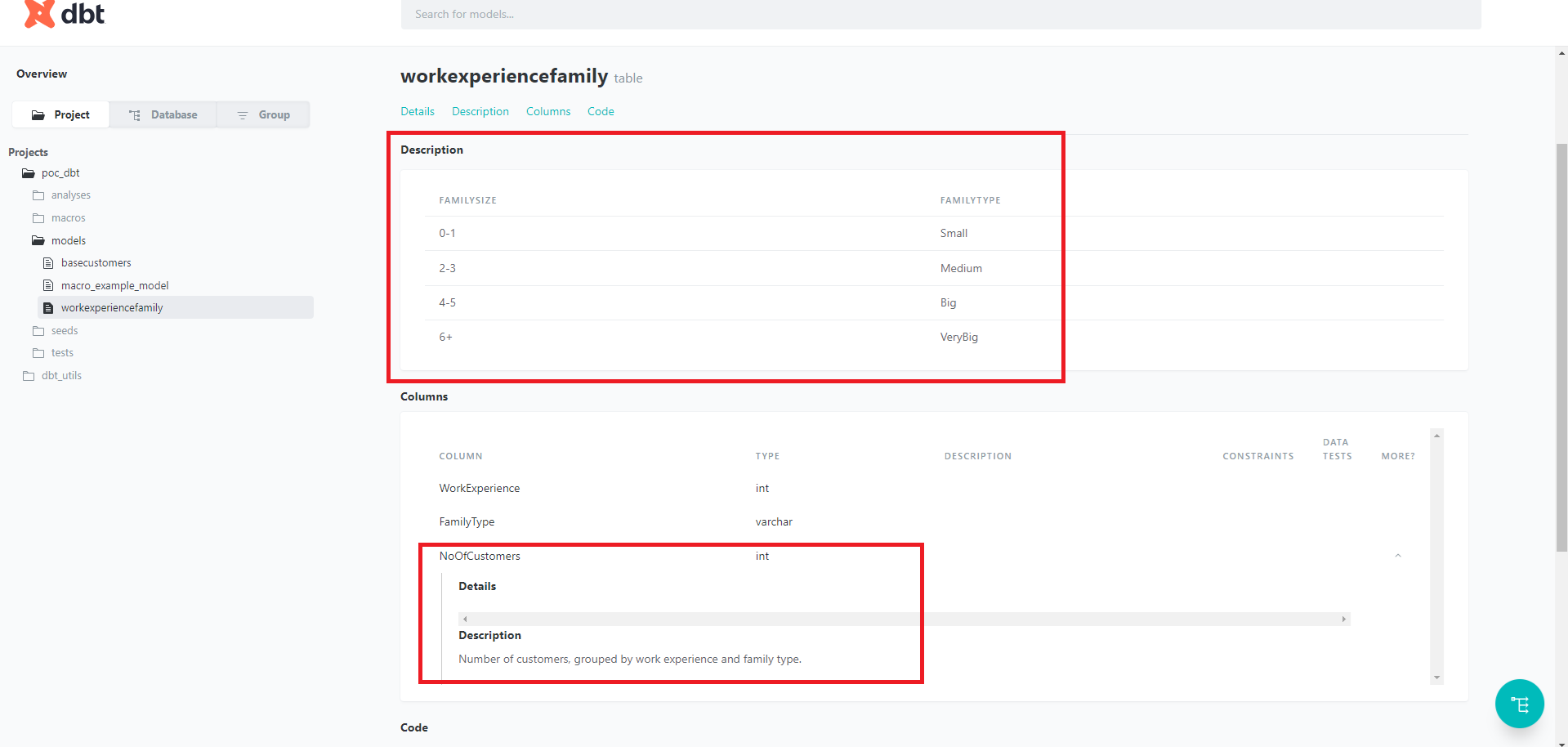
Via ce fichier, on peut également ajouter la documentation, au niveau du model ou au niveau d’une colonne. Cette documentation peut s’écrire directement dans le fichier, ou bien via un fichier écrit en markdown, donc le contenu est entouré par des balises Jinja appropriées. On crée ici une description sommaire de notre dimension, et on la référence dans notre fichier de config.
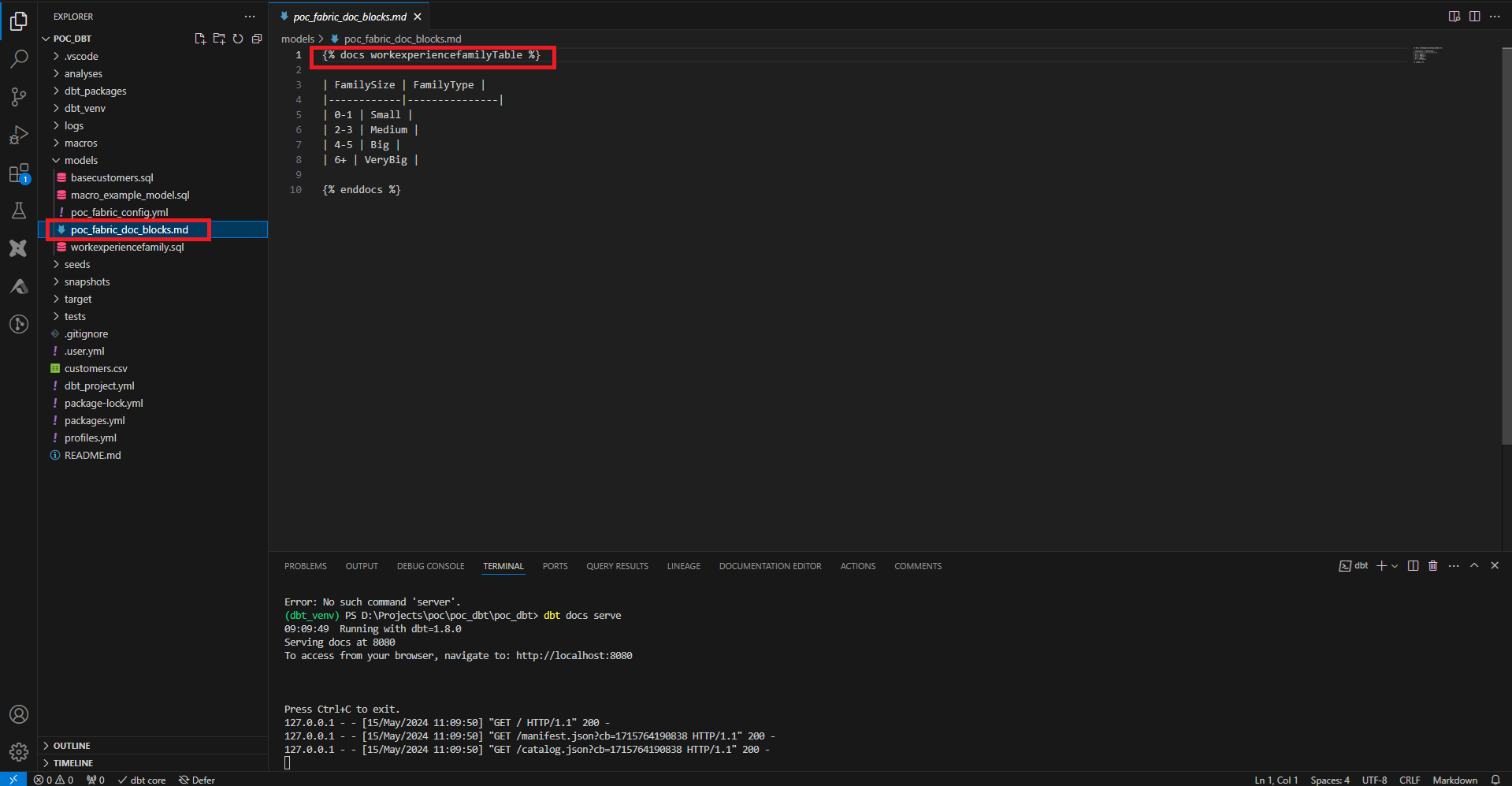
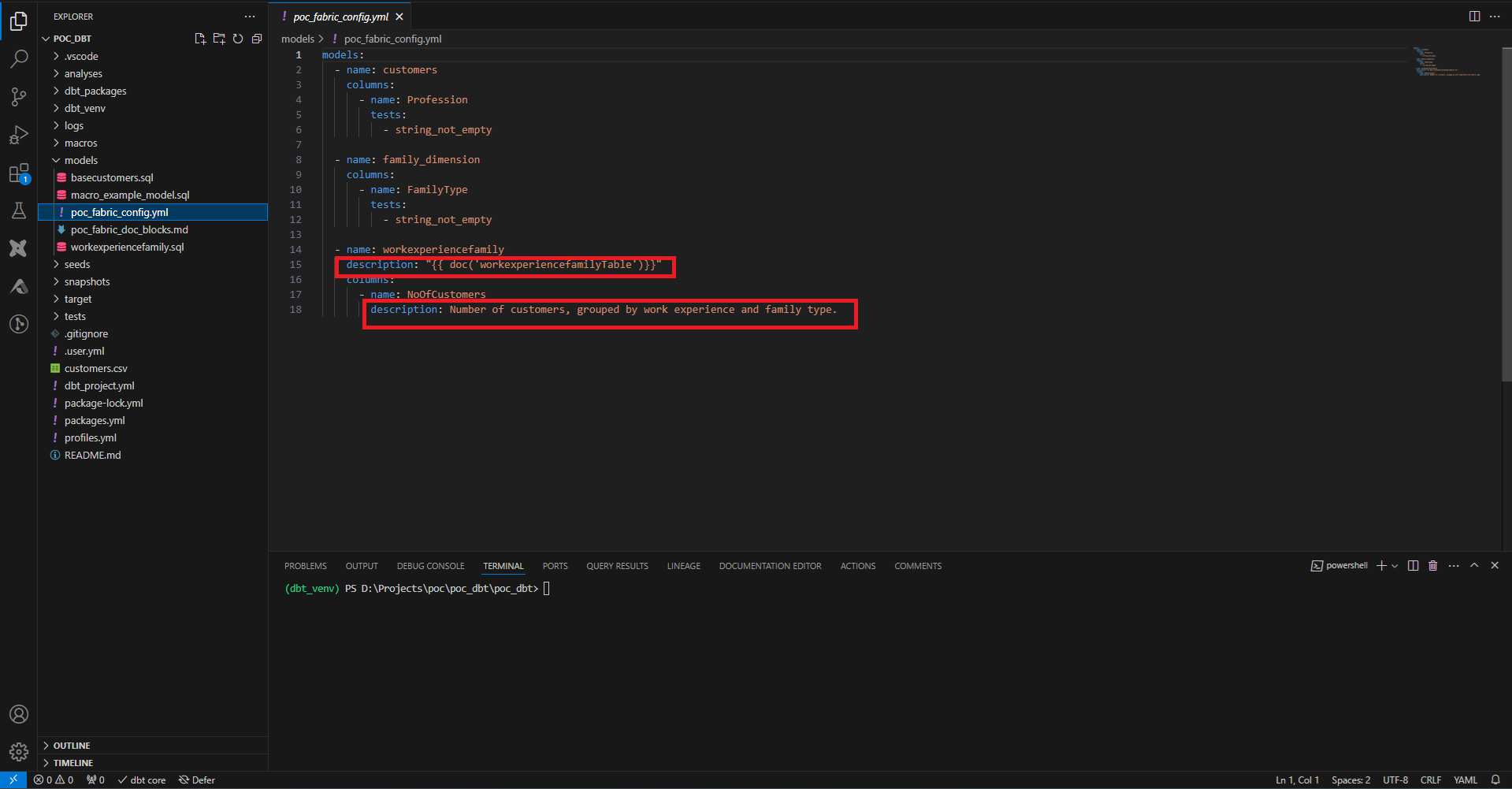
Une fois la documentation écrite, on génère les fichiers avec la commande dbt docs generate, et on peut l’exposer avec dbt docs serve. Par défaut la documentation n’est disponible que sur le localhost, mais contient la documentation ainsi que les informations des données présentent dans le data warehouse.
Packages
Pour ne pas réinventer la roue à chaque projet, il est possible de référencer des packages, à la manière dont on importerait des bibliothèques dans d’autres langages. Une des principales sources de packages vérifiés est le site https://hub.getdbt.com/
Pour ajouter des packages, on crée à la racine du projet le fichier packages.yml, et on y précise le nom de la source et sa version, que ce soit sur hub.getdbt ou une adresse url git par exemple.
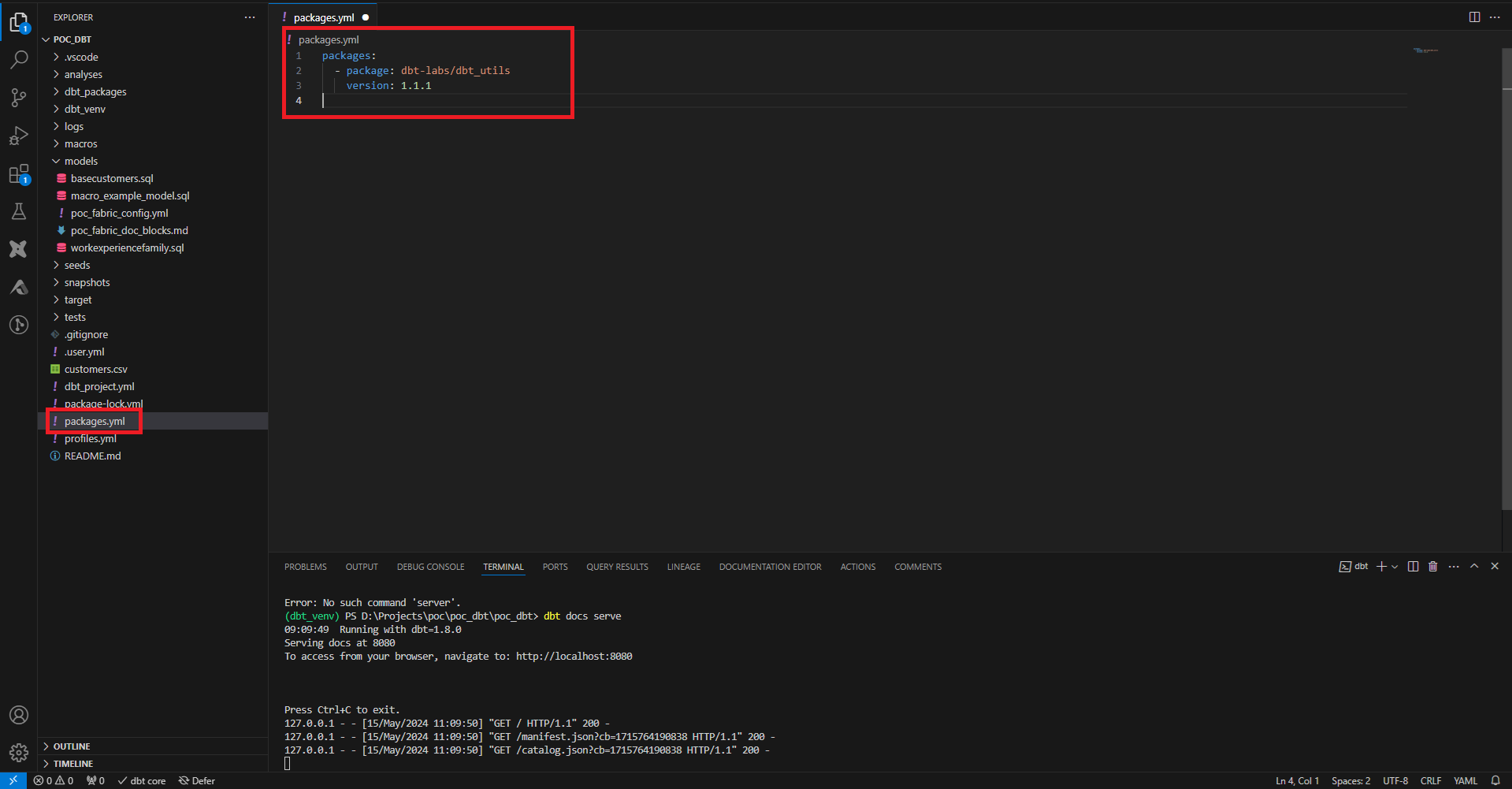
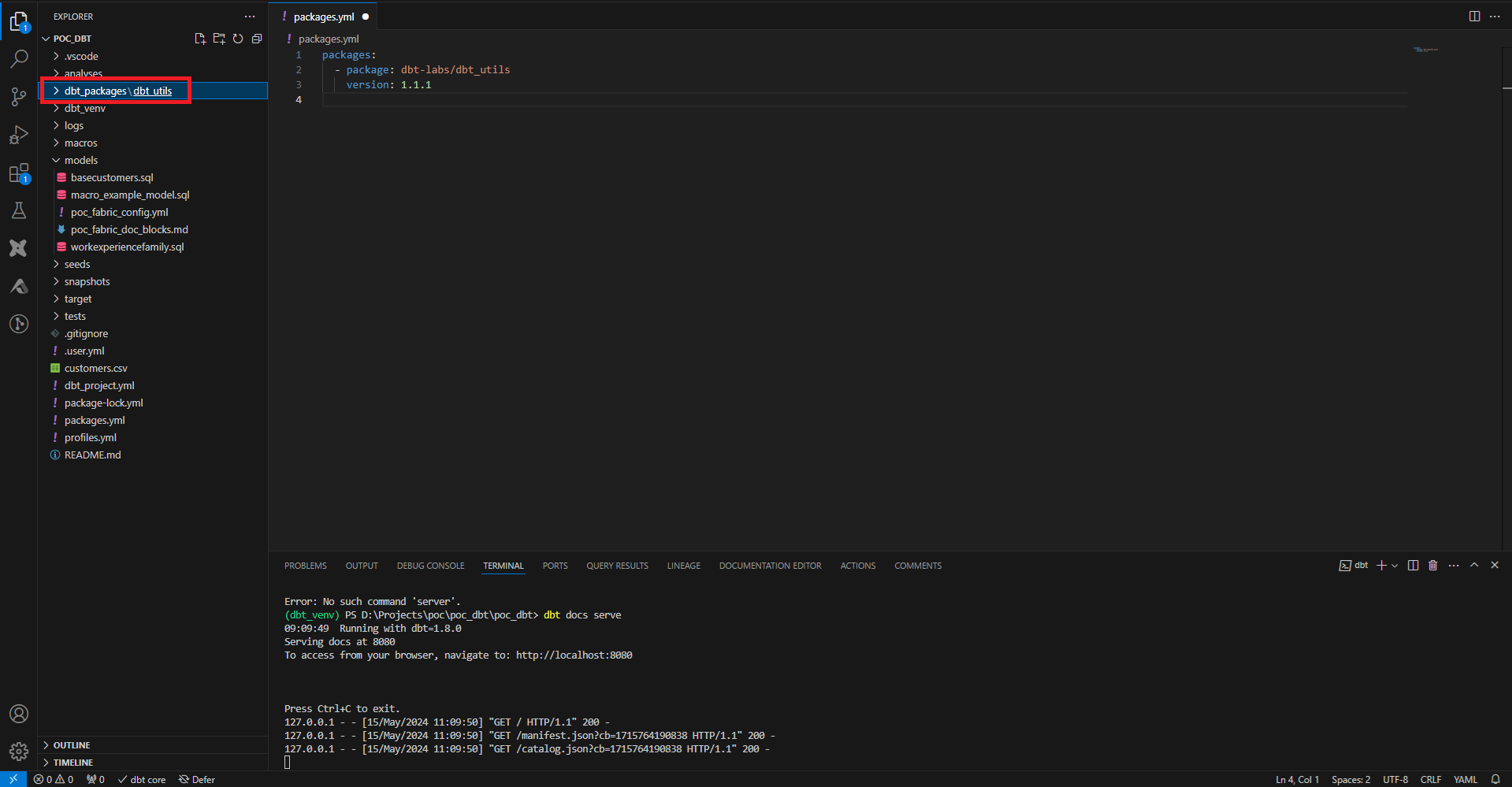
Ici on ajoute le module dbt_utils qui contient de nombreuses macros utilitaires. Pour les intégrer au projet on joue la commande dbt deps, et on voit apparaître un dossier dbt_packages qui contient le module téléchargé.
Par défaut de nombreuses macros existent déjà nativement dans dbt et il est possible de travailler sans ajouter de dépendances externes. On peut consulter ces fonctions dans cette documentation : https://docs.getdbt.com/reference/dbt-jinja-functions
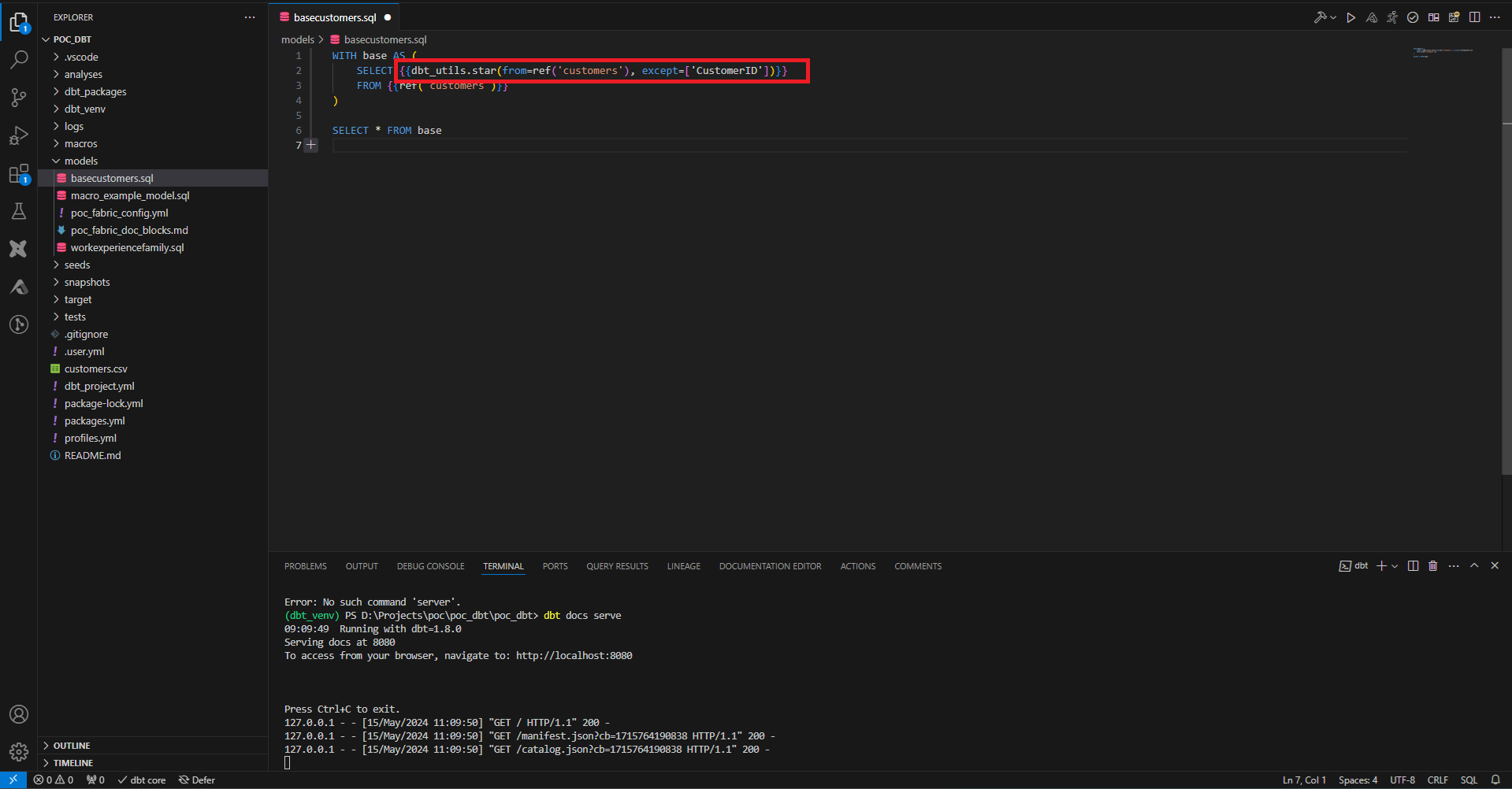
Quand les dépendances ont été chargées dans le projet on peut les utiliser entre balises Jinja, comme ici dans un model.
dbt_until.star permet de sélectionner toutes les colonnes à l’exception de certaines.
Gestion des sources
Jusqu’à présent on a directement renseigné le nom des tables ou des vues du data warehouse dans nos requêtes. Une couche d’abstraction entre le nom technique utilisé dans le code et le nom business utilisé dans le warehouse peut parfois être nécessaire.
On crée un fichier dans le dossier model pour créer cette couche d’abstraction. Les références au data warehouse sont les propriétés database, schema et les propriétés identifiées des tables. Les références à utiliser dans le code sont les propriétés name.
Une fois ce fichier sauvegardé, on peut modifier nos models pour remplacer nos sources.
Cette couche d’abstraction est notamment salvatrice lorsqu’un changement de nom de table doit se faire. Seul le fichier de configuration doit alors être mis à jour au lieu de modifier chacun des fichiers SQL utilisant les objets à renommer.
Gestion de la matérialisation
La matérialisation des données sera d’usage par dbt pour transmettre les données au data warehouse : table ou vue, ajout des données ou réécriture de la table, gestion de l’historique des modifications, etc.
Vue et Tables
Par défaut, quand on écrit une requête dans la partie models, une vue est créée dans le data warehouse. De plus, si une modification est détectée dans la requête, la vue est drop puis recréée. Les query (code SQL) en elles-mêmes ne sont pas stockées sur notre ressource, uniquement exécutées.
On a vu dans le paragraphe ‘seeds, analyses et models’ qu’on pouvait spécifier que la cible serait une table au lieu d’une vue :
Comme pour la vue, le comportement par défaut du run est le drop et la réécriture de toute la table. Ce comportement est acceptable pour certaines tables, en général assez légères, mais n’est pas adapté sur des tables très lourdes. Cette gestion est couverte dans la matérialisation incrémentale.
Ephemeral
Dans le cas où l’on a besoin d’étapes intermédiaires de travail pour décomposer un traitement en plusieurs requêtes distinctes, il peut être surdimensionné de créer des vues à chaque fois. En effet des objets n’ayant pas d’intérêt business ne devraient pas polluer le data warehouse.
La matérialisation ephemeral n’a pas d’impact sur le data warehouse, le code des requêtes est traduit en CTE lors de son utilisation comme source dans d’autres requêtes.
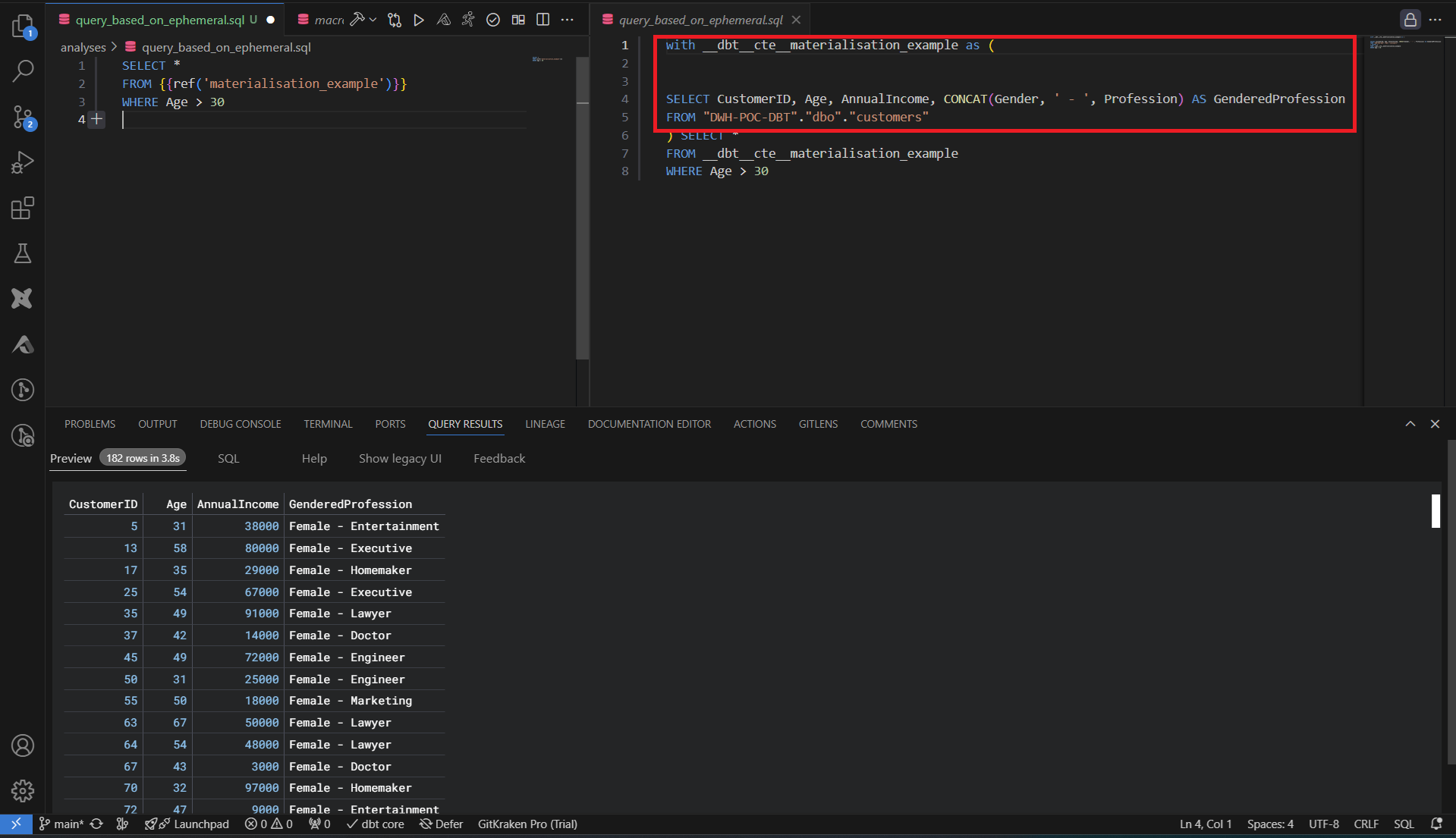
Incremental
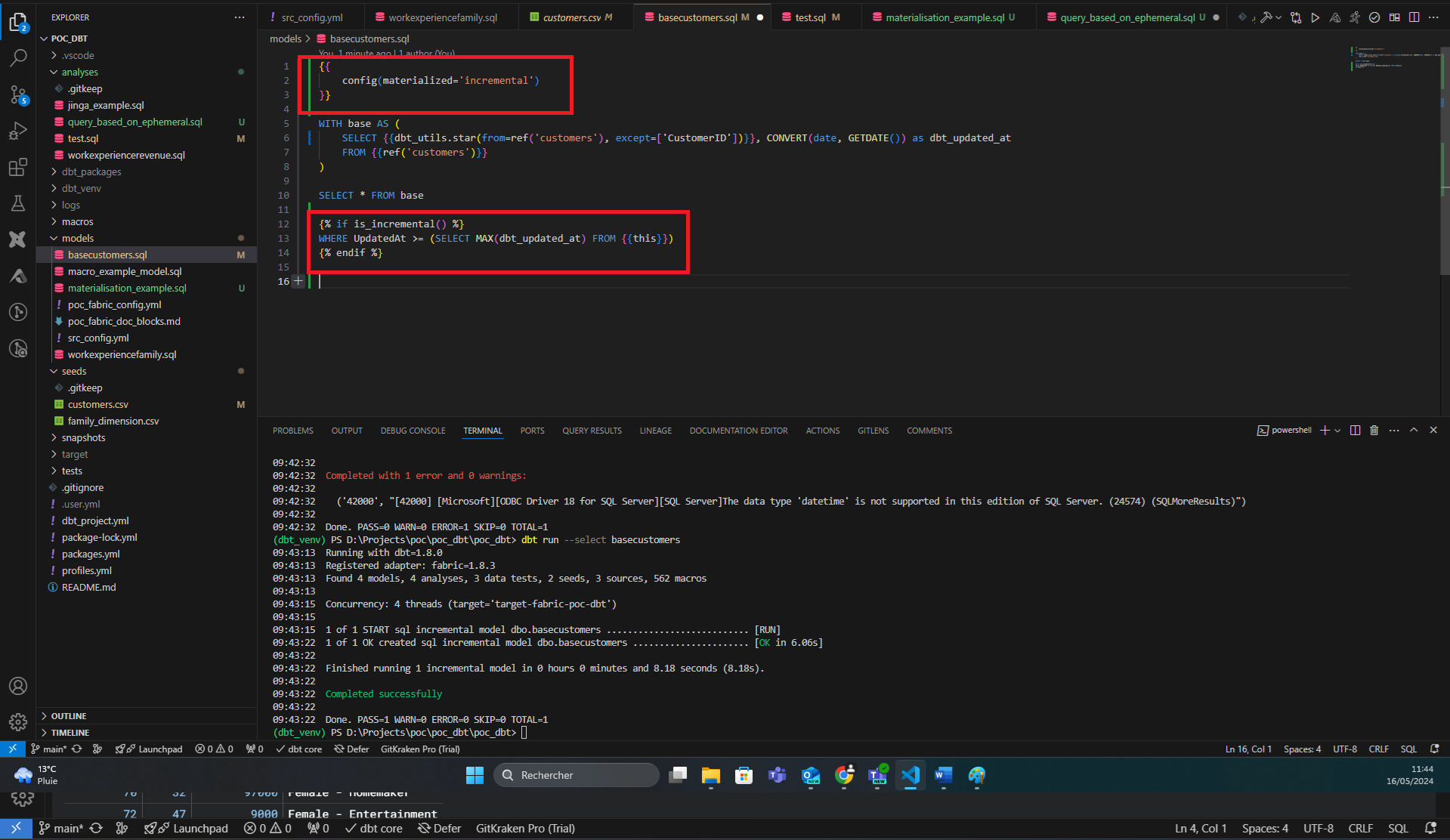
Dans le cas de tables assez lourdes, dont on ne veut pas réécrire la totalité des données à chaque run ou qui serait couteux en performances, on peut utiliser la matérialisation incremental. Cette matérialisation extrait uniquement les données qui sont apparues suivant une condition personnalisable.
En plus de la configuration en en-tête du fichier, on ajoute la condition Jinja sur la fonction is_incremental. Cette fonction retourne True uniquement si on est sur une matérialisation incrémentale, si la table existe déjà (si non on doit de toute façon reprendre tout l’historique) et si nous n’avons pas choisi de run en mode full-refresh (qui force une reprise à 0 des données).
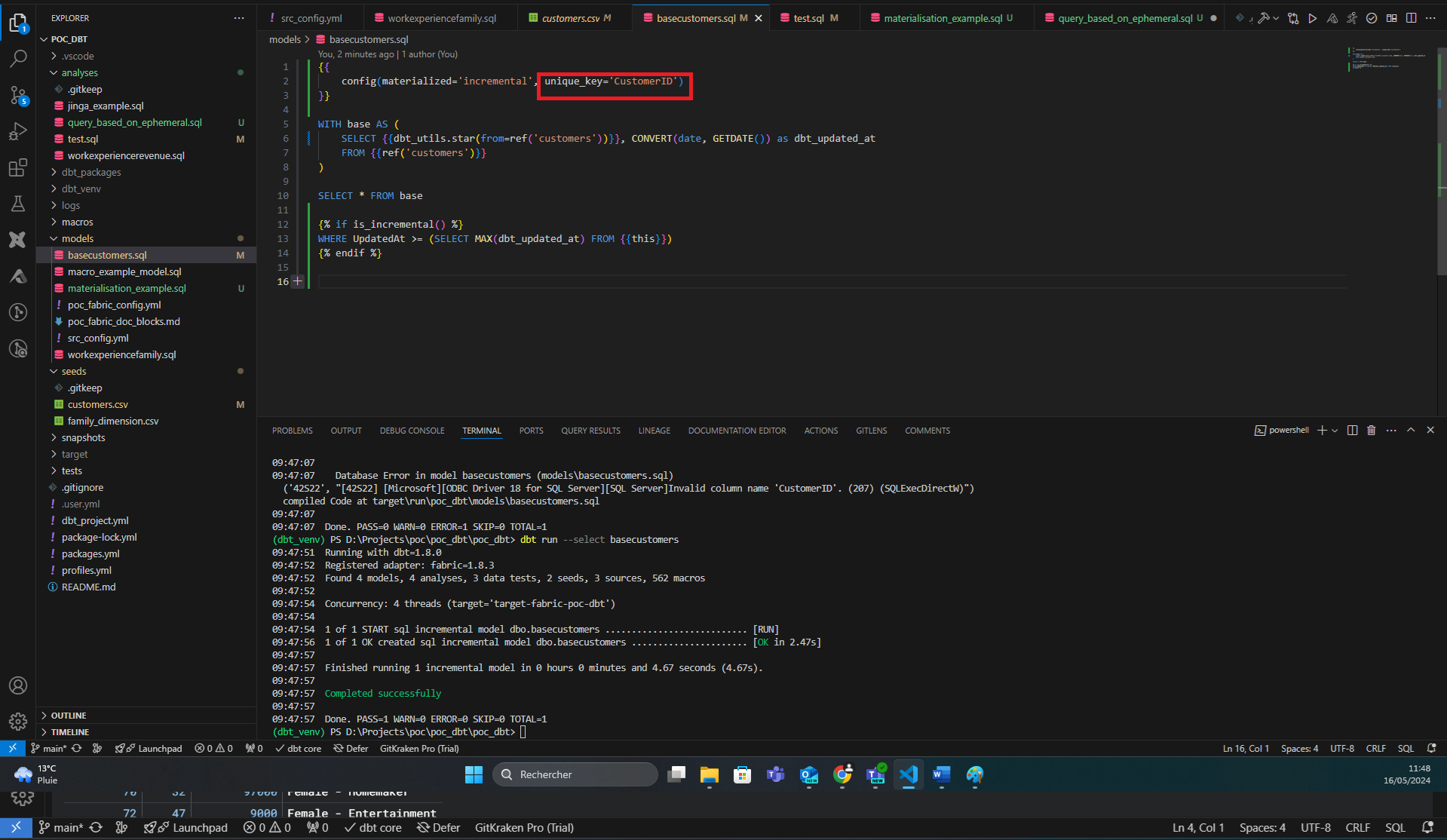
Cette configuration gère l’ajout de nouvelles lignes, mais pas les modifications de lignes déjà présentes. On peut aussi gérer les modifications en précisant quelle colonne fait office d’identifiant. Suivant le data warehouse, l’opération sous-jacente peut être un merge qui effectuera l’insert et l’update en une seule requête, ou en plusieurs.
Snapshot
Faire des updates sur une tables est un premier pas, mais on perd alors l’information de la valeur qu’on a écrasé. En utilisant une mécanique de Slowly Changing Dimension (SCD), on peut garder tout l’historique des modifications.
dbt intègre nativement la gestion des SCD de type 2, où chaque modification entraine la création d’une nouvelle ligne, en précisant pour chaque ligne les dates de début et de fin de validité. Cette fonctionnalité se configure dans la partie snapshot de dbt.
Soit nous avons déjà une colonne datetime pour identifier s’il y a eu des changements (dans notre cas uptated_at) et dans ce cas on utilise la stratégie ‘timestamp’, soit nous ne disposons pas de ce genre de colonne et on choisit la stratégie check.
Dans le premier cas, on spécifie notre colonne de référence, ainsi que la colonne qui est la clé d’unicité. Il suffit de définir la requête en dessous pour finir la configuration du SCD de type 2.
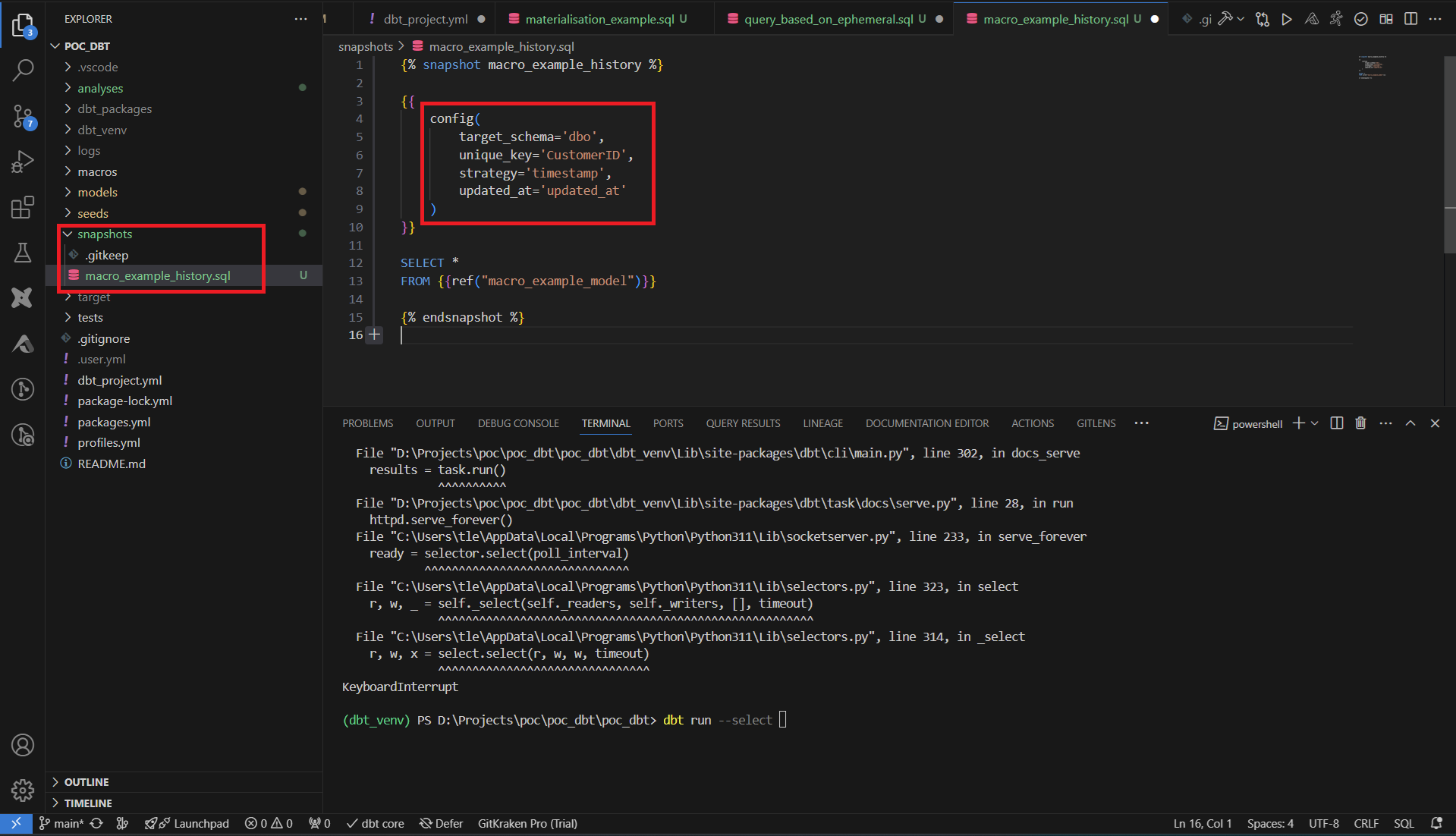
En jouant la commande dbt snapshot, dbt crée automatiquement 4 nouvelles colonnes. Un identifiant interne à dbt, une date de mise à jour, et les 2 colonnes de début et de fin de validité de la ligne.
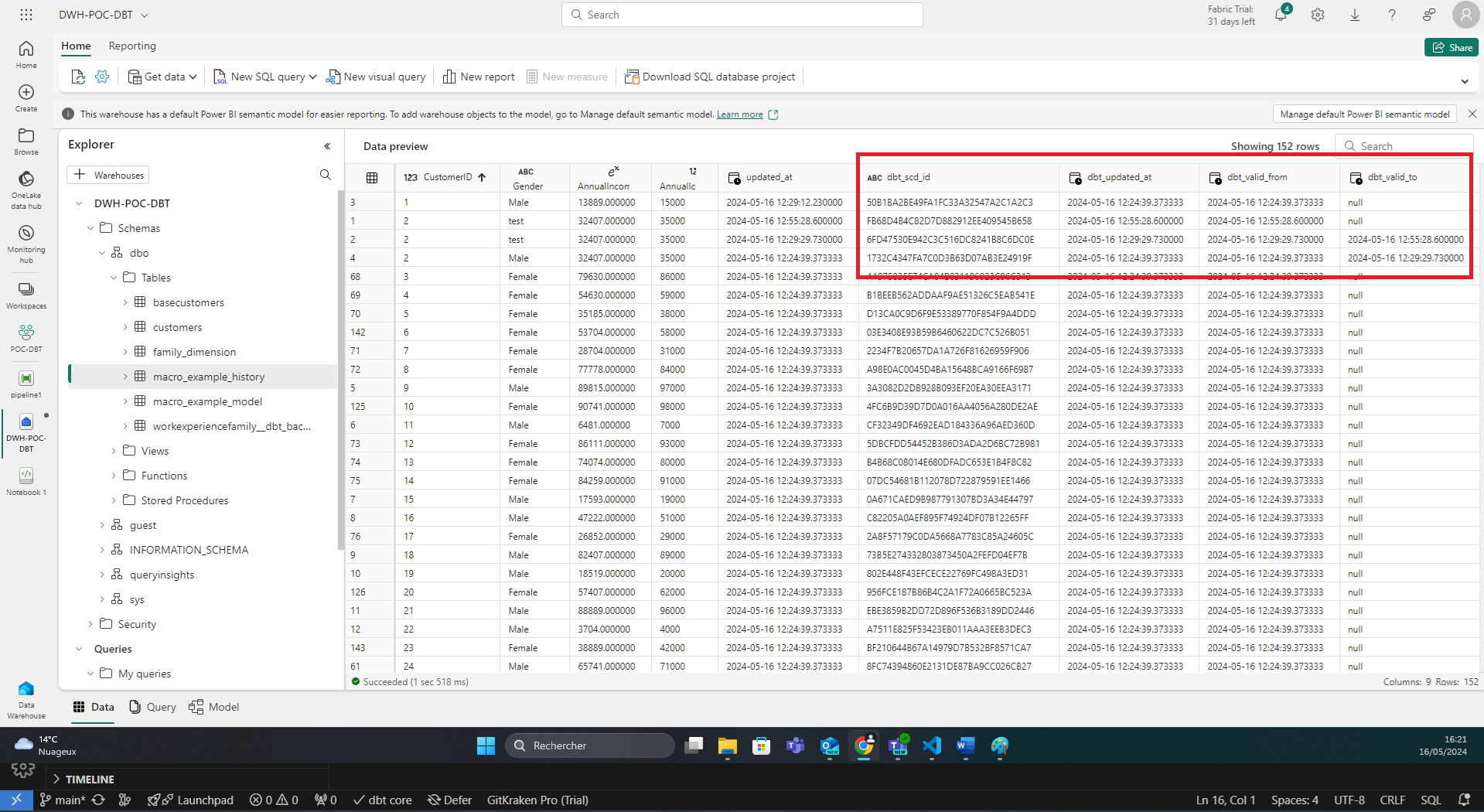
Dans le second cas, on choisit la stratégie check, et on spécifie l’ensemble des colonnes à surveiller. Si une modification apparait dans ces colonnes, la mécanique d’historisation s’activera.
Par défaut si une ligne est absente dans la source, dbt va l’ignorer. On peut ajouter un flag invalidate_hard_deletes, qui indiquera a dbt que les ligne manquantes ont été supprimées.
Gestion des models
Nous avons pu voir dans le paragraphe ‘gestion de la matérialisation’ qu'il est possible d’ajouter de la configuration dans l’en-tête de nos fichiers models. On a également vu dans le paragraphe ‘test unitaires et documentation’ que nous pouvions utiliser des fichiers comme moyen de configuration intermédiaires, entre le fichier de configuration global dbt_project et la configuration unitaire dans chaque fichier.
Ces fichiers intermédiaires peuvent être utilisés pour configurer l’ensemble des propriétés de nos models. Les tests unitaires et la documentation, mais aussi les matérialisations, les contraintes (sur le model ou sur chacune des colonnes), une gestion de version, etc. Enfin il est possible d’jajouter le type de chaque colonne, surtout utilisé lorsque des data contract doivent être respectés
Orchestration et limites de Microsoft Fabric
Jusqu’à présent on jouait les commandes à la main sur notre environnement local. Dans un contexte industriel, on a besoin de schedulers, dont le plus classique pour dbt est airflow pour l’orchestration et les trigger CRON.
Fabric est encore un environnement récent et ne possède actuellement pas de solution native pour répondre à ce besoin d’orchestration. Des contournements existent, en gérant les appels dbt via des notebooks et en orchestrant les notebooks via des pipelines, mais la gestion du versionning du projet dbt sur Microsoft Fabric, et devoir passer par des notebooks Spark ne sont pas des solutions durables.
Les limites de l’intégration de dbt dans Fabric sont donc atteintes lors de l’industrialisation du projet. Microsoft Fabric travaille déjà sur des outils d’intégration de dbt à la plateforme mais ils ne sont pas encore au stade de la Preview. Une des solutions consiste donc à intégrer dbt à Azure Synapse Analytics et de faire une migration lorsque Microsoft Fabric sera mature sur le sujet.
Conclusion
dbt est donc un outil complet, fait pour être couplé à des outils d’ingestion de données et pour servir des données robustes à leur utilisation par la BI.
Son intégration dans la plupart des services Cloud Analytics et sa simplicité de maintenabilité en fait un outil de choix, mais on a vu que des limites étaient atteintes lors de l’intégration dans des plateformes encore jeunes.
Son adoption est facilitée car il peut être intégré dans une chaine de traitement existante sous forme de pilote, et remplacer petit à petit les traitements existants une fois son efficacité prouvée.
