Découverte du Data Wrangler de Microsoft Fabric



Introduction
Dans cet article nous parlerons de l’outil Data Wrangler, disponible sur la partie Notebook de Microsoft Fabric.
Microsoft Fabric est le nouvel outil Data (encore en preview) qui rassemble l’ensemble des outils Data d’Azure, de l’ingestion et transformation des données jusqu’à la data visualisation, en passant entre autres par le temps réel et le Machine Learning. Fabric a pour objectif de faciliter l’accessibilité en unifiant en un seul endroit d’une part les outils, mais aussi les données avec OneLake, la data gouvernance et la gestion des ressources de stockage et de compute.
En plus de proposer une refonte de l’existant, des nouveaux outils et fonctionnalités sont régulièrement ajoutés sur la plupart des briques composant Fabric (Data Factory, Synapse, PowerBi). L’objectif de l’article est de faire découvrir le Data Wrangler, disponible sur la partie Synapse Data Engineering, dans les notebooks.
Le Data Wrangler permet de faciliter la data exploration et le nettoyage des données avec des outils de prévisualisation et des outils no code. On pourra facilement le comparer à l’outil Power Query de PowerBi.
Exemple d’utilisation
Le Data Wrangler permettant de transformer des données, il est nécessaire d’en avoir à disposition. Si vous n’avez pas déjà un Lakehouse, il est possible d’en créer et peupler un nouveau avec des échantillons de données publiques mis à disposition par Microsoft (pour une présentation spécifique de l’ingestion de données dans Fabric : https://blog.atawiz.fr/article/microsoft-fabric-data
Vous pouvez ainsi créer un pipeline de données pour copier les données Samples de votre choix dans un nouveau Lakehouse. Une fois le pipeline exécuté vous avez de quoi tester le Data Wrangler.
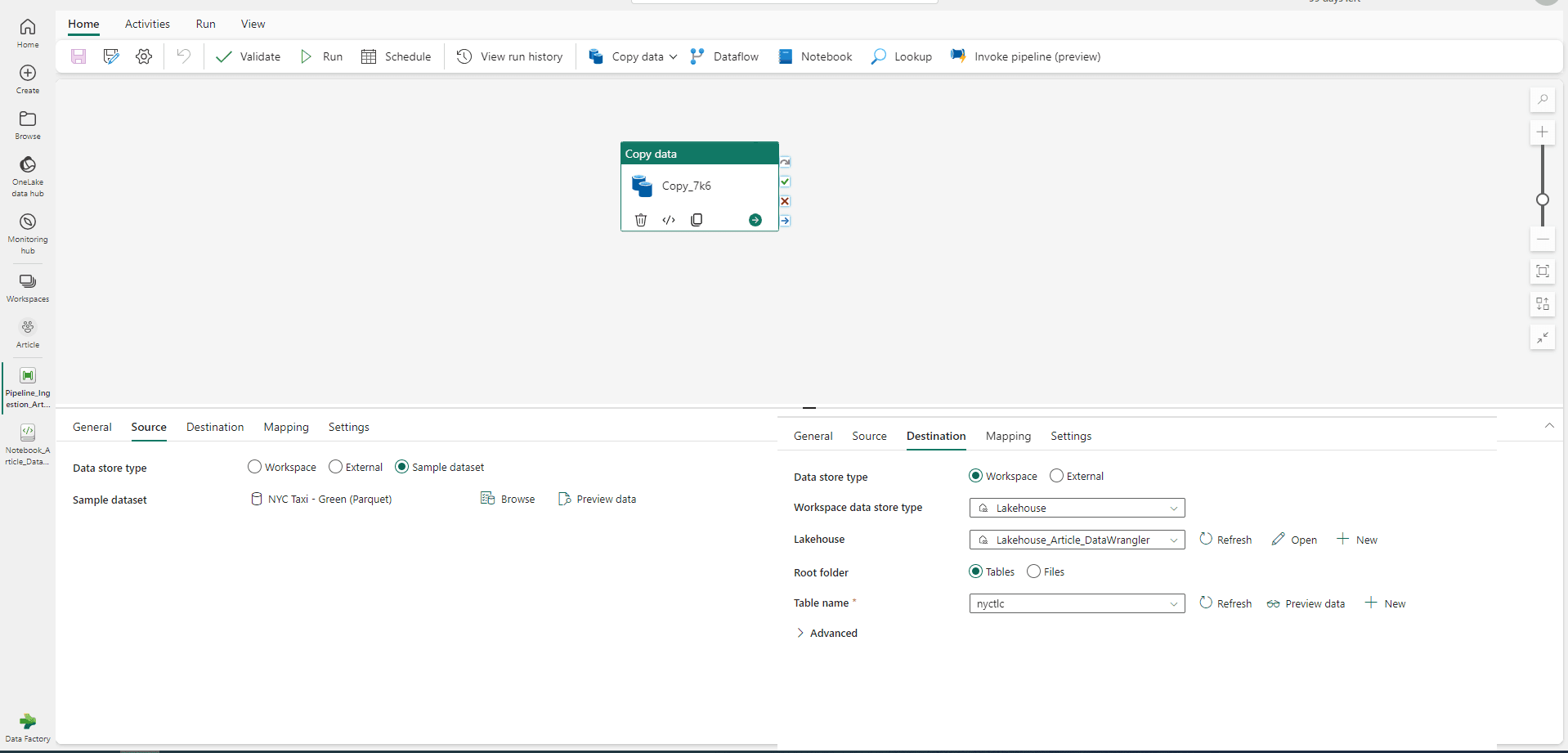
Le Data Wrangler étant un outil originellement destiné aux data analystes, il a été pensé pour les utilisateurs de la bibliothèque Pandas. Il est donc nécessaire de charger ses données sous la forme d’un dataframe Pandas. Il existe une limite par défaut sur Pandas (modifiable dans la configuration de Pandas) sur la taille des dataframes. Ici je n’utilise qu’un échantillon de 100k lignes.

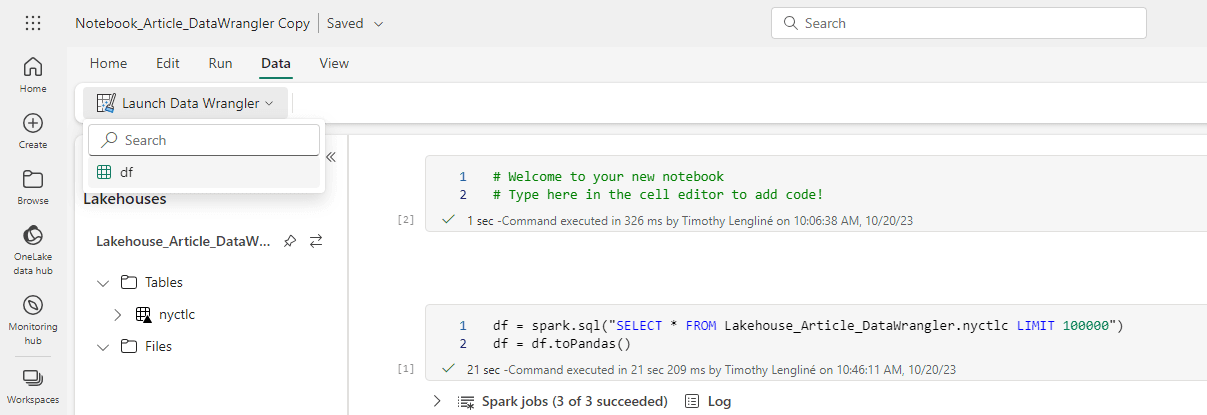
Dans le menu Data, l’option Launch Data Wrangler proposera de s’ouvrir avec un des dataframes Pandas chargés.
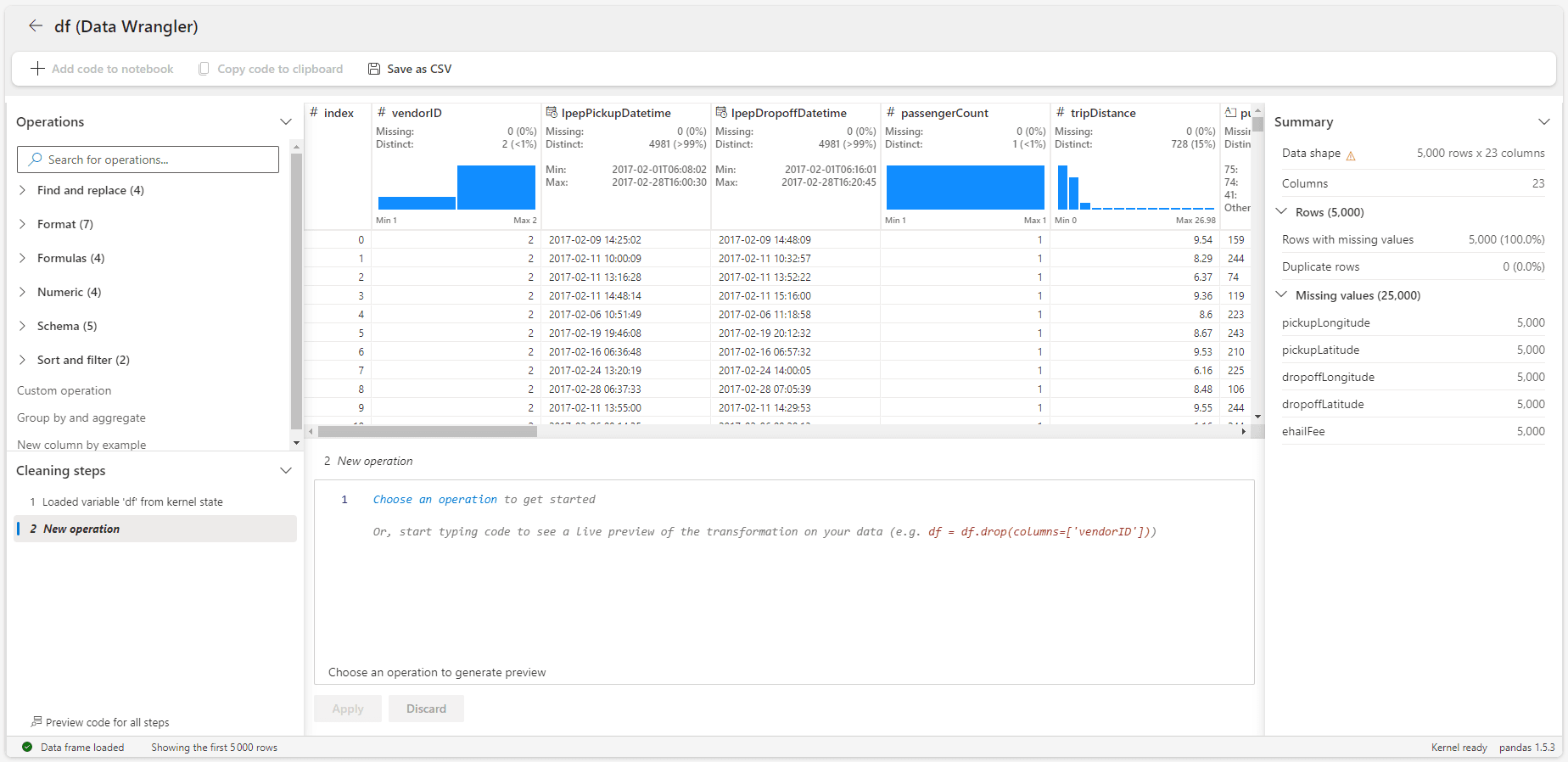
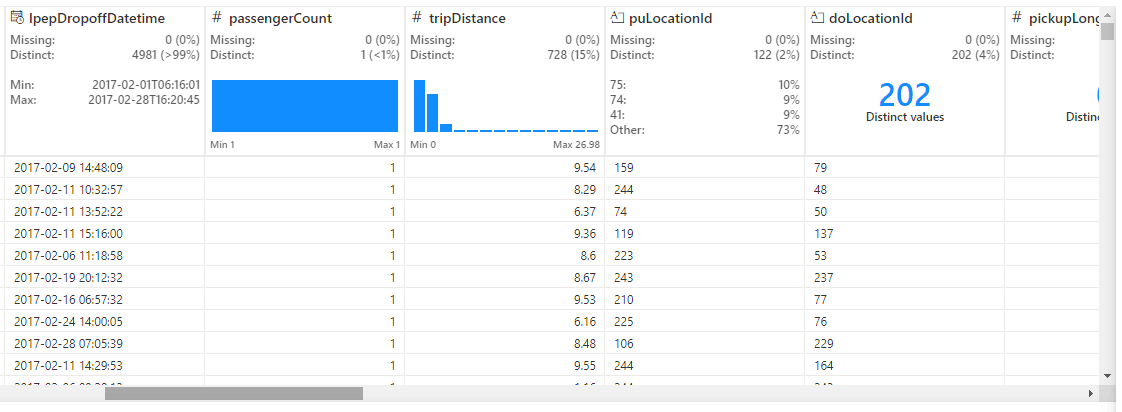
L’interface de Data Wrangler est découpée en 5 blocs.

En haut à gauche on retrouve la liste des opérations disponible actuellement. On y retrouve les opérations classiques de nettoyage de données comme la suppression de doublons, de valeurs manquantes ou de changement de format. On retrouve aussi les opérations d’agrégation ou de normalisation des valeurs.
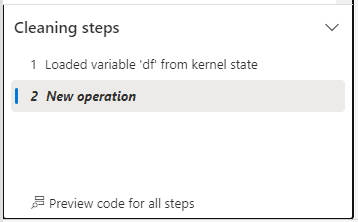
En dessous on a l’historique des opérations effectuées sur le dataframe chargé (ici encore aucune modification). Ce panneau permet de revenir une ou plusieurs opérations en arrière facilement en cliquant sur une étape précédente. Cela permet aussi d’avoir en un coup d’œil l’ensemble des opérations appliquées.
En haut au centre on a la prévisualisation du dataframe. Après chaque opération la prévisualisation se met à jour. Au-dessus de chaque colonne, quelques statistiques sur la qualité des données nous permettent de savoir où nous en sommes sans que l’on ait à vérifier manuellement. Ces statistiques sont également mises à jour après chaque opération.
En dessous on a un éditeur de code, qui se prérempli lors de la sélection d’une opération. On a donc la traduction en code Pandas de ce qui est appliqué, et on peut modifier directement le code si on souhaite faire des ajustements manuellement. Il est ensuite possible d’appliquer l’opération si le résultat sur la prévisualisation au-dessus nous convient, ou d’annuler l’opération en cours.

Enfin à droite on a un résumé avec quelques statistiques sur le dataframe globale. On remarque que sur le dataframe de 100k lignes, seul un échantillon de 5k est en prévisualisation dans le Data Wrangler.
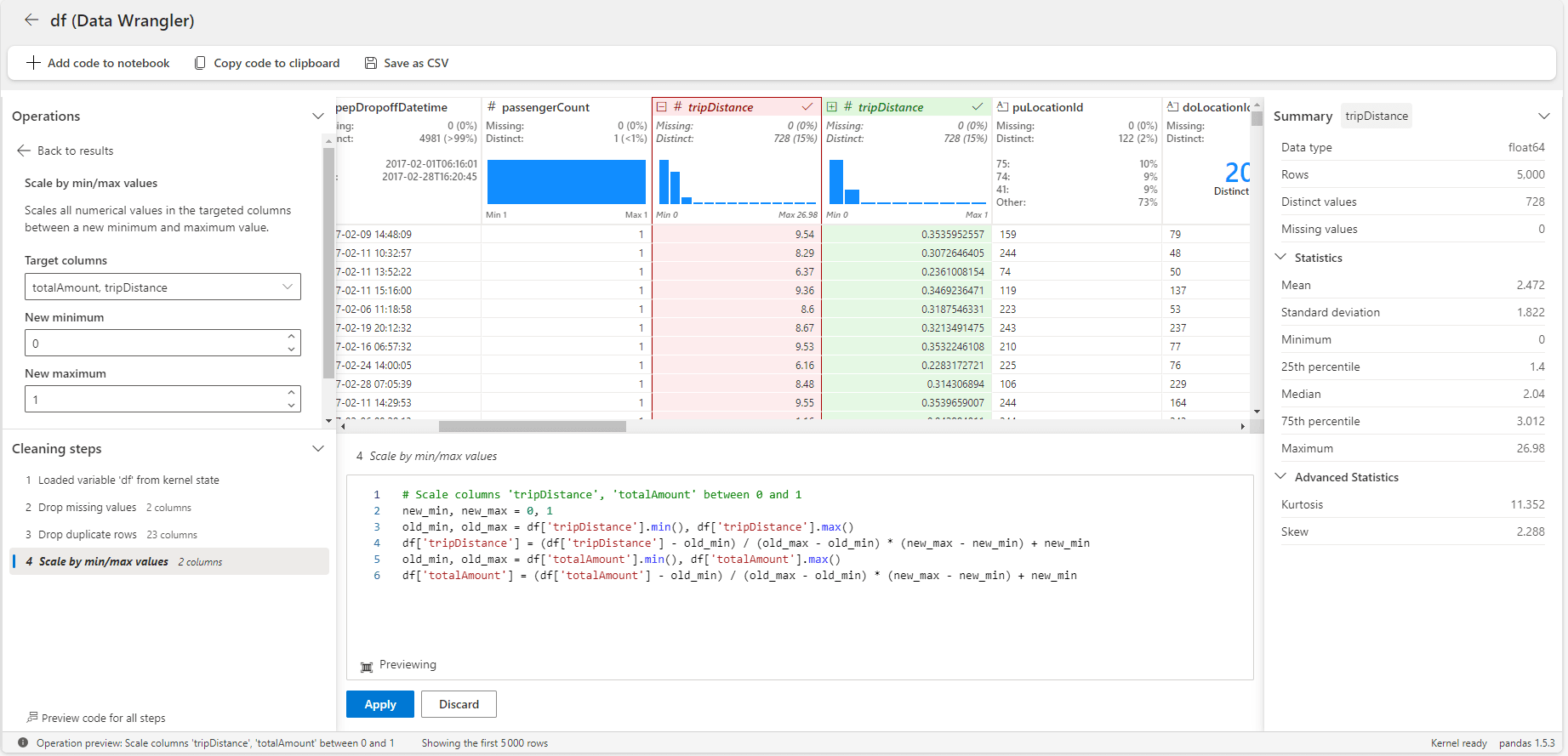
Après quelques opérations appliquées à notre dataframe, on obtient le résultat suivant :
On retrouve les différentes opérations déjà effectuées en bas à gauche, on a une prévisualisation de l’opération sélectionnée sur le dataframe, et on a le code associé juste en dessous.
Dans cet exemple on souhaite changer le format du DateTime. Il suffit d’inscrire le résultat souhaité pour que le parsing reconnaisse automatiquement le code à appliquer. Par exemple ici je souhaite avoir la date et l’heure dans des ordres différents, avec des séparateurs différents.
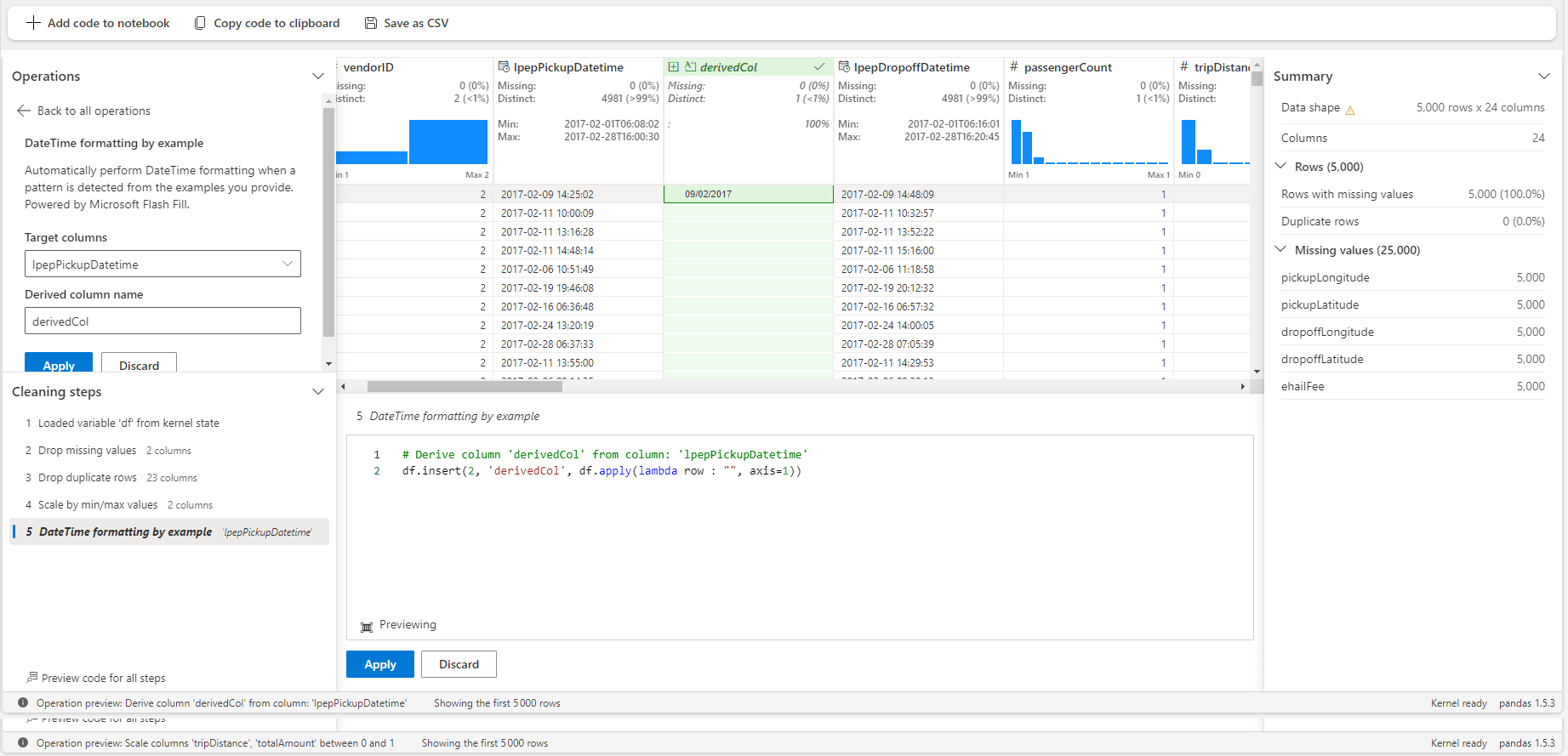
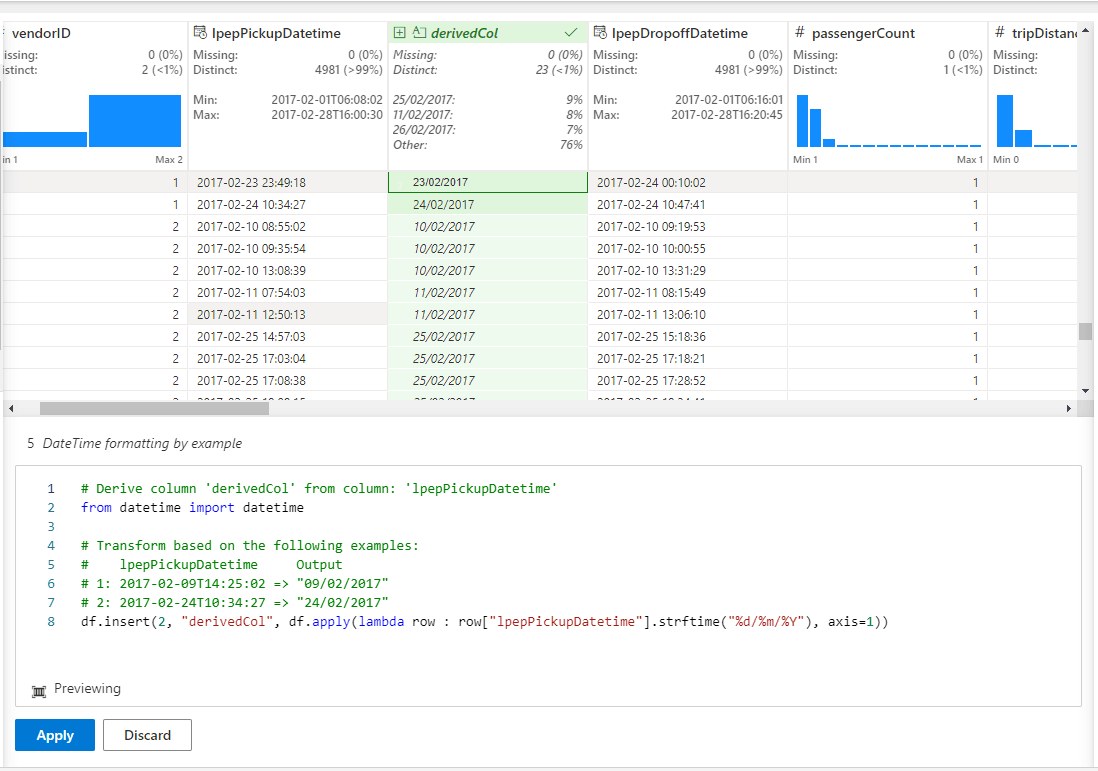
Parfois l’exemple n’est pas correctement parsé et il est nécessaire de faire la modification à la main dans le bloc d’édition de code. Une fois le nouveau code interprété, la prévisualisation du dataframe est mise à jour avec vos transformations manuelles.
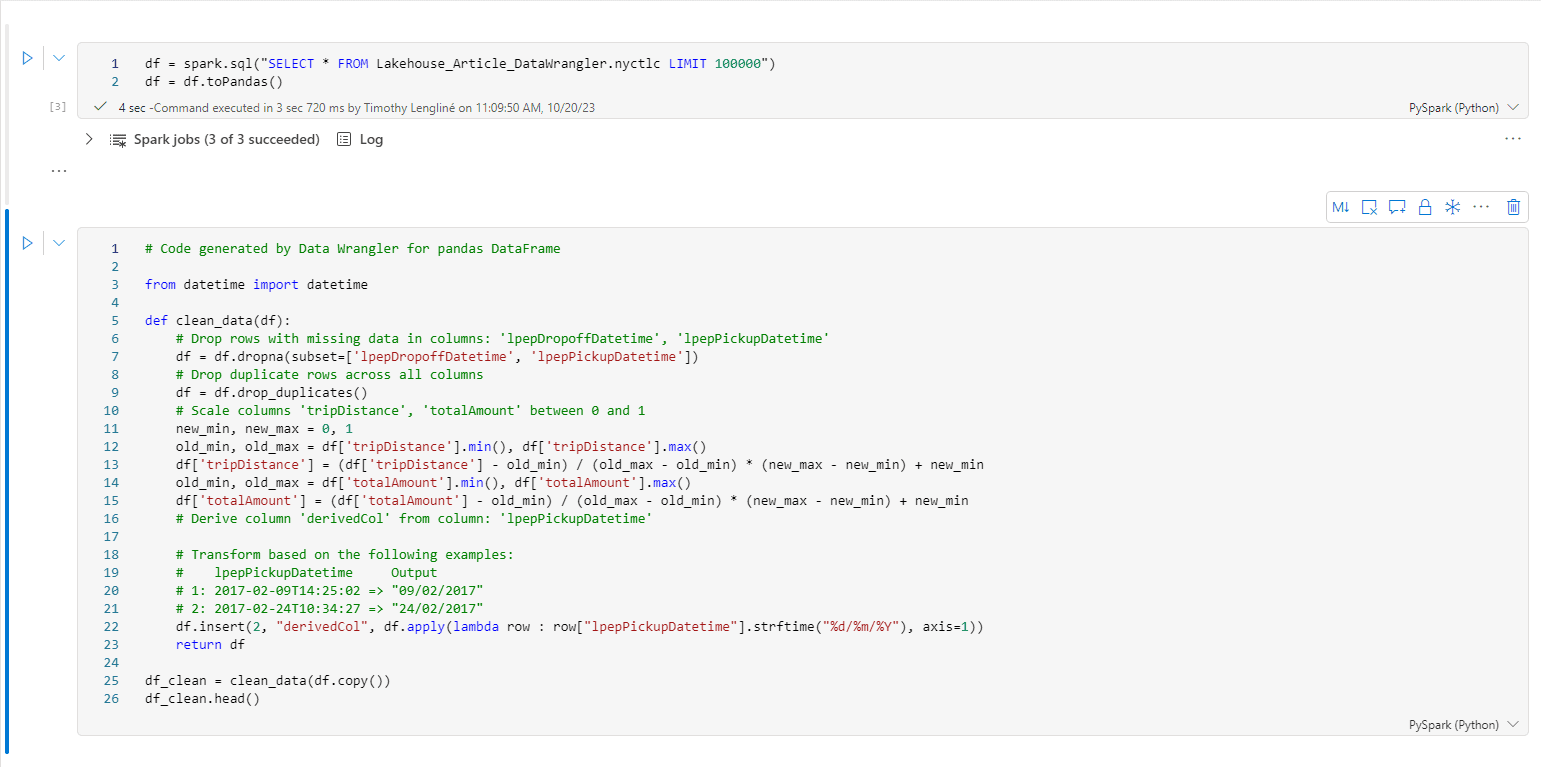
Une fois satisfait des opérations effectuées, on peut choisir de faire un export de la totalité du dataframe avec les opérations du Data Wrangler appliquées dessus. On peut aussi soit copier le code de toutes les opérations dans le presse-papier, ou l’envoyer directement dans le notebook.

Une fois le code sur notre notebook, on constate que les opérations sont proprement commentées et inclues dans une fonction.
Limites de l’outil
Il me semble que l’outil possède néanmoins plusieurs limites.
Cet outil s’appliquant sur des notebooks fonctionnant avec Spark, il est probable que les utilisateurs de notebook soient habitués à manipuler des dataframes PySpark, qui ne sont actuellement pas supportés par le Data Wrangler. Pour utiliser l’outil, il faudrait donc faire passer les dataframes en Pandas, puis les repasser en PySpark, sans compter qu’il pourrait y avoir des incompatibilités aux moment des changements (les bins de Pandas ne sont pas nativement supportés par PySpark par exemple).
Le Data Wrangler ne prend qu’un échantillon de 5k lignes. Cela limite l’outil à des manipulations ne nécessitant pas la totalité du dataframe pour avoir du sens. Certains filtres pourraient résulter d’un dataframe vide si l’échantillon ne contient pas les lignes souhaitées par exemple (ce qui sur un dataframe originale de plusieurs millions de lignes n’est pas impossible).
Enfin la gestion de l’historique des opérations effectuées sur le dataframe est restreinte à la « session » du Data Wrangler en cours. Si on avait appliqué un filtre sur le dataframe avant de le charger dans le Data Wrangler, ce filtre n’apparaitrait pas dans la liste des opérations effectuées.
Cette limite implique également qu’une fois une série d’opérations validées dans le Data Wrangler est poussé sur le notebook, il n’est plus possible de rouvrir cette série d’opération pour les modifier. Le Data Wrangler proposera uniquement d’ouvrir soit le dataframe d’originale, soit le dataframe transformé, mais les considèrera comme des nouveaux dataframes, sans possibilité de revenir sur une opération intermédiaire.
Conclusion
Le Data Wrangler semble être une fonctionnalité très réussie car aide à gagner du temps sur des opérations souvent très chronophages. De plus il est à la fois simple d’utilisation, notamment grâce à son système de prévisualisation, et par sa ressemblance à Power Query (de PowerBi) il devrait être facilement être adhérer par toute une communauté.
De plus la génération de code à partir d’outil no-code permet aussi aux utilisateurs non familiers avec Python ou Pandas d’être efficace rapidement sur un projet.
L’outil a des limites et ne sera pas utilisé dans toutes les situations et par tous les utilisateurs de Notebooks mais Microsoft à déjà prévu des améliorations avant la sortie officielle du Data Wrangler (compatibilité avec les dataframes PySpark).
Ces améliorations sont également présentes à l’échelle du projet Fabric, et Microsoft à publier récemment le calendrier prévisionnel des releases sur chacune des briques composants Fabric https://learn.microsoft.com/en-us/fabric/release-plan/
