Tout savoir sur les transactions ACID avec Spark, Delta Lake et Databricks.



Que veut-on dire par ACID ?
Une transaction est une succession d’opérations de lecture et d’écriture sur une base de données effectuées grâce à un système de gestion de bases de données (SGBD). Pour qu’une transaction soit fiable, elle doit vérifier les quatre propriétés ACID.
A pour atomicité
C’est la propriété du tout ou rien. Si une transaction est démarrée, elle doit s’effectuer au complet ou être abandonnée. Il ne peut y avoir une transaction effectuée en partiel. Si un cas d’interruption intervient au moment de la transaction, toutes les opérations de la même transaction seront annulées.
C pour cohérence
Cette propriété nous garantit que les données ont un état constamment valide : cet état doit être lu en même temps par toutes les applications ou transactions en concurrence. Elle garantit également qu’aucune des contraintes d’intégrité des données n’ait été violée. Chaque modification faite par une transaction doit impérativement respecter ces contraintes.
Exemple :
- Contrainte de domaine : spécifie les valeurs et le type de données d’un attribut.
- Contrainte de clé : définit une colonne, ou un groupe de colonnes, comme identifiant unique de ligne.
- Contrainte d’intégrité référentielle : cette contrainte garantit qu’un attribut ne peut prendre une valeur que si celle-ci est existante comme clé d’une autre relation.
I pour isolation
Lorsque plus d’une transaction est en cours d’exécution, elles ne doivent pas interférer les unes avec les autres. Les transactions sont isolées et toute lecture ou écriture d’une transaction n’impacte pas les opérations d’une autre. On compte deux façons de gérer l’isolation et la concurrence :
Schéma de transaction pessimiste : une ligne est verrouillée lorsqu’elle est en cours de modification par une transaction. Aucune autre transaction ne peut la lire ou l’écrire tant que la première n’a pas COMMIT ou ROLLBACK. À adopter lorsqu’il y a peu de concurrence et que le temps des verrous n’est pas trop long.
Schéma de transaction optimiste : ici pas de verrouillage. Juste avant d’écrire le résultat, la transaction vérifie s’il y a eu des changements et des conflits sur la ligne depuis sa lecture. Si c’est avéré, l’écriture ne sera pas faite et les transactions en confrontation seront abandonnées.
D pour durabilité
Il signifie que tout changement effectué sur une base de données doit être permanent et ne peut être perdu.
Un Delta Lake, qu’est-ce que c’est ?
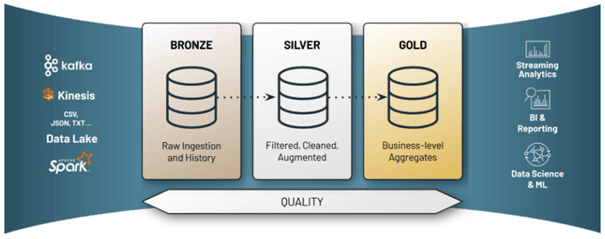
Le Delta Lake se présente comme une couche de stockage au-dessus d’un Data Lake. Il est compatible avec Apache Spark et unifie en une même table du traitement en streaming et en batch. Il stocke les données en format parquet, ce qui permet la validation du schéma et une meilleure qualité de la donnée.
Il est recommandé de respecter le schéma de pipeline de transformation Delta. Ce schéma effectue trois groupes d’opérations :
- Bronze : Prend en entrée des données sources et les sauvegarde dans une table en gardant le format original.
- Silver : Transforme les données des tables du précédent groupe.
- Gold : Fournit des tables qui répondent à des besoins métiers précis.
Delta Lake permet aussi une meilleure gestion de l’historique grâce aux fichiers « Transactional Log » qui le composent. Ces fichiers de log contiennent toutes les opérations effectuées sur nos tables. Ainsi, nous pouvons facilement revenir à des versions antérieures.
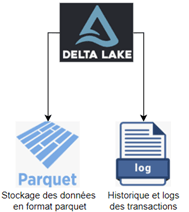
Contrairement à un Data Lake conventionnel, Delta Lake nous garantit les propriétés ACID. Les données sont donc plus fiables. L’intégration de ces propriétés est l’un des majeurs atouts qu’apporte cette couche de stockage.
Les propriétés ACID sont toutes garanties par Delta
Initialement les opérations avec Spark ne sont pas atomiques et ne vérifient donc pas la première propriété ACID. Si l’on souhaite réaliser un Overwrite, alors c’est toute la table qui est vidée pour insérer les nouvelles données. C’est ce que l’on peut d’ailleurs lire dans la documentation officielle :
https://spark.apache.org/docs/latest/sql-data-sources-load-save-functions.html#save-modes
De même pour la cohérence. Si nous prenons l’exemple d’un Overwrite, un temps écoulé est présent entre la suppression et l’écriture de la nouvelle donnée.
Imaginons maintenant que la suppression se fasse avec succès mais qu’une exception demeure lors de l’écriture. Les données seront tout simplement perdues ! Les données restent tout de même incohérentes même si l’étape de l’écriture s’est déroulée avec succès car pendant ce temps mort, celles-ci n’ont pas un statut valide.
Pendant qu’une opération d’écriture est en cours d’exécution, Spark ne verrouille pas la ligne ou le fichier en question, par conséquent le statut des données peut être changé entre temps par une autre opération qui s’exécute en parallèle. Il existe des Tasks commit et des jobs commit sur Spark mais pas des commits au niveau des opérations.
Enfin, Spark ne garantit pas un stockage durable car nous ne disposons pas d’un commit strict.
En tant que Data Engineer, tôt ou tard vous aurez affaire à ce genre de situation. Heureusement que Delta est là pour vous. Voyons comment est-ce que le Delta Lake nous offre une compliance ACID.
Imaginons les trois opérations ci-dessous en mode OVERWRITE sur une table Delta :

Comme l’opération N°1 est passée avec succès, un fichier de log a été créé et contient les informations la concernant : des informations comme les métadonnées et les actions faites (l’opération WRITE en mode OVERWRITE dans notre cas). Il indique également le chemin et le nom de parquet sauvegardé.
Quant à l’opération N°2, comme elle a échoué, un fichier parquet est créé mais aucune information n’est loguée dans le répertoire des logs (_delta_log). À cette étape, si nous étions sur Spark sans la couche Delta, les données auraient été perdues. Mais ici, grâce à Delta Lake, les données sont toujours disponibles dans le fichier parquet de l’opération N°1. Cependant, dans la mesure où nous avons deux fichiers parquets (Opérations N°1 et N°2) et que le deuxième est corrompu, lequel de ces deux sera lu ? Est-ce que les données lues seront cohérentes ? C’est simple : lorsque l’API Spark lit les données, il ne va pas s’intéresser aux parquets qui n’ont pas de fichiers logs.
Nous allons comprendre ce concept en rajoutant une troisième opération qui va cette fois-ci passer avec succès. Un deuxième fichier de log est donc créé.
Pour que l’API Spark sache quelles sont les données à lire et lesquelles sont à ignorer, elle va d’abord lire les fichiers logs. Dans notre cas, nous aurons des informations qui ressemblent à ce qui suit :
- 00000000000000000001.json:
->{“add”:{“ part-00000-600fb8bc-f0e2-41a3-9dea-0ba4262b6fb.c000.snappy.parquet” …
- 00000000000000000002.json:
-> {“add”:{“ part-00000-f8cee99f-1b92-4a6f-b06b-e0833a27cfb5.c000.snappy.parquet” …
-> {“remove”:{“ part-00000-600fb8bc-f0e2-41a3-9dea-d0ba4262b6fb.c000.snappy.parquet ” …
Ainsi, le fichier parquet de l’opération N3 est le seul fichier valide qui contient les données cohérentes de la table. Les deux autres parquets sont ignorés.
Vous vous posez peut-être la question et vous vous dites qu’il doit certainement y avoir un nombre conséquent de fichiers créés après plusieurs opérations et que cela n’est pas optimal.
Deux solutions s’offrent à vous pour pallier cela. La première est la commande « VACUUM » qui permet de supprimer les anciens fichiers en spécifiant le nombre de jours dans le passé. La deuxième est « OPTIMIZE » qui permet de clustrer et d’ordonner les données, mais aussi de grouper des petits fichiers en un seul.
Quant à la consistance des données, Delta Lake applique le schéma transactionnel optimiste et passe par les étapes ci-dessous :
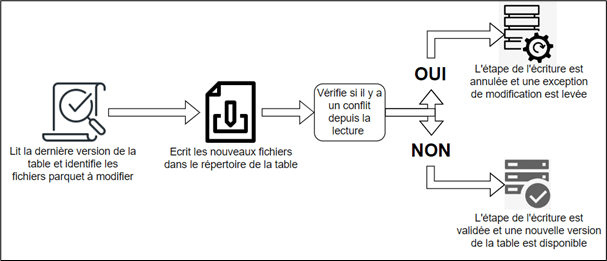
Pour ce qui est de l’isolation, Delta Lake avec Databricks propose deux niveaux d’isolation :
- WriteSerializable qui veut dire que seules les opérations d’écriture sont faites en série, l’une après l’autre. Dans ce cas d’isolation il se peut qu’on lise des données qui ne sont pas conformes à l’historique, qui sont disponibles dans les fichiers parquets mais pas encore dans le Delta Log. Ce cas de figure arrive quand les opérations de lecture ne se font pas en série.
- Serializable est le niveau le plus strict en comparaison du précédent. Dans ce cas, la lecture et l’écriture se font en série. On ne risque pas de lire des données qui ne sont pas encore commit.
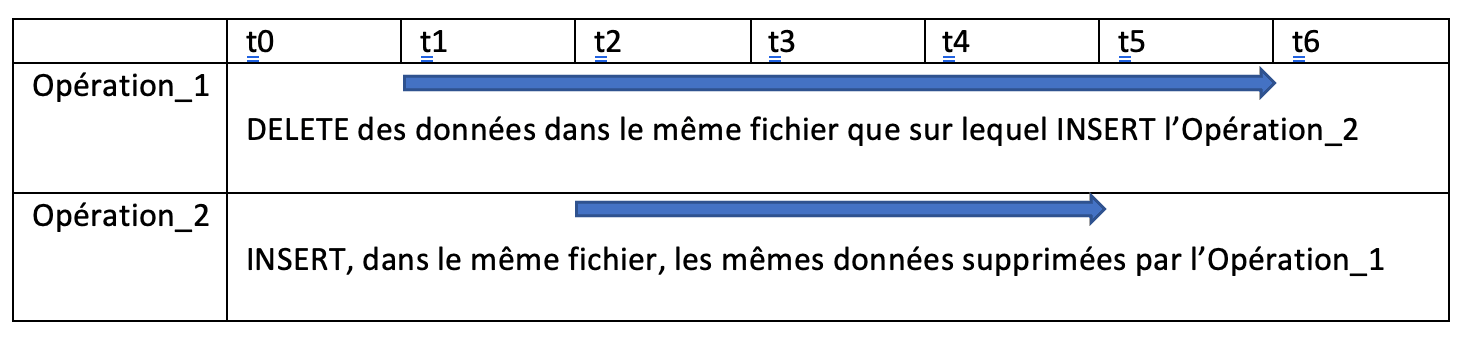
Ci-dessous deux opérations sur un même fichier d’une même table. Dans le cas du premier niveau d’isolation, entre t2-T5 une opération de lecture peut lire les données insérées par l’Opération_2 alors que les mêmes données ont commencé à être supprimées à t1 par l’Opération_1. À l’inverse, avec le niveau Serializable, en aucun cas ces données peuvent être lues entre t1-t6.
Pour éviter qu’il y ait des conflits entre des transactions, l’autre solution est de partitionner les données au niveau des colonnes de la tables où nous souhaitons faire des opérations. Mais attention, si ces tables sont à cardinalité élevée, on se retrouvera avec un grand nombre de dossiers et de fichiers. Le risque est donc de perdre en performance.
Enfin pour la dernière propriété ACID, la durabilité, Delta Lake hérite de la redondance et de la disponibilité qu’offre le stockage dans le cloud.
Pour conclure
Concrètement, Delta est venu changer les habitudes et la façon dont on traite les données avec Spark et sur les Data Lakes.
Les problèmes résolus par ACID sont nombreux et nous pouvons citer :
- Une cohérence des données. L’insertion n’échoue pas à cause des conflits même lorsque l’écriture est faite simultanément depuis plusieurs sources.
- Possibilité de modifier les données en une seule transaction atomique et avec une syntaxe simple. Ceci est possible grâce à l’opération «MERGE INTO».
- Les changements ne sont pas commit tant que le job n’a pas fini son exécution avec succès.
- Traitement des données, d’une même table, en batch et en streaming.
- Possibilité de travailler sur les anciennes versions des tables.
