Optimiser les performances de rapports Power Bi



Introduction
L’article précédent nous as donné des pistes pour identifier quel rapport pouvait causer des problèmes de performances, dans cet article nous nous concentrerons sur les façons de l’optimiser.
Une fois une idée du rapport, de la page ou même du visuel que l’on souhaite améliorer, voir l’article précédent, plusieurs outils sont à notre disposition pour nous aider à agir concrètement.
Dans cet article nous couvrirons l’utilisation de Best Practice Analyzer pour améliorer la qualité du rapport de façon général, Vertipaq Analyzer pour optimiser le modèle de données et DAX Studio pour nous aider à modifier et tester rapidement des mesures et requêtes tout en évitant les régressions.
Troubleshooting dans Power Bi Desktop
Directement dans Power Bi Desktop, via la fonctionnalité « Perf Analyzer », on peut avoir une idée assez fine des problèmes de performances, et ainsi nous aider à prioriser nos corrections. La présentation et l’utilisation de cette fonctionnalité est détaillé dans l’article précédent.
Performance Analyzer permet d’enregistrer une série d’action d’un utilisateur, souvent un simple rafraichissement des visuels, pour en obtenir la liste des requêtes qui ont été exécutées.
Lors d’un chargement anormalement long des visuels, il y a 2 points de vigilance à étudier : y a-t-il un trop grand nombre de visuel, et les requêtes DAX sont-elles trop longues à s’exécuter.
Pour vérifier si les performances sont fortement impactées par le nombre de visuel, on peut trier les lignes par l’ordre d’exécution et de regarder les dernières lignes. Si pour ces lignes la valeur « Other » est très haute alors cela signifie que ces requêtes ont été mises en file en attendant la fin de traitement de premiers visuels. Ainsi on gagnerait beaucoup à avoir moins de visuels. Pour cela on peut par exemple préférer utiliser une matrice pour afficher plusieurs KPIs dans plusieurs colonnes (1 seul visuel), plutôt que plusieurs petits visuels comportant chacun 1 seul KPI.
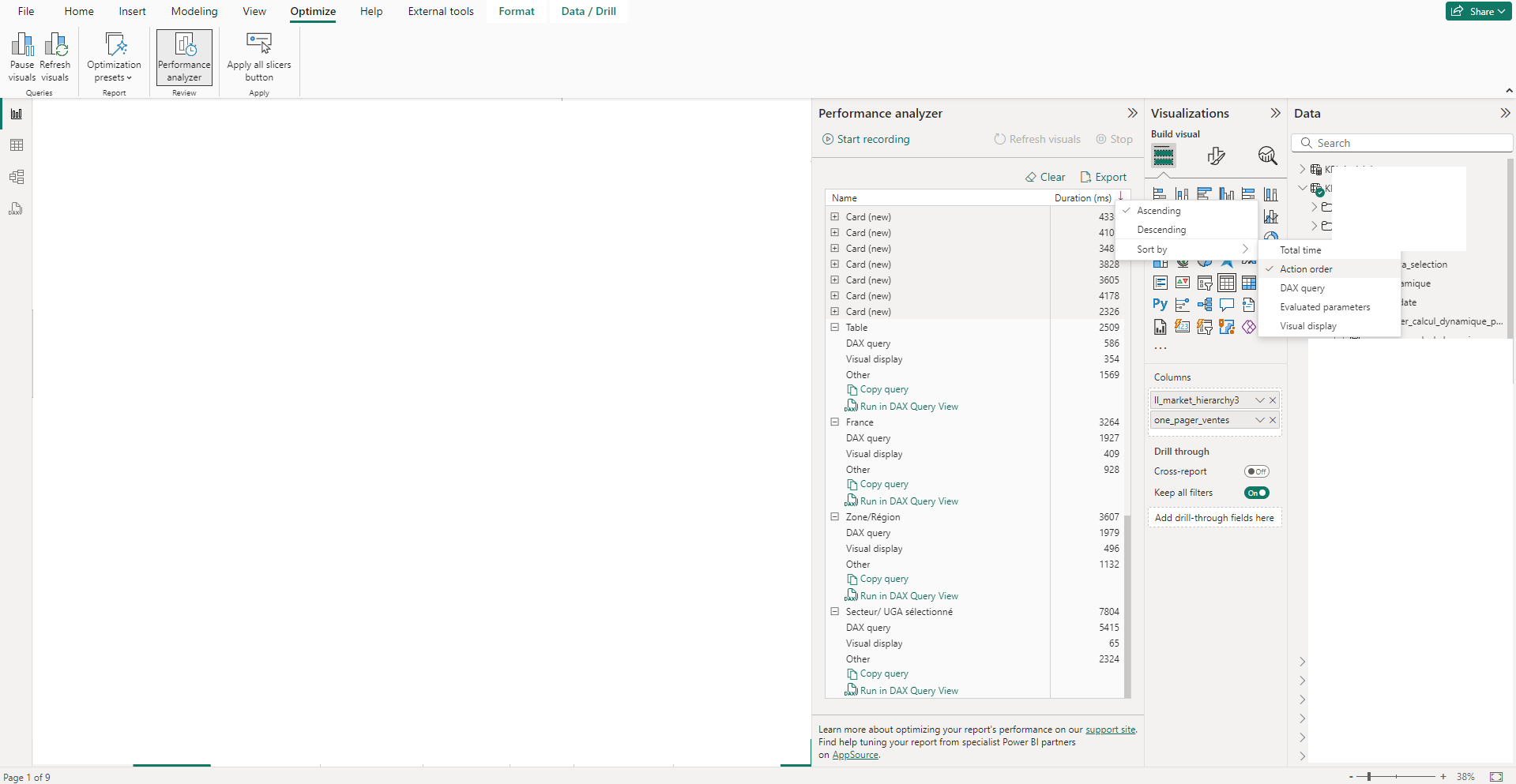
En triant les lignes par temps de requêtes DAX, on peut accéder aux requêtes dont le DAX a été le plus long à exécuter. Si ces temps sont anormalement longs, ce sont ces requêtes qui pourraient être les premières à être optimiser.
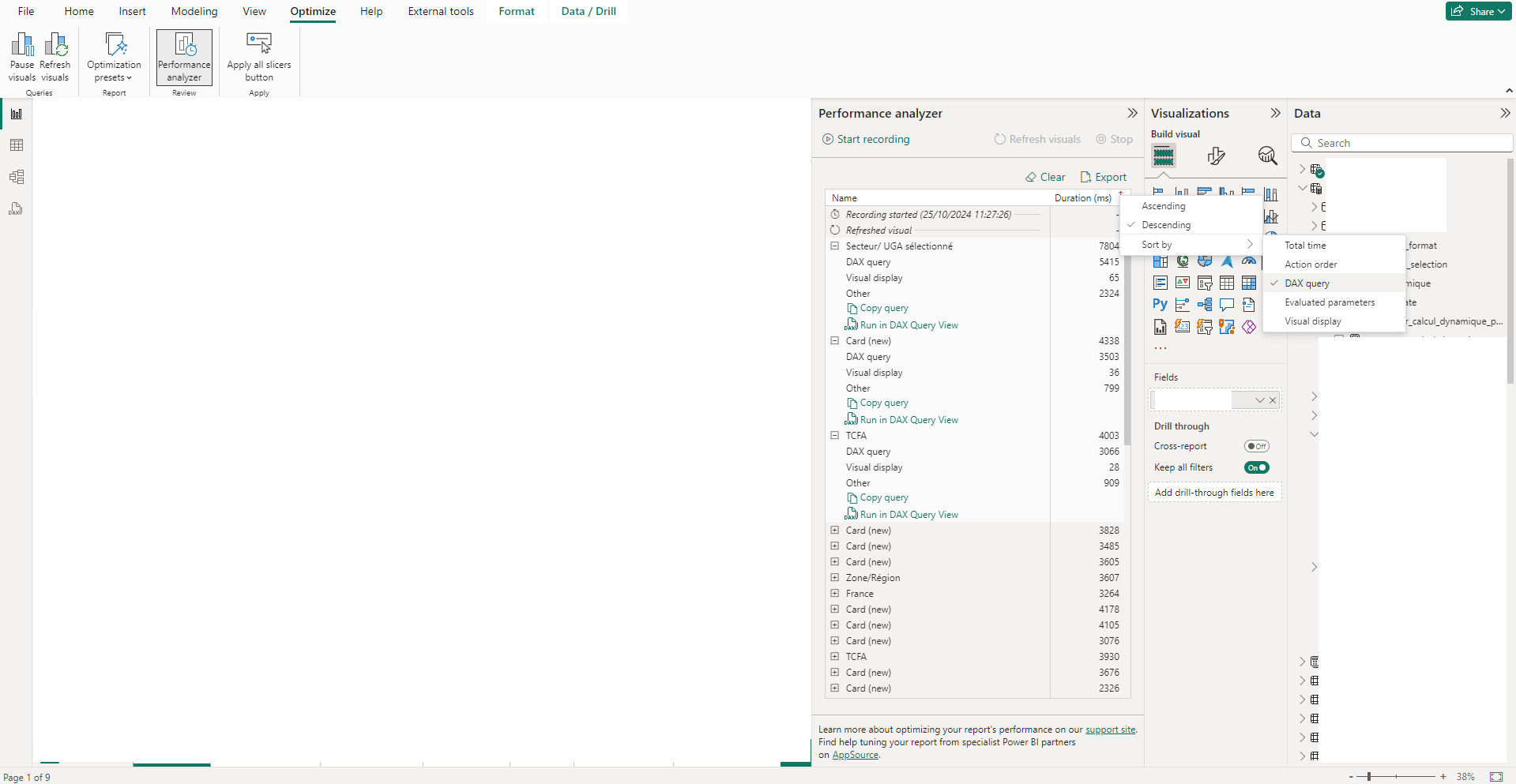
Pour cela on se servira des outils présentés ci-dessous pour nous aider.
Best Practices Analyzer (BPA)
A quoi sert BPA ?
BPA est un outil intégré à Tabular Editor. Outil gratuit en version 2, et payant en version 3 qui offre plus de fonctionnalités, elles ne seront pas présentées dans cet article car la version gratuite nous sera suffisante.
On donne à BPA une suite de règles, les bonnes pratiques qu’on souhaite appliquer à notre projet, et lors de l’import d’un projet dans Tabular Editor, BPA passera au crible le projet à travers son dictionnaire de règles.
On obtient alors l’ensemble de règles enfreintes. Si la définition des règles le précise, on a leur niveau de criticité, une catégorie associée (performance, maintenance, …) pour simplifier la priorisation de la résolution des problèmes. On peut faire le parallèle avec l’outil SonarQube, utilisé pour le développement (JS, Python, etc.)
Comment l’installer
Pour avoir BPA, il suffit d’installer Tabular Editor. Une fois installé, en ouvrant le rapport dans Power Bi Desktop, on a l’option Tabular Editor dans l’onglet « External Tools », qui ouvre Tabular Editor. Dans Tabular Editor, pour accéder à la partie BPA, il faut aller dans l’onglet « Tools », Best Pratices Editor est alors proposé.
Si vous venez d’installer Tabular Editor, il n’y pas encore de règles d’importées dans BPA, la liste de règles et d’erreurs sera donc vide. Il faut donc importer votre liste de règles. Plutôt que de la rédiger à partir de zéro, il existe des listes de règles reconnues comme pertinentes pour les projets Power Bi disponibles sur Github.
Dans notre exemple on prend cette liste de règles, qu’on pourra ensuite modifier pour l’adapter au mieux au projet. Pour importer la liste de règles, le tutoriel propose de l’importer dynamiquement via le panneau C# script en utilisant le script du ReadMe du repository Github.
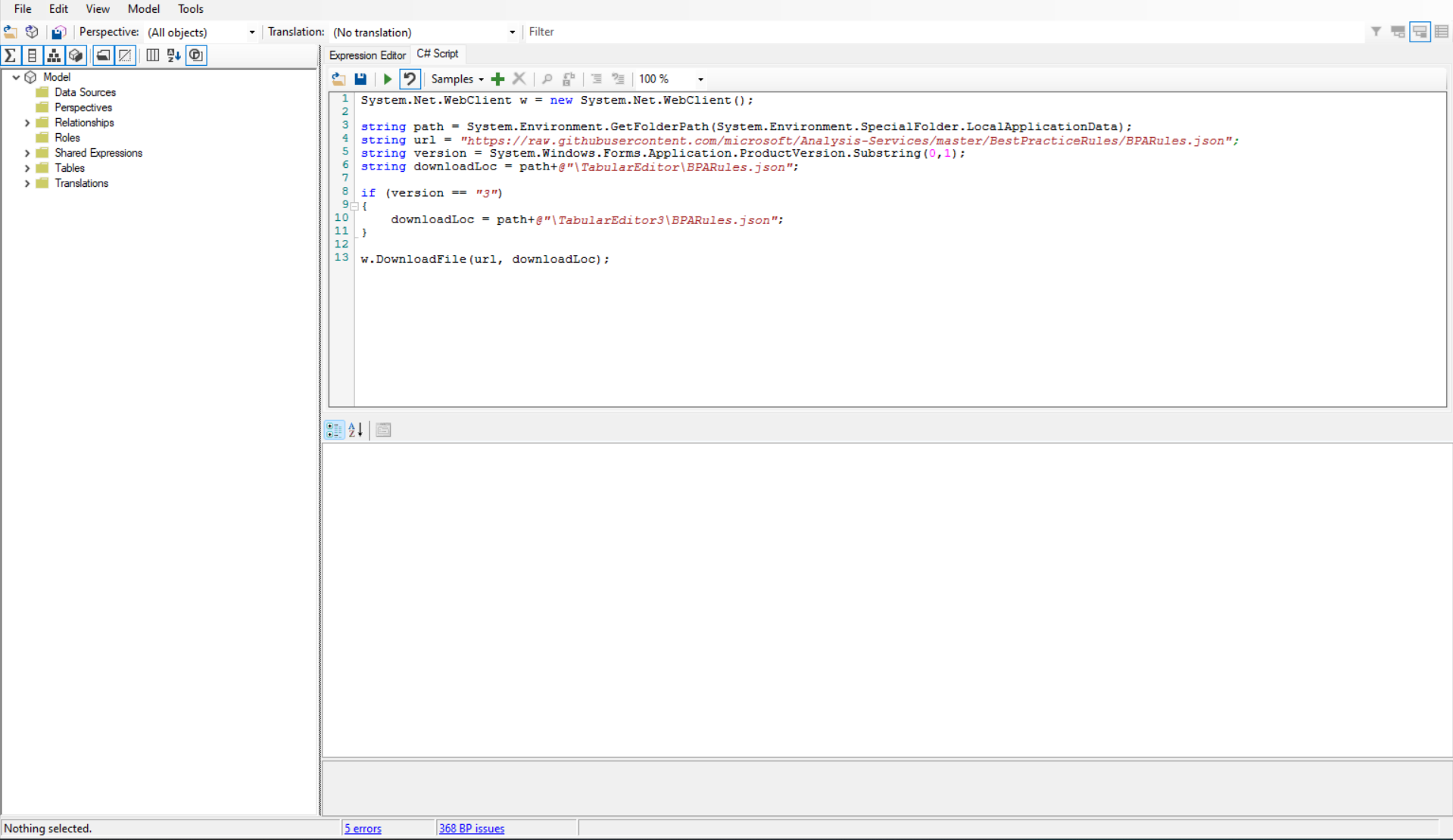
Comment s’en servir
Une fois les règles importées, il faudra relancer l’application pour que Tabular Editor traite le projet avec les nouvelles règles. On peut voir le nombre d’infractions à nos règles en bas de l’écran. Ces règles seront mises à jour automatiquement après chaque action de notre part sur le projet.
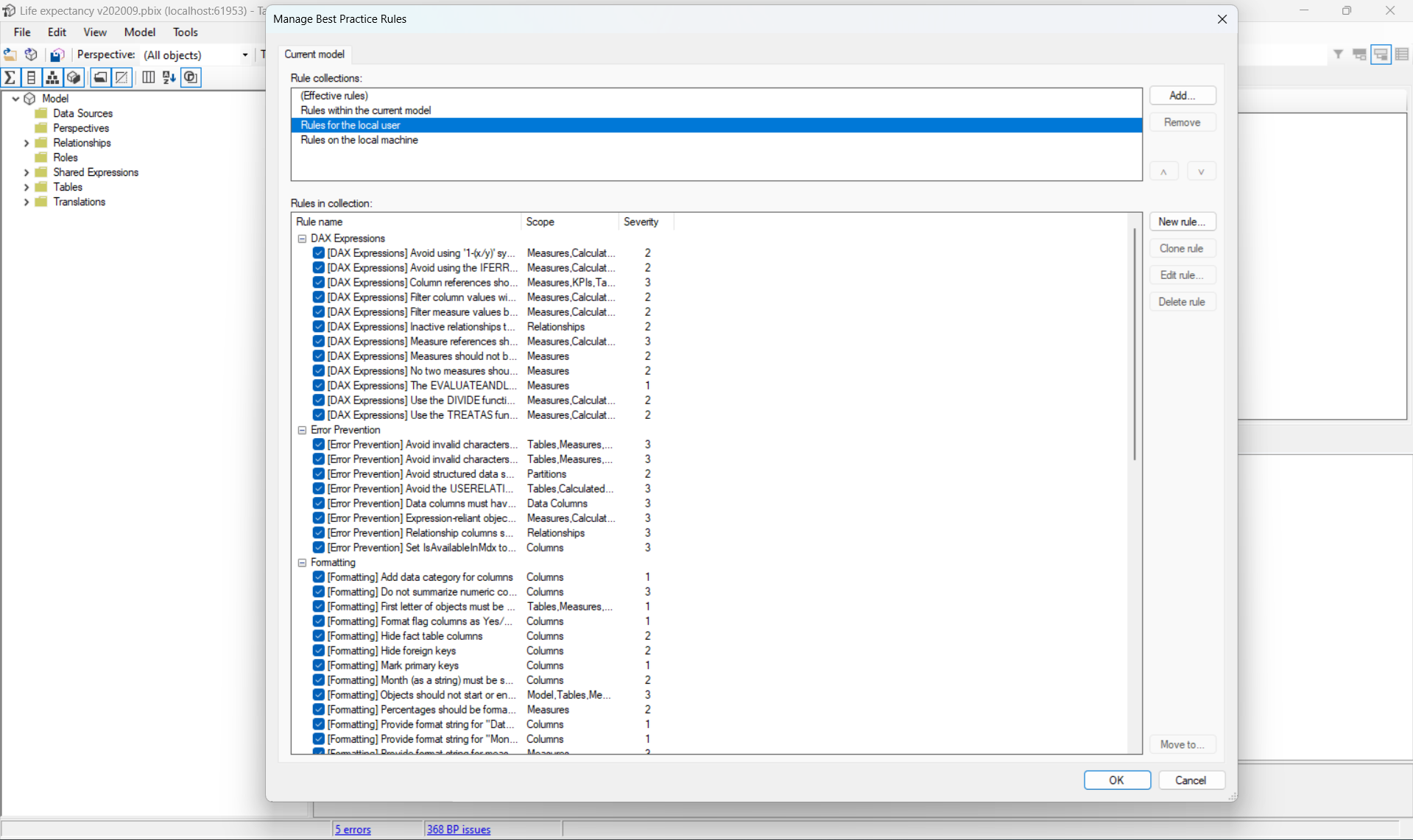
En cliquant sur le nombre d’infractions ou via le panneau Best Practices Analyzer dans l’onglet Tools, on a la liste détaillée des infractions. En double cliquant sur une ligne, l’item en infraction s��’ouvrira dans Tabular Editor, afin qu’on puisse consulter sa définition et éventuellement la modifier pour résoudre le problème.
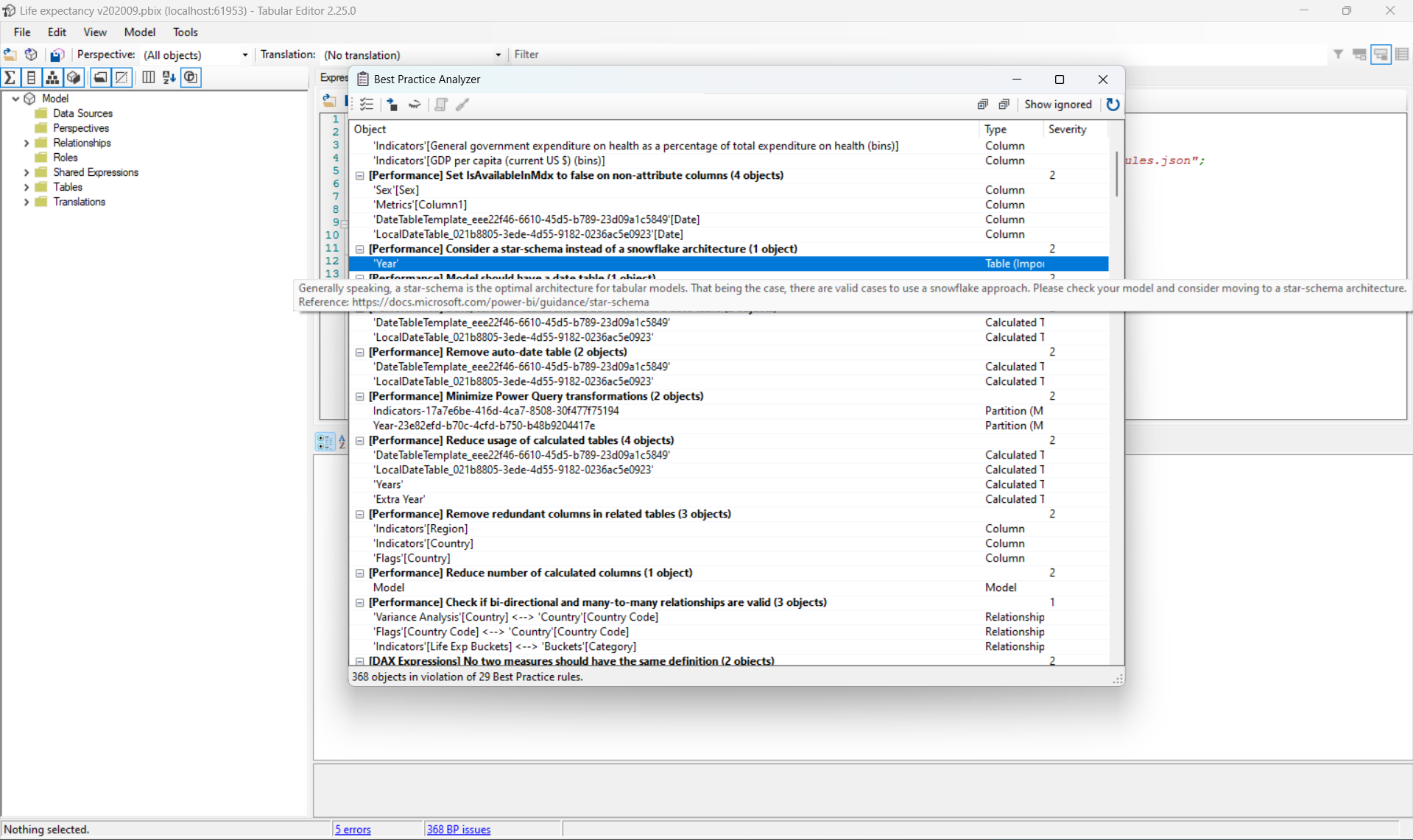
En faisant un clic droit sur une ligne, on a le choix d’ignorer l’infraction, par exemple dans le cas où le jeu de règles est très générique et certaines règles ne s’appliquent pas sur ce projet, mais on peut également demander à BPA de générer un fix au problème.
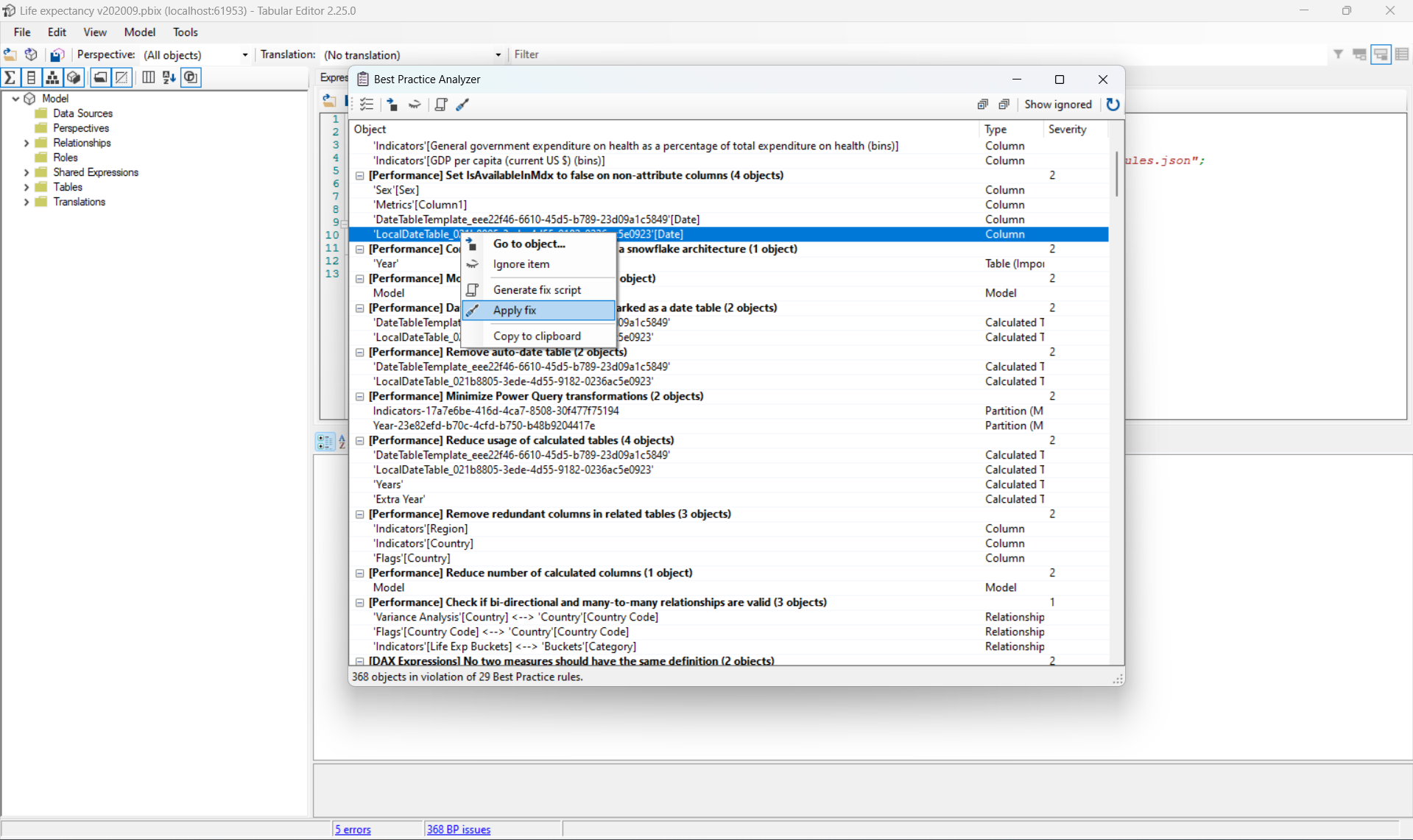
Il est conseillé de ne pas l’appliquer automatiquement en faisant « apply fix » (sauf pour les problèmes les plus simples à résoudre), mais plutôt de le faire manuellement en récupérant le fix avec « generate fix » script et en l’exécutant via le panneau C# script qu’après avoir compris ce que le code généré faisait.
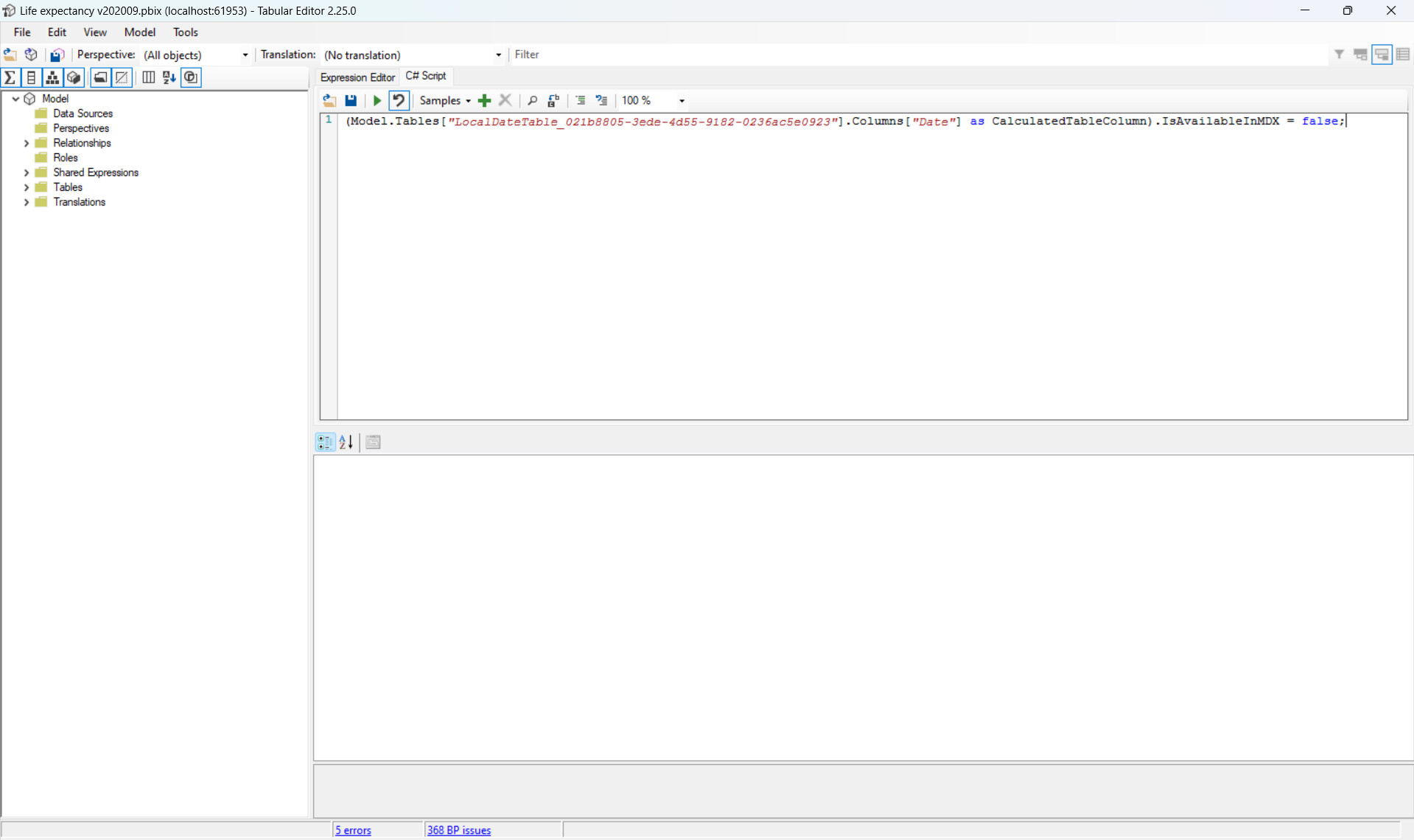
L’utilisation de BPA est une bonne première étape car grandement automatisée, il permet d’identifier et de résoudre rapidement des problèmes sur l’ensemble du projet.
Vertipaq Analyzer
Installation et présentation de l’outil
Vertipaq Analyzer est un fichier Excel auto-suffisant mais est maintenant intégré nativement dans DAX Studio. Pour l’utiliser dans DAX Studio il suffit de charger des données dans DAX Studio et dans l’onglet « Advanced », cliquer sur « View Metrics » et « Read statistics from data » pour charger les données en cours dans Vertipaq. Le détail de ces étapes est présenté dans l’article précèdent.
Vertipaq Analyzer va fournir des statistiques sur tous les objets du projet. Les plus importantes seront celles concernant les tables et colonnes utilise (taille, cardinalité, etc.)
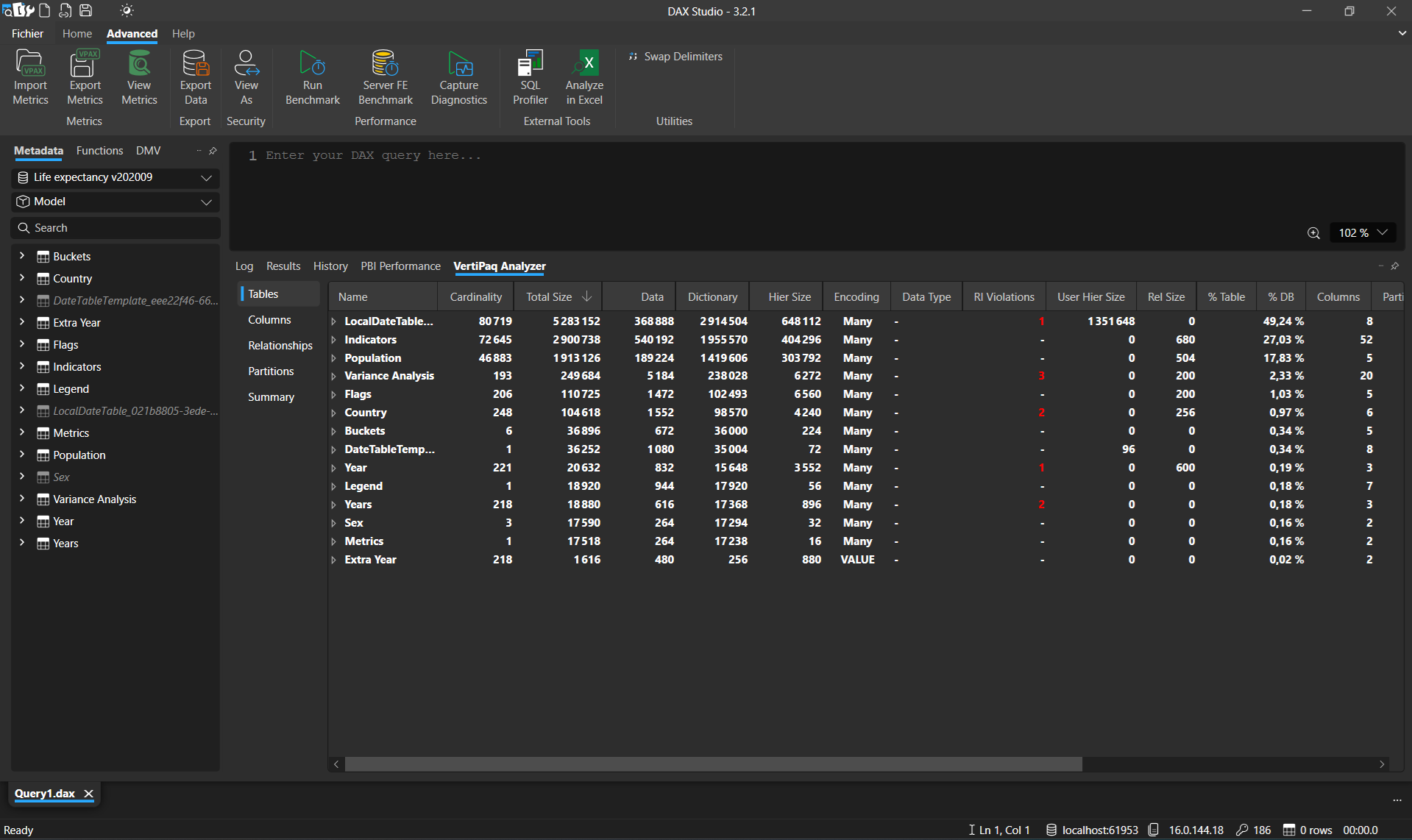
Quoi identifier / comment améliorer
L’objectif est de diminuer la taille du modèle. Plusieurs axes d’amélioration sont possibles :
- On peut privilégier travailler sur une vue ne contenant qu’une partie de l’historique de notre table de fait plutôt que sur sa totalité par exemple. Moins de lignes seront alors à scanner lors de requêtes.
- On peut gagner de l’espace en ne travaillant qu’avec des tables ou vues où toutes les colonnes sont indispensables. Chaque colonne remontée qui ne l’est pas est de la donnée qui prendra du temps à charger pour rien. De plus Power Bi effectue des tâches « cachées » d’optimisation sur les données du rapport, pour être certains que ces tâches ne se concentrent que sur des parties utiles du projet il faut ainsi en retirer toutes les colonnes inutiles.
- Comme au point précédent, pour diriger l’optimisation de Power Bi vers les parties les plus importantes, on peut réduire son périmètre en utilisant des types de colonnes restrictifs. De plus ce genre de type de colonne est souvent aussi plus léger que les colonnes plus génériques, ce qui contribue à l’optimisation du chargement des données.
Afin de maximiser l’impact des optimisations, on travaille de la plus grosse table à la plus petite.
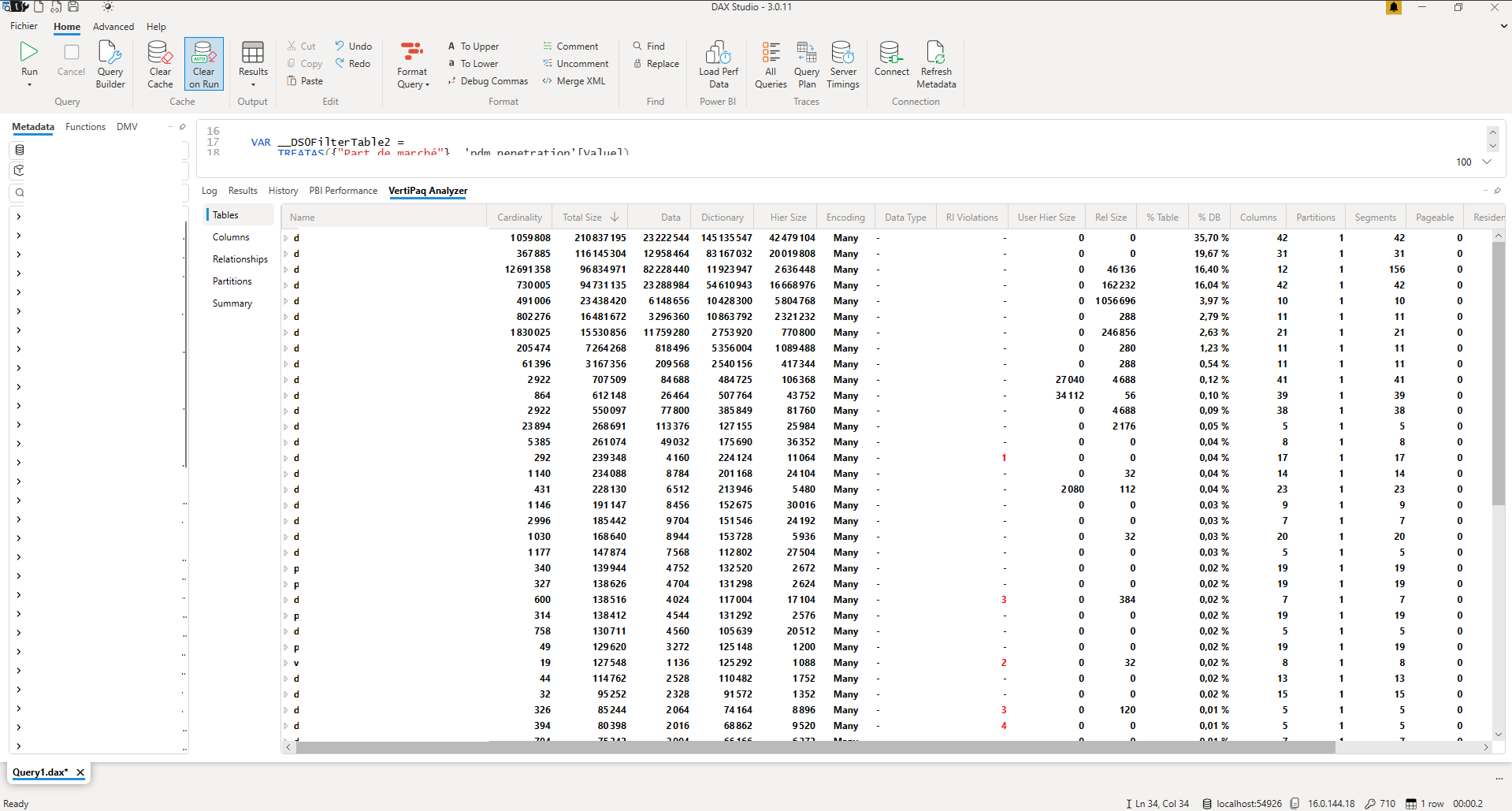
Ici on voit que les 4 plus grosses tables représentent 80% du poids du modèle, on choisira donc de ne se concentrer que sur ces tables.
Sur la première table, on voit que les 4 premières colonnes ont la même cardinalité, celle de la table. C’est-à-dire que chaque ligne possède une valeur différente pour ces 4 colonnes. En général une cardinalité égale à celle de la table signifie que c’est notre unique colonne d’identifiant. Avoir plusieurs colonnes avec cette cardinalité est souvent une information redondante et le modèle de données pourrait être repenser pour faire usage de dimensions pour n’avoir qu’une seule colonne identifiante.
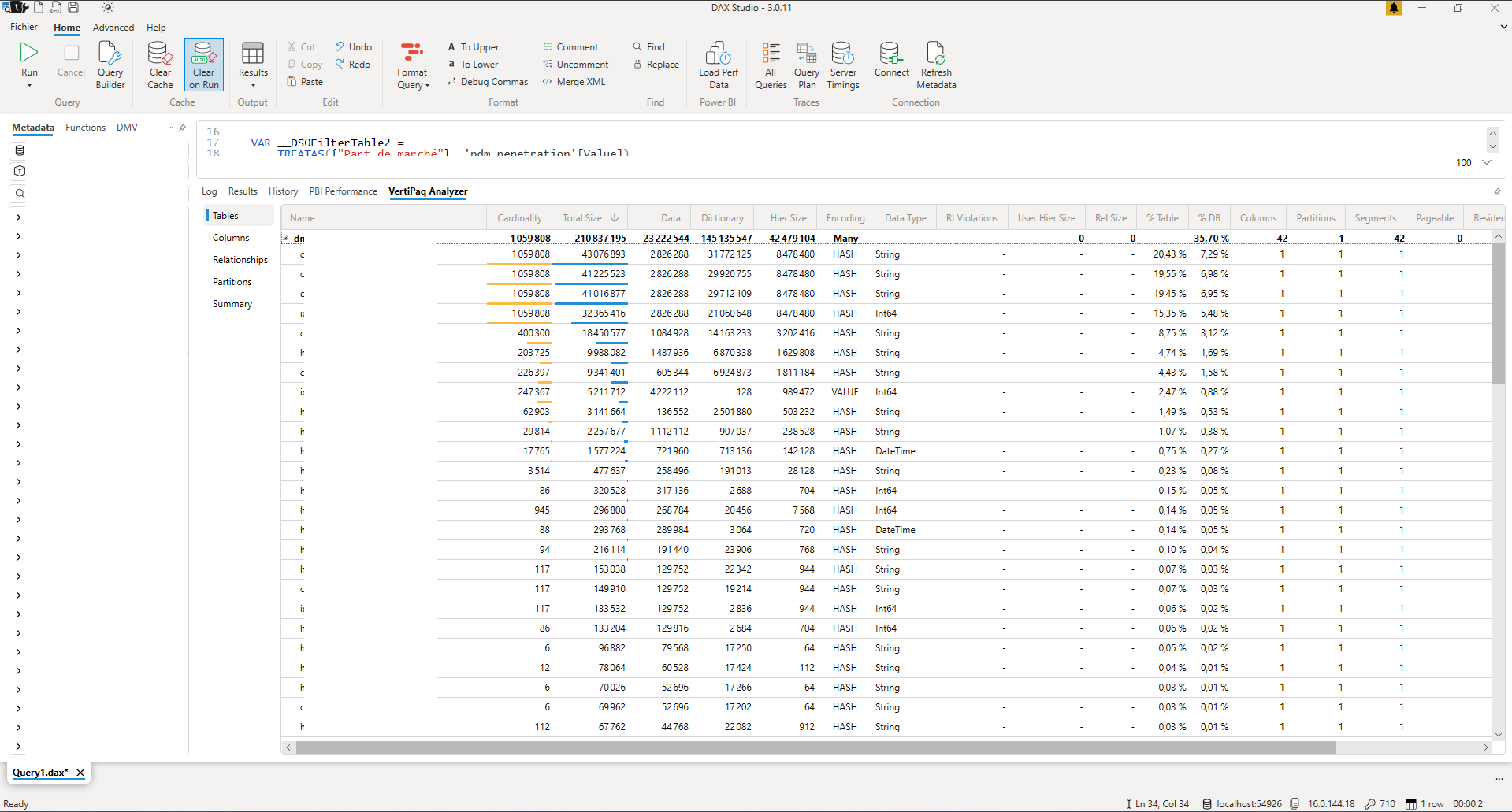
On remarque que ces colonnes représentent 75% du poids de la table, optimiser les autres colonnes n’a que peu d’intérêt.
Dans le cas où il n’est pas possible de se passer de ces colonnes en raison de besoin spécifiques, on peut envisager d’optimiser au niveau du type de la données, quelques exemples ce dessous
Il est toujours préférable (dans la mesure du possible) d’utiliser le type « Fixed decimal number » plutôt que juste le type « Decimal number ».
Dans le cas de »Text », Power Bi s’occupe de retirer les espaces en fin de chaines, mais pas ceux en début de chaines. Prendre le soin de retirer manuellement ces espaces peut faire gagner de l’espace. On peut aussi penser à travailler avec des « Enums » dans les cas où la cardinalité n’est pas forte. Les comparaisons entre chaines de caractères sont moins performantes que des comparaisons sur des « Enums ».
Pour les « DateTime », il est souvent plus avantageux d’avoir une colonne contenant la Date et une contenant le Time. Power Bi fonctionnant avec des dictionnaires de valeurs, travailler avec ces 2 colonnes permets d’avoir 2 dictionnaires très réduits plutôt qu’un seul très lourd et qui ne fera que grandir.
On peut aussi gagner en efficacité sur des « Int64 » à forte cardinalité (comme un identifiant), en le séparant de 2 colonnes. Par exemple id_div = id/1000 et id_mod = id%1000. Comme vu au point précédent, le dictionnaire de données coté serveur sera plus petit et donc plus efficace.
DAX Studio
Installation et présentation de l’outil
L’intérêt de DAX Studio est l’édition et la jouabilité de requêtes. En effet on utilisera cet outil principalement pour jouer des requêtes, les modifier et les rejouer, de façon itérative afin de suivre l’évolution du temps d’exécution des requêtes à travers l’onglet « History ».
L’installation et une explication détaillée de cet outil est disponible sur l’article précèdent. Ici nous nous concentrerons sur la façon d’optimiser une requête et de vérifier la non-régression à chaque modification.
Comment l’utiliser
De même qu’il est plus efficace d’optimiser les tables et colonnes les plus lourdes, on va chercher à optimiser les requêtes les plus longues. On utilise le Performance Analyzer (vu dans le premier paragraphe) pour sélectionner la mesure à retravailler. On peut directement l’importer de Performance Analyzer via le bouton « Load Perf Data ». On retrouve alors toutes les mesures qui ont été jouées lors de l’enregistrement.
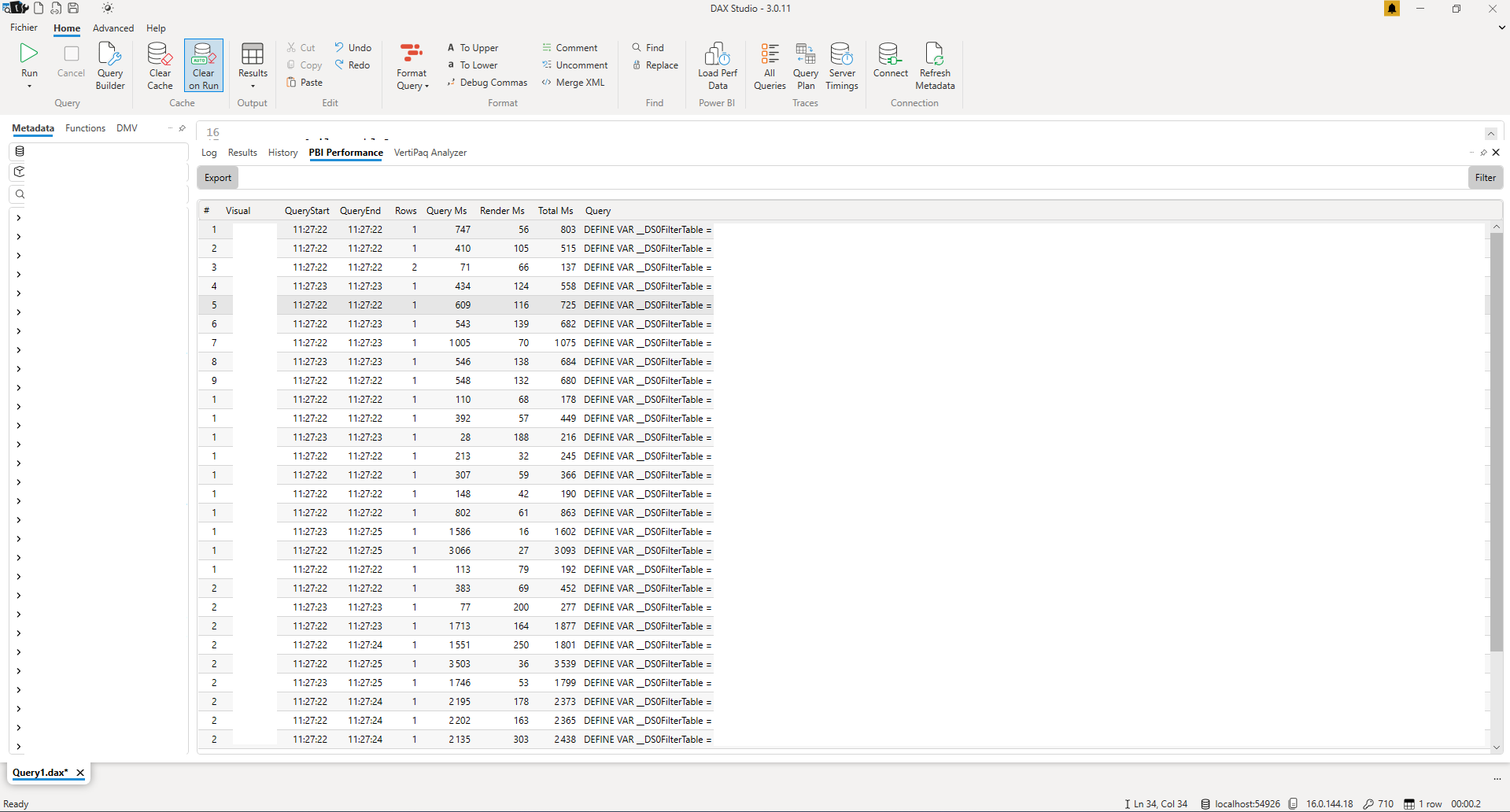
En double cliquant sur la mesure identifiée comme la plus lente, elle apparait dans l’IDE, disponible à l’édition.
Il est intéressant d’identifier les tables et colonnes utilisées par la mesure, et chercher à voir avec Vertipaq Analyzer si des optimisations sur ces tables et colonnes sont possibles.
La seconde chose à observer est l’utilisation de mesures. Si des mesures sont utilisées, on va forcer leur définition en haut de la requête. Pour cela il faut retrouver la mesure dans l’arborescence à gauche, et en faisant clic droit puis « Define measure », on fait apparaitre dans l’IDE sa définition.
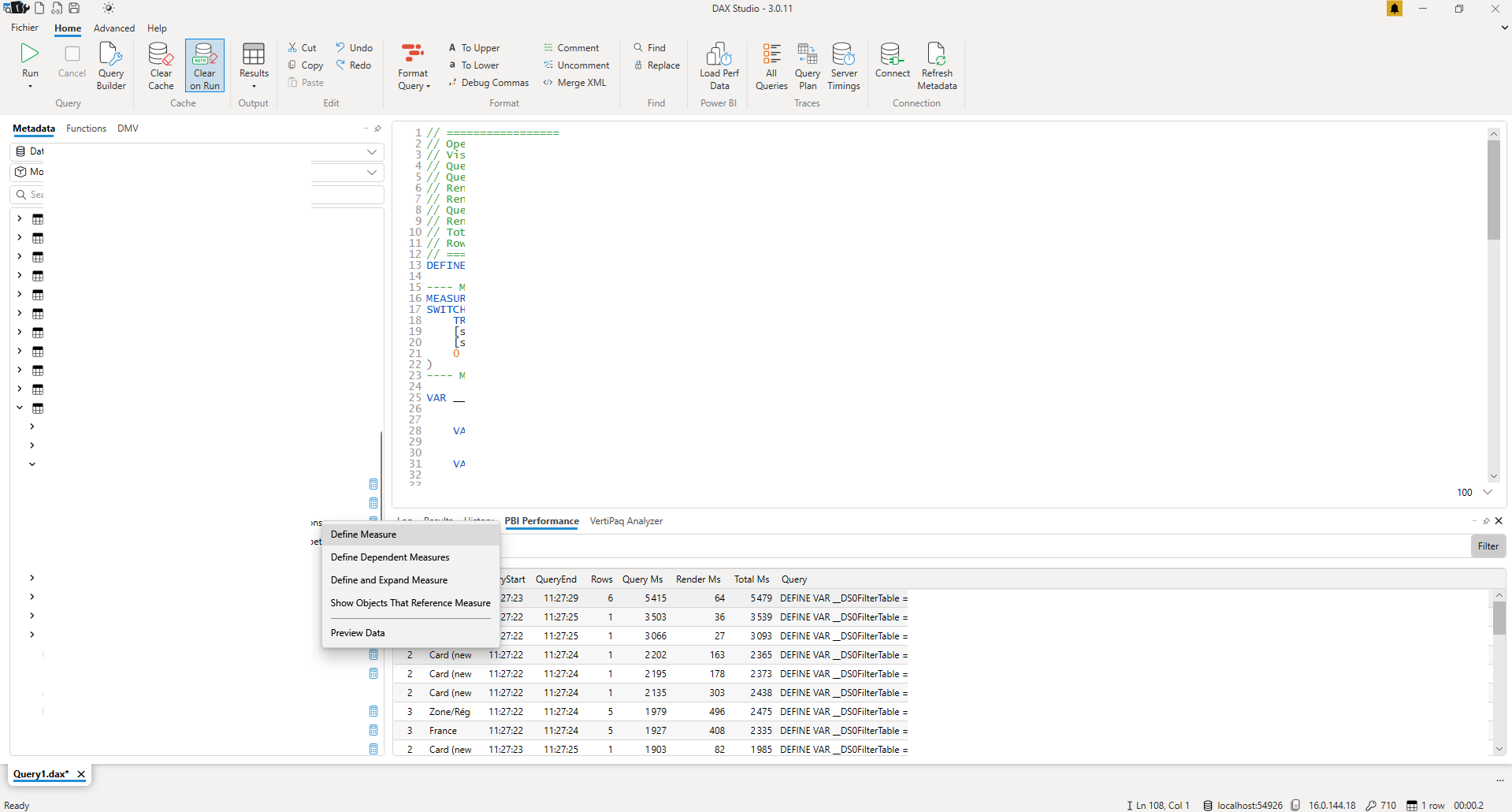
À partir de maintenant, lorsqu’on jouera cette requête, la définition de la mesure prise en compte sera celle de l’IDE. Cette configuration est idéale pour rapidement tester si des modifications sur la mesure accélère ou ralentisse l’exécution de la requête.
On rappelle que pour avoir une mesure fiable du temps d’exécution, il faut vider le cache à chaque exécution. De plus il faut jouer la même instruction plusieurs fois de suite pour éviter d’être trompé par l’allocation des ressources de l’ordinateur qui ne sera pas la même à tout instant. En faisant une moyenne de ces valeurs, on obtient une mesure assez fiable pour être comparée au temps d’exécution de la même mesure modifiée et ainsi estimer si les modifications ont été bénéfiques ou non.
On peut avoir davantage d’information sur l’exécution de la requête en activant « Server Timings ». En activant cette option, on capturera les temps d’exécution sur les 2 systèmes de traitements : le Storage Engine (SE) et le Formula Engine (FE).
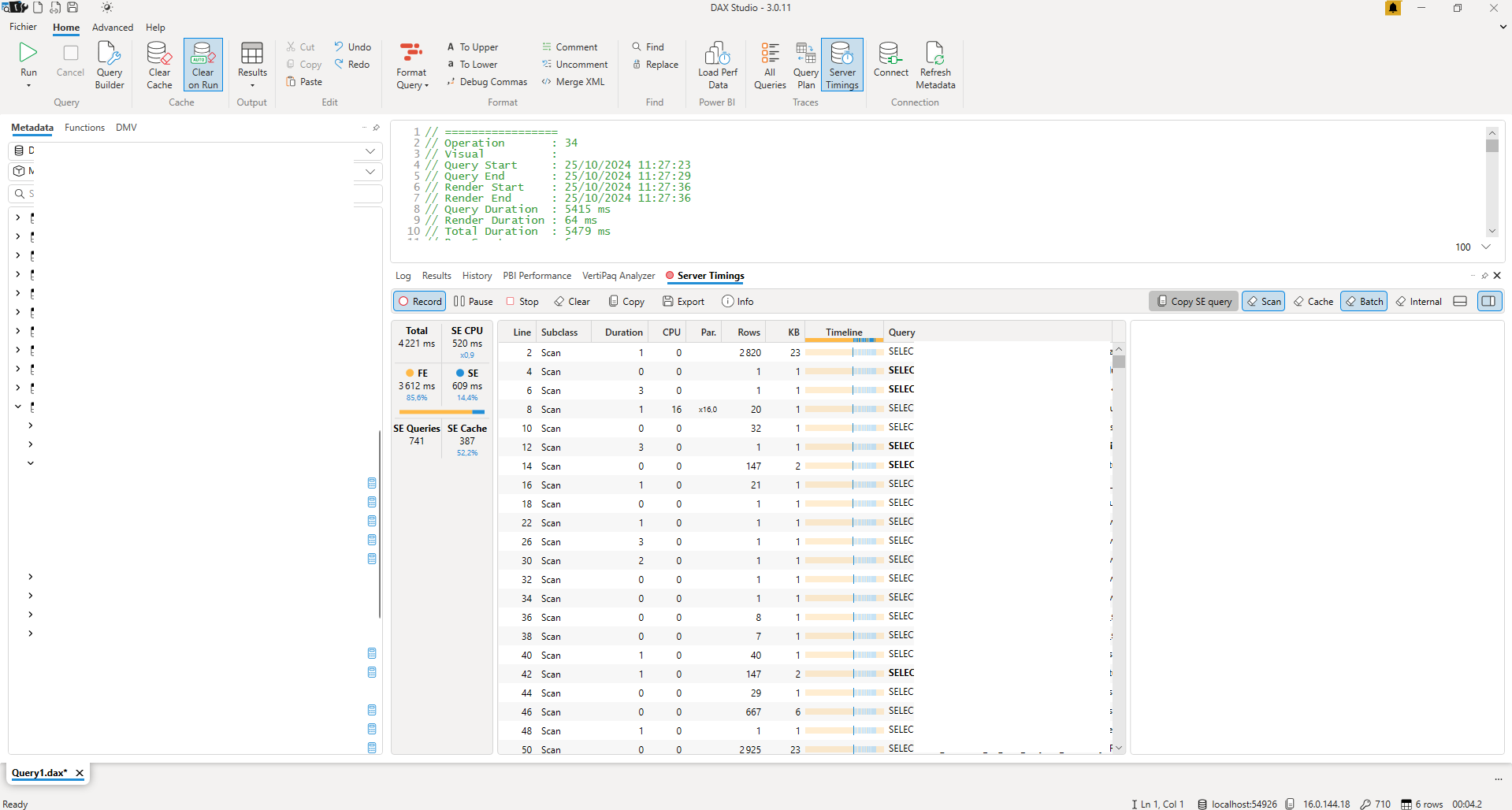
Le Formula Engine a pour rôle de gérer le query plan et d’exécuter les opérations sur les données, tandis que le Storage Engine sert à ramener les données nécessaires pour le FE. L’objectif est que le ratio entre le temps d’exécution sur le FE contre celui sur le SE penche le plus fortement possible vers le SE.
En effet le SE combine plusieurs avantages pour gagner en performances, comme une gestion du multi-thread, l’utilisation de données compressé ou la gestion de cache, contrairement au FE optimisé pour les requêtes complexes, au détriment de la rapidité.
Un dernier indicateur de meilleures performances d’une requête est le nombre de requête sur le FE et le SE.
Tous ces indicateurs permettent ainsi de benchmarker et suivre l’évolution des modifications d’une mesure ou d’une requête avant de la publier, évitant ainsi d’éventuelles régressions lors de la recette.
Conclusion
Dans l’article précédent nous avions vu comment identifier la source d’un problème de performance et dans cet article nous avons vu comment utiliser des outils pour améliorer la qualité et la performance du rapport (Best Practice Analyzer) mais aussi comment utiliser Vertipaq Analyzer pour identifier des optimisations sur le modèle de données et DAX Studio pour suivre l’évolution des temps de traitement au fil des corrections.
Il sera abordé dans un prochain article la question du choix de la capacité Premium (ou non) et la gestion des options des workspaces afin d’optimiser les performances de rapports et d’applications à un niveau plus haut.
