Ingestion des données avec Azure Data Factory



Introduction
Ingestion des données
Le but est de centraliser les données de plusieurs sources en un même points afin de pouvoir les analyser comme un tout et leur donner plus de valeur. Par exemple, nous pourrions collecter les coûts d’une entreprise via des sources et des formats différents (fichiers JSON, Excel, CSV, base de données, etc.), et ainsi après traitement avoir une vue d’ensemble sur les coûts totaux.
Cette ingestion de données se fait généralement en temps réel ou en batch : soit la donnée est importée lorsque l’émetteur l’envoie, soit la donnée est regroupée en batch et les batchs sont traités à intervalles réguliers.
Afin d’automatiser l’ensemble du processus, de nombreux outils existent et les fournisseurs de services cloud comme Amazon avec AWS ou Microsoft avec Azure possèdent leurs propres services d’orchestration et de traitement des données.
Traitement des données
Il existe différents processus pour organiser les traitements, le plus populaire est l’ETL.
Un ETL est un processus signifiant Extract, Transform and Load. Cela représente le cycle par lequel la donnée passera : extraite de la source de données, transformée pour répondre aux besoins métiers et enfin chargée dans un espace de stockage approprié pour être utilisée par le métier.
Nous pouvons aussi organiser les étapes de traitement en plusieurs niveaux de qualité, ou de valeur ajoutée : bronze, silver et gold. Les données « bronze » sont les données brutes, telles que l’on a pu les récupérer à la source. Les données « silver » sont des données nettoyées, éventuellement utilisables pour différents besoins métiers. Enfin, les données « gold » sont les données traitées pour un besoin métier spécifique. Ainsi, nous pouvons obtenir plusieurs gold à partir d’un même silver.
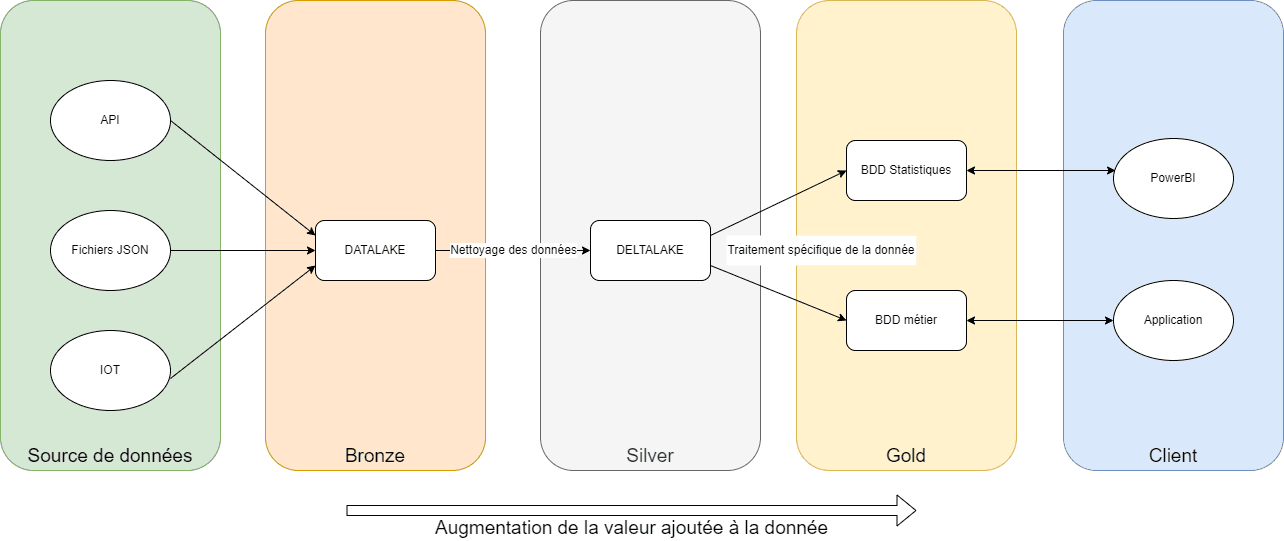
Figure 1 : Exemple d'ingestion de données
Avec l’augmentation des puissances de calculs des serveurs, un dérivé de l’ETL existe : l’ELT, là où est chargée la donnée non traitée (gain de temps). En traitant la donnée une fois stockée, nous gagnons en flexibilité côté métier tant que les performances supportent la charge.
Cas pratique : Récupérer les données brutes dans le bronze
Cadre du cas pratique
Je vous propose une série d’articles sur le sujet de l’ingestion et du traitement des données sur les outils Azure, et plus particulièrement sur Azure Data Factory (ADF), Azure Databricks, Azure Data Lake Storage et Azure Synapse, qui sont des outils Microsoft courant pour ce cas d’usage.
Nos données seront les données fournies par Vélib Métropole via une API :
https://www.velib-metropole.fr/donnees-open-data-gbfs-du-service-velib-metropole
Cette API ne nécessite pas d’authentification. Nous récupérons d’une part les informations des stations (coordonnées, capacité, disponibilité de la station, etc.), et d’autres part le statut des stations (nombre de vélos disponibles, nombre de vélos électriques, etc.).
Le but de ce tutoriel est d’appeler ces API et de stocker les résultats dans le bronze d’un datalake. Nous ajouterons des triggers pour automatiser les appels et ainsi avoir un historique, minute par minute, du statut des stations. Ainsi, nous serons en mesure d’avoir assez de données pour faire des analyses et donner de la valeur à ces données.
Prérequis
Afin de pouvoir réaliser ce tutoriel, il vous faudra avoir créé préalablement un ADF et un ADLS Gen2 dans lequel vous aurez un container où vous déposerez vos données.
Linked services
La première étape est de créer les linked services dont nous aurons besoin. Un linked service est une connexion avec les services avec lesquelles ADF interagira. Dans notre cas, nous aurons besoin d’interroger une API et de déposer des fichiers dans un datalake. Nous allons donc créer deux services linked : un des type REST et un de type ADLS Gen2.
Dans l’onglet Service Linked d’ADF, il faudra créer un nouveau service lié et sélectionner un service de type REST.
Figure 2 : Onglet des linked services

Figure 3 : Choix du type de linked service
Puis, nous complètons les informations avec l’API, que nous interrogerons, et le système d’authentification (dans notre cas il n’y a pas besoin de s’authentifier).
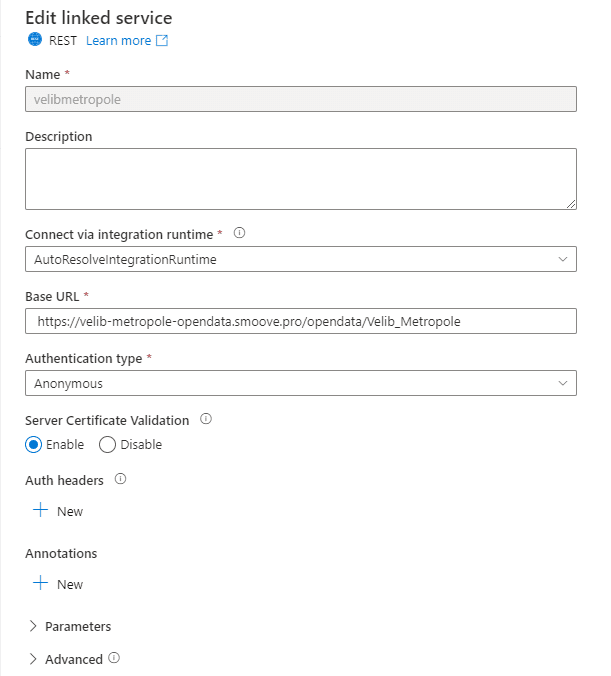
Figure 4 : Création d'un service lié REST
De la même façon, nous créons un service linked de type ADLS Gen2 et sélectionnons les paramètres propres à notre souscription. Sur chacun des services, il est possible de tester si notre configuration est fonctionnelle en cliquant sur « Test connection ».
Figure 5 : Création d'un service lié de type ADLS Gen2
Dataset
Une fois les linked services ajoutés, nous créons les datasets. Il s’agit des emplacements de données précis à partir des linked services. Par exemple, pour un linked service REST où a été renseigné la base URL, nous préciserons dans un dataset de ce linked service l’url relative que nous souhaitons utiliser. Dans le cas d’un linked service de type ADLS, nous précisons dans le dataset associé le container à utiliser et le chemin dans l’arborescence.
Ainsi, il peut y avoir plusieurs datasets pour un même linked service : un pour chaque usage qu’on pourrait avoir de la connexion avec le service lié. Si nous avons un service linked de type Azure SQL Database où aura été précisé la database, nous aurons au moins un dataset pour chaque table utilisée.
Dans notre cas nous allons créer 3 datasets :
- Un pour chaque API interrogé
- Un pour le bronze du datalake.
Dans l’onglet d’édition, puis Dataset, nous allons créer un nouveau dataset de type REST.
Figure 6 : Onglet de création de dataset
Les services linked proposés sont uniquement ceux dont le type peut être associé avec le type de dataset sélectionné. Dans notre cas nous n’avons que le service linked REST. Une fois le dataset créé, il est nécessaire de compléter le dataset avec l’url relative.
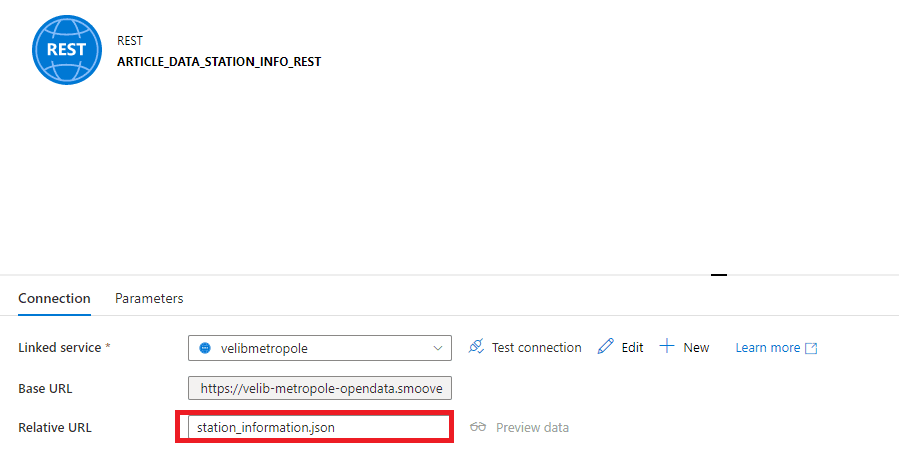
Figure 7 : On renseigne l'URL relative dans le dataset
Nous créons le second dataset de la même façon, seule l’url relative sera différente. Dans un cas nous utiliserons « station_information.json », dans l’autre « station_status.json ».
Il faut enfin créer un dataset de type ADLS Gen2 (comme pour le linked service), mais aussi choisir le type de données que nous manipulerons. Si le besoin de manipuler les données à l’intérieur des fichiers est nul (pour faire simplement des copies de fichiers par exemple) le choix le plus souvent pertinent sera « binary ». En effet ADF ne cherchera pas à interpréter les fichiers et sera plus efficace lors des manipulations.
Si nous choisissons le type Excel, nous pourrons choisir la sheet que nous souhaitons utiliser. Ceci permet des manipulations de données plus fines. De même avec le type CSV, nous pourrons directement mapper les colonnes à la manière d’une table SQL.
Une limitation du choix du type d’un dataset est qu’ADF ne peut pas effectuer une activité de copy d’un type de données à un autre type de données incompatibles, comme du binaire en Excel par exemple.
Dans notre cas, nous devront choisir le type « Json » : c’est le type de réponse que nous obtiendrons d’une API REST. Nous choisirons ensuite le service linked du datalake et validerons la création. Il faut ensuite compléter le chemin où les JSON seront copiés.
Nous souhaitons avoir un dossier contenant les informations des stations et un autre avec les statuts des stations. Une solution serait donc de créer 2 datasets et de spécifier de façon statique les chemins. Dans une optique de classement des données efficace, nous rangerons les données dans des sous-dossiers suivant cette structure : année/mois/jour et on nommera les fichiers récupérés sous ce format yyyyMMddhhmmss_station_status.json (ou station_information.json).
Ce type de structure permet de ne pas avoir des centaines de milliers de fichiers à la racine, nommés avec un id généré automatiquement par ADF lors de sa création. Ainsi, il sera facile d’identifier les fichiers à chaque instant, dans l’optique de ne traiter que les fichiers d’un certain intervalle de temps par exemple.
Pour cela, il est possible de rendre le chemin dynamique. Nous commencerons par ajouter des paramètres, un par élément dynamique : ici l’année, le mois, le jour, l’heure, la minute, la seconde et le domaine (qui vaudra soit station_status, soit station_information).
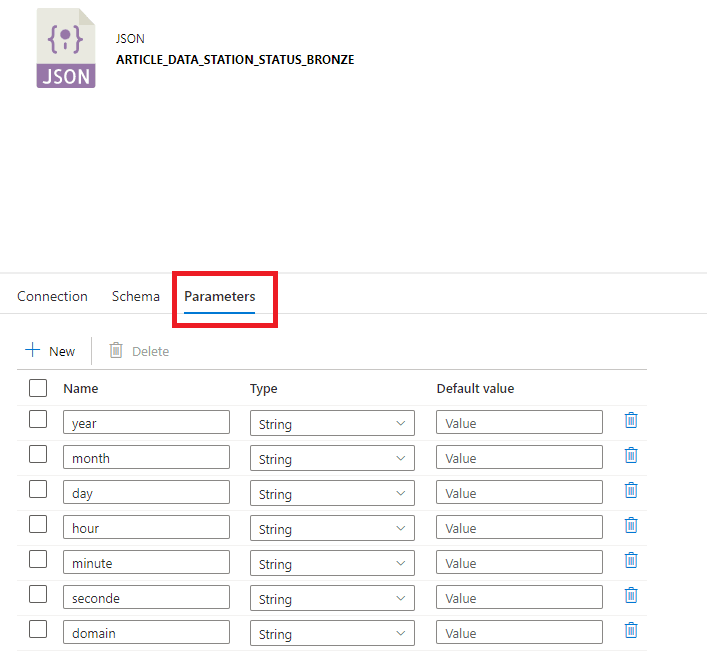
Figure 8 : Paramètres d'un dataset de type JSON
Une fois les paramètres ajoutés, il est désormais possible de compléter le chemin en renseignant le container que nous souhaitons utiliser (bronze par exemple) en cliquant sur le lien « Add dynamic content ».
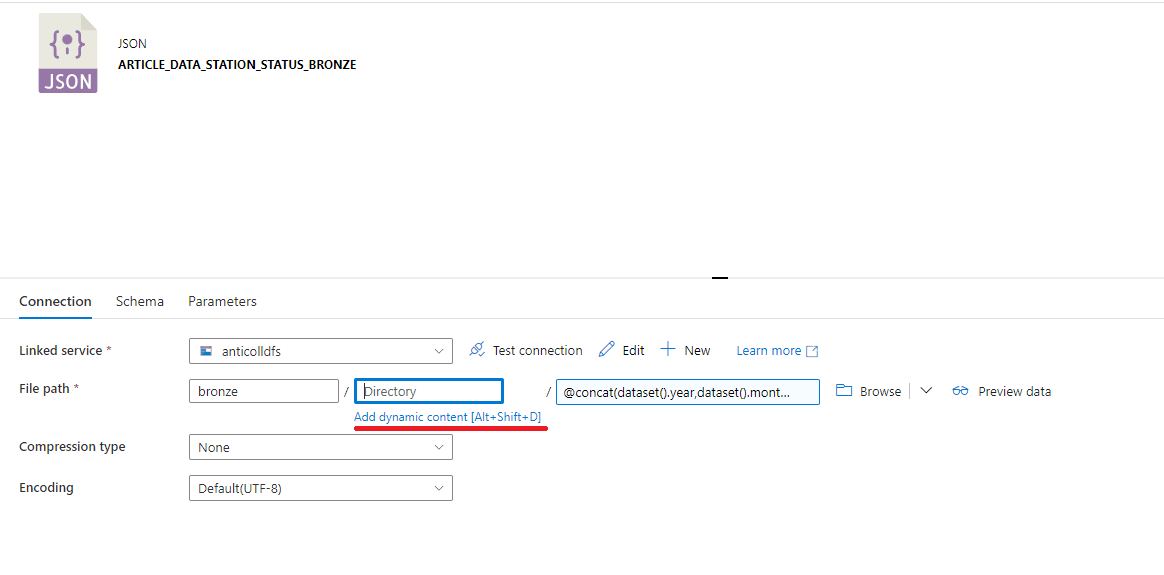
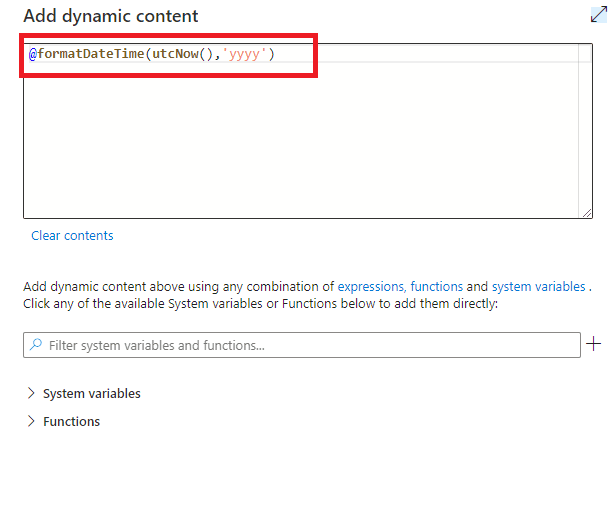
Figure 9 : Ajout d'une arborescence dynamique
Dans les champs de texte dynamique, nous avons à disposition des fonctions d’ADF et les variables à disposition. Ici les paramètres que nous avons créés (si créés, nous pourrions aussi avoir des variables d’environnement, partagées à travers tous les éléments d’ADF).
Nous allons ensuite utiliser la fonction « concat » pour concaténer tous nos paramètres bout à bout, espacés par des « / ». Les champs dynamiques doivent commencer par le caractère @. Nous pouvons cliquer sur les propositions sous le champ texte pour remplir automatiquement la proposition dans le champ texte. Dans mon cas, j’ai ajouté au début un premier sous-répertoire pour faire une distinction entre le bronze de ce projet et celui d’autres projets :
> @concat('article_data/',dataset().domain,'/',dataset().year,'/',dataset().month,'/',dataset().day)
De la même façon, nous paramétrons le nom du fichier :
> @concat(dataset().year,dataset().month,dataset().day,dataset().hour,dataset().minute,dataset().seconde,'_',dataset().domain,'.json')
Pipeline
La majeure partie des activités des pipelines nécessitent une source de données entrante (dataset source) et une source de données sortante (dataset sink), sans quoi nous ne pouvons pas les créer. Avec les datasets REST qui seront nos sources et notre dataset Datalake qui sera notre sink, il est possible de créer nos pipelines.
Pour une bonne gestion des pipelines, notamment au niveau du monitoring et de l’alerting, il est conseillé de créer un pipeline par fonctionnalité. Ici, nous ferons :
- Un pipeline pour récupérer les informations des stations
- Un pour récupérer les statuts des stations
- Un pipeline qui appellera les 2 pipelines
Nous créons les 2 premiers sur la même base, dans l’onglet d’édition, puis pipeline, nous créons un nouveau pipeline et ajoutons une activité de « copy ».
Figure 10 : Création d'une activité de copy
Dans l’onglet source nous choisissons un de nos datasets REST et la méthode GET.
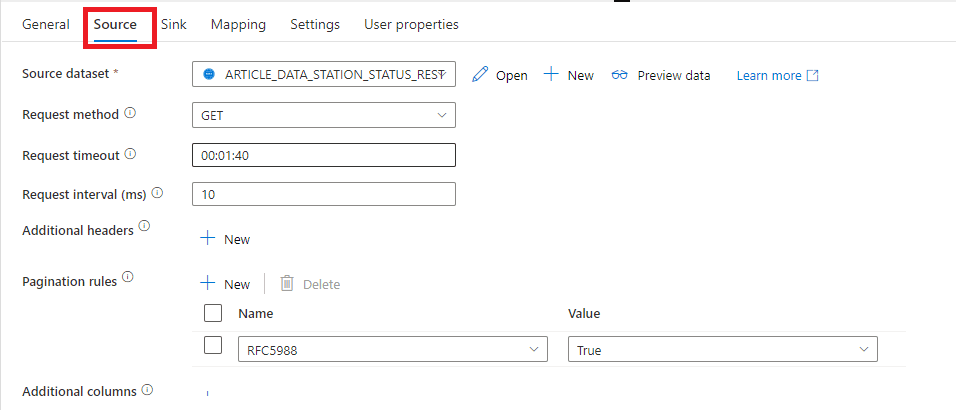
Figure 11 : Gestion de la source de l'activité de copy
Dans l’onglet Sink, une fois notre dataset de datalake choisit, nous sommes invités à entrer les paramètres définit dans le dataset. Nous choisissons pour le paramètre « domain » le domaine correspondant au dataset choisit, et pour les paramètres dynamiques nous cliquons sur « Add dynamic content » pour inscrire de façon dynamique la date à l’instant où le pipeline s’exécutera. Pour cela il est nécessaire d'utiliser 2 fonctions de manipulation de date de ADF : formatDateTime et utcnow.
FormatDateTime prend une date et un format en paramètre. Utcnow renvoie la date à l’instant où l’activité est exécutée. Il suffit de spécifier uniquement l’année dans le format pour avoir l’année en cours.
Figure 12 : Gestion dynamique de l'année
Nous ferons de même pour tous les autres paramètres.
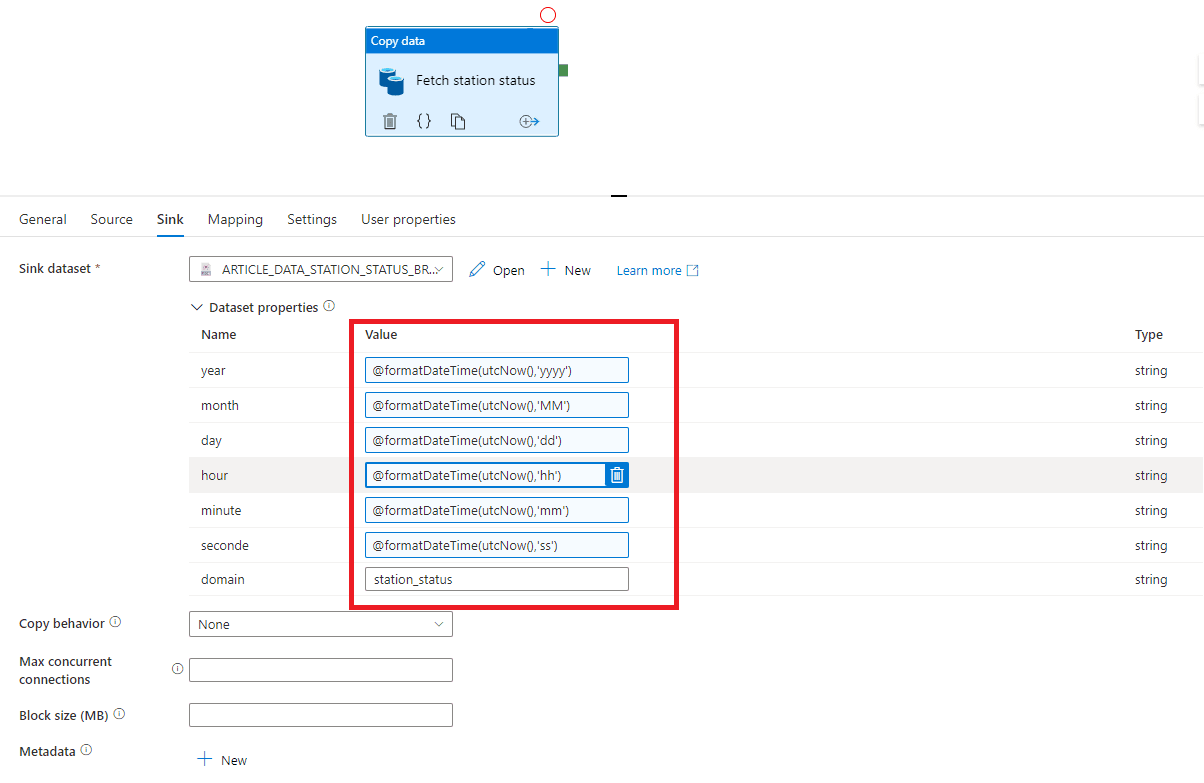
Figure 13 : Paramètres dynamiques du sink
Nous créons le second pipeline de la même façon en changeant le dataset de la source, et la valeur du paramètre domain dans le sink. À l’exécution de ces pipelines, l’activité de copy ira interroger l’API avec la base url (du linked service), la relative url (du dataset) et ira par la suite copier la réponse dans le datalake au chemin indiqué (dans le dataset) avec les paramètres du pipeline.
Pour le pipeline global, nous créerons un pipeline avec deux activités : 2 activités d’exécution d’autres pipelines, où l'on sélectionnera dans les paramètres nos deux premiers pipelines.
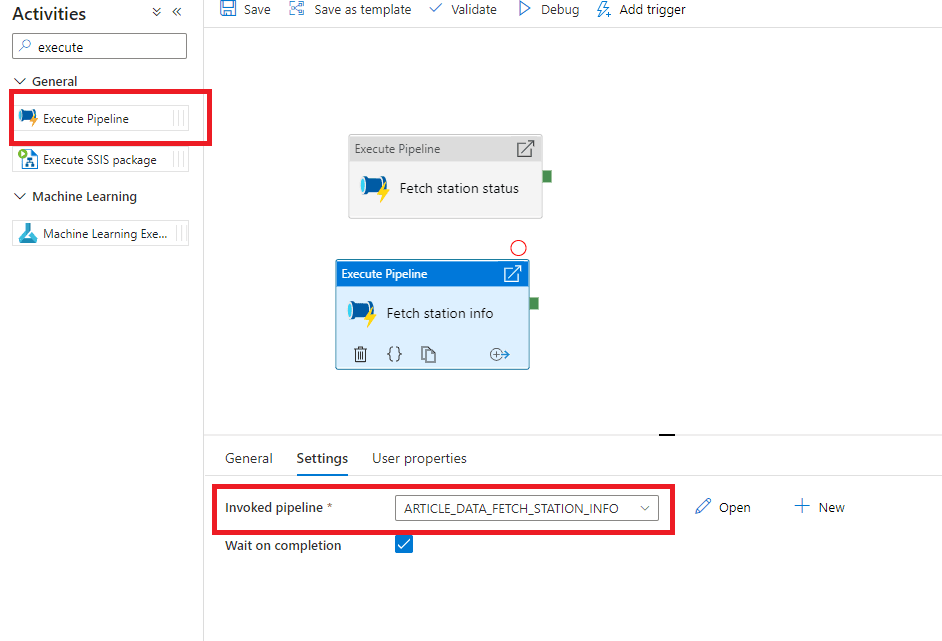
Figure 14 : Pipeline global
À l‘exécution de ce pipeline, les 2 activités seront exécutées en même temps, parallélisant les 2 récupérations de json.
Trigger
Nous pouvons déclencher les pipelines de plusieurs façons.
En cliquant sur Debug, nous pouvons exécuter un pipeline encore non sauvegardé et consulter les résultats dans l’onglet « output ». Une exécution en mode Debug utilisera moins de ressources qu’une exécution standard (certaines actions normalement en parallèle seront exécuter de façon séquentielle par exemple).
Une fois un pipeline sauvegardé nous pourrons l’exécuter dans les conditions normales via le bouton « Add trigger ». En choisissant « Trigger now » nous exécutons le pipeline instantanément.
Pour avoir un historique complet, nous souhaitons récupérer les données toutes les minutes (la documentation de l’api nous indique que les données sont rafraichies chaque minute). Il faudra alors créer un trigger qui exécutera automatiquement notre pipeline à l’intervalle de notre choix.
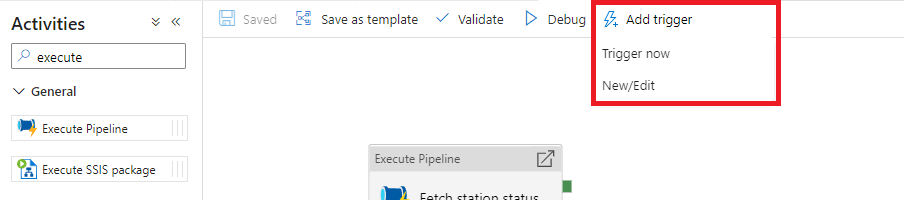
Figure 15 : Ajout d'un trigger de pipeline
On choisit une récurrence de 1 minute.
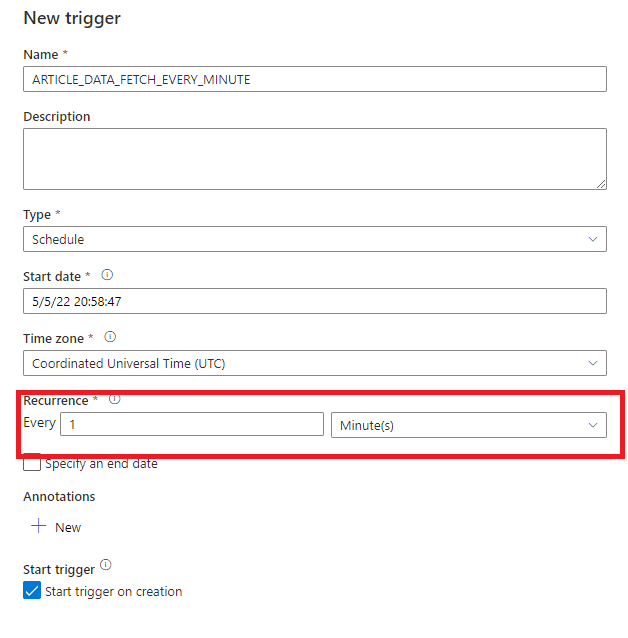
Figure 16: Création d'un trigger se déclenchant toutes les minutes
Conclusion
Nous obtenons donc avec une récupération automatique des données de l’API et un stockage ordonné des fichiers json récupérés. L’article suivant aura pour objet de nettoyer les données via des notebooks Databricks et passer les données en silver.
La façon dont les pipelines créés au cours de ce tutoriel permet une rejouabilité des pipelines (idempotence sur l’intervalle de la minute) et de pouvoir retrouver facilement les données grâce à l’arborescence dans le datalake.
