Qu’est-ce que l’architecture hexagonale et un exemple d’implémentation en .NET



Introduction
L’architecture hexagonale, aussi connue sous le nom d’architecture « ports et adaptateurs », a été inventée en 2005 par Alistair Cockburn. Il s’agit d’une architecture logicielle qui permet de créer des applications flexibles et maintenables en se basant sur la séparation des tâches et une division du système en plusieurs couches distinctes.
Cette architecture repose sur une conception d’applications centrée autour d’un noyau qui contient toute la logique métier, aussi appelé « Domaine », avec en périphérie tout ce qui concerne l’infrastructure.
Cette approche permet au noyau d’être indépendant de tout framework, bibliothèque ou base de données, rendant plus simple les tests, modifications et améliorations dans le temps.
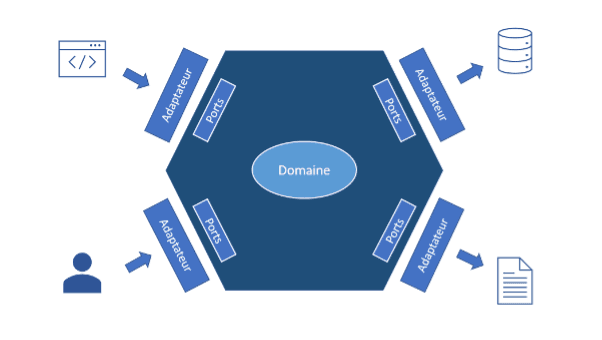
Les principes de l’architecture hexagonale
L’architecture hexagonale se base sur 3 grands principes. Ils permettent notamment d’orienter la conception et l’implémentation de l’architecture :
- Séparation des tâches (Separation of concerns) : On divise le système en composants distincts, chacun responsable d'une tâche spécifique. La logique métier de base (domaine) est isolée des systèmes externes et des aspects liés à l'infrastructure. Cette séparation permet d'améliorer la maintenabilité, la testabilité et la flexibilité, car les changements apportés à une composante n'ont pas d'incidence directe sur les autres.
- Inversion de dépendance (Dependency Inversion) : Il favorise l'inversion des dépendances entre le noyau et les couches environnantes. Au lieu de dépendre d'implémentations spécifiques de systèmes externes, le noyau définit des interfaces ou des classes abstraites (« ports ») que les systèmes externes (« adaptateurs ») doivent implémenter. Cette inversion du contrôle permet au noyau d'être découplé de technologies spécifiques, ce qui le rend plus indépendant, réutilisable et testable.
- Ports et adaptateurs (Ports and Adapters) : Les ports représentent les interfaces par lesquelles le noyau communique avec le monde extérieur. Les adaptateurs, quant à eux, implémentent ces ports, agissant comme des intermédiaires entre le noyau et les systèmes externes. Les adaptateurs entrants gèrent l'entrée et la conversion des données dans un format que le noyau comprend, tandis que les adaptateurs sortants gèrent les interactions avec les systèmes externes tels que les bases de données ou les API. L'utilisation de ports et d'adaptateurs permet au noyau de rester isolé des problèmes d'infrastructure, ce qui facilite la modularité et la possibilité de changer ou de remplacer facilement les composants externes.
Ces trois principes s'associent pour créer une architecture flexible et facile à maintenir qui se concentre sur la logique métier de base tout en la maintenant découplée des systèmes externes. L'architecture hexagonale favorise la conception modulaire, la testabilité et l'adaptabilité, ce qui permet au système d'évoluer et de s'adapter plus efficacement.
Quels sont ses avantages et inconvénients ?
L'architecture hexagonale présente plusieurs avantages, mais aussi quelques inconvénients. Voici une liste des principaux avantages et inconvénients de cette architecture.
Les avantages
- Séparation des tâches : L'architecture hexagonale permet une séparation claire entre la logique métier (domaine) et les détails d'implémentation, ce qui facilite la compréhension et la maintenance du code.
- Modularité : Grâce à la séparation des ports et des adaptateurs, l'architecture hexagonale favorise la modularité, ce qui permet de développer des systèmes flexibles et extensibles.
- Testabilité : L'isolation du noyau facilite la réalisation de tests unitaires, car la logique métier peut être testée indépendamment des composants externes.
- Indépendance technologique : Le noyau ne dépend pas des détails d'implémentation, ce qui permet de changer ou de mettre à jour les technologies utilisées sans affecter la logique métier.
- Adaptabilité : L'architecture hexagonale facilite l'adaptation aux changements des besoins métier, car le noyau reste stable même si les composants externes changent.
Les inconvénients :
- Complexité initiale : La mise en place de l'architecture hexagonale peut être plus complexe que des approches plus traditionnelles, nécessitant une bonne compréhension des concepts et une planification initiale minutieuse.
- Surcharge de code : L'utilisation de ports et d'adaptateurs peut entraîner une quantité supplémentaire de code par rapport à des architectures plus simples.
- Courbe d'apprentissage : Les développeurs qui ne sont pas familiers avec l'architecture hexagonale peuvent avoir besoin de temps pour s'habituer aux concepts et aux patterns utilisés.
Il est important de noter que les avantages et les inconvénients peuvent varier en fonction du contexte d'application et des besoins spécifiques du projet. L'architecture hexagonale peut être bénéfique pour les projets de grande envergure ou les applications qui nécessitent une évolutivité, une testabilité et une maintenabilité accrues. Cependant, pour de petits projets ou des cas d'utilisation simples, l'architecture hexagonale peut introduire une complexité inutile.
Un exemple d’implémentation en .NET 6 (à notre sauce)
Maintenant que notre petit tour de la théorie de l’architecture hexagonale est fait, il est temps de vous montrer une implémentation sur un projet de web API en .NET 6.
Il faut tout d’abord mettre en place un service qui va aller alimenter une base de données et un conteneur de stockage blob automatiquement suite au dépôt d’un fichier dans un Onedrive. Il sera copié dans un conteneur de stockage blob sur Azure (on ne traitera pas de la mise en place de ce système de copie ici). En parallèle, on veut une application web qui va permettre de consulter les données que l’on aura stocké et y apporter des modifications.
Grosso modo, on arrive avec une implémentation qui ressemblerait à ça :
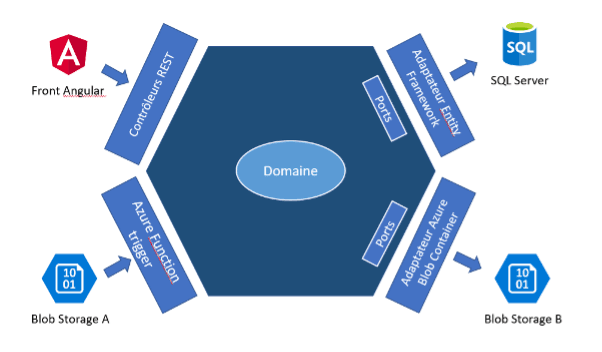
On retrouve donc :
- Une API REST avec ses contrôleurs,
- Une ou plusieurs Azure Functions qui vont se charger de la lecture automatique des fichiers, déclenchées par la création du fichier blob dans le conteneur blob,
- L’adaptateur utilisant Entity Framework pour pouvoir communiquer avec la base de données SQL Server
- L’adaptateur utilisant le SDK Azure Storage Blobs pour aller stocker les fichiers dans un autre stockage blob ou un datalake sur Azure
Pourquoi n’a-t-on pas de port côté gauche ? La réponse est simple, dans notre cas nous n’en avons pas vraiment besoin. Voilà pourquoi :
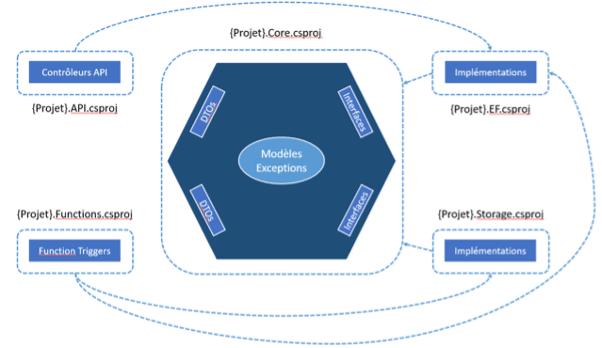
Dans ce schéma, on trouve la répartition en projet de notre solution, avec les flèches indiquant les dépendances projets.
À gauche, on peut voir les deux projets entrants (Driving) :
- Le projet API qui va contenir les contrôleurs nécessaires pour alimenter les IHM et manipuler les données via des interfaces utilisateur
- Le projet Functions qui va contenir les Azure functions qui vont traiter les fichiers et stocker leur contenu soit en base, soit dans un stockage blob
On va seulement leur injecter les interfaces dont ils ont besoin
Ceux-ci dépendent des projets à droite (Driven) :
- Le projet EF s’occupe de la connexion à la base de données SQL Server et à l’implémentation des interfaces de repository déclarée dans le noyau métier pour la lecture des données et l’écriture (le stockage)
- Le projet Storage va juste implémenter l’interface définie pour le stockage dans le blob
Qui à leur tour dépendent du projet au centre (Core) :
- Ici on trouvera uniquement des classes et interfaces
- Il ne doit y avoir aucune dépendance technique
Pour résumer, avec quelques détails en plus :
- Pour l’Azure function
- EF et Storage implémentent tous les deux cette interface avec leur propre techno
- On injecte ces implémentations dans le Startup du projet
- Lors de l’exécution de la fonction, elle itère sur les deux implémentations pour stocker les données là où elles doivent l’être
- Pour l’API REST
- Core définit les interfaces des repositories
- EF contient le DbContext avec les DbSet des modèles définis dans le Core et les implémentations des repositories
Conclusion
Voilà, vous avez maintenant les bases des connaissances à savoir pour vous lancer dans l’architecture hexagonale. Bien évidemment ce que l’on a fait ici n’est pas forcément valable pour tous les scénarios, mais grâce à cet article vous devriez avoir compris qu’appliquer l’architecture hexagonale en .NET se résume en quelques points dans une checklist.
