Apache Airflow pour automatiser efficacement vos pipelines Data.



C’est quoi Airflow ?
Airflow est l’un des outils les plus utilisés de nos jours dans l’orchestration et la planification des tâches et dans l’automatisation des flux de données. Il a été créé par Airbnb, rendu Open Source en 2014, puis repris sous licence Apache. Il est très répendu dans le domaine de la Data et chez les Data Engineers. En plus de son interface user-friendly, Airflow est écrit en Python ce qui facilite l'intégration de nombreuses bibliothèques développées par toute une communauté très active.
Problème
Dans cet article nous allons, à l’aide d’Aiflow, orchestrer une activité de type ETL (c’est-à-dire d’extraction, de transformation, et de chargement de données).
Airflow n’est pas un ETL, mais un orchestrateur permettant d’ordonnancer et d’automatiser des pipelines. Le but de l’activité est d’afficher, sur une carte géographique, les prix du carburant quasi temps réel (toutes les dix minutes) en passant par la récupération des données depuis un site internet qui seront manipulées et transformées dans AirFlow. Nous allons voir plus en détail, un peu plus loin dans l’article, ce que font les trois parties qui composent l’activité.
Commençons d’abord par lister les composants Airflow utilisés dans cet exercice.
À noter que nous allons nous intéresser uniquement aux prix du diesel, de l’essence SP95 et SP98. Le fichier contient également les prix du GPL, E10, et E85.
Composants d’Airflow
DAG
DAG pour Directed Acyclic Graphic est un code python qui contient un ensemble de tâches (tasks) et définit leurs dépendances et la façon dont elles vont s’exécuter. Comme le Workflow est un graphe orienté (un seul sens d'exécution), on ne risque pas d’avoir une boucle sans fin et il n'évolue que dans un seul sens. Un pipeline Airflow n’est donc rien d’autre qu’un DAG.
Task
Les tasks sont les éléments qui constituent un DAG et chacune d’entre elles, comme son nom l’indique, est responsable d’exécuter une ou plusieurs opérations.
Scheduler
Se charge d’administrer les Workflows, de gérer et de planifier leur exécution en les passant aux Executors/Workers.
Executor
Ce sont les composants qui exécutent les tâches. L’avantage qu’ils offrent est que l’on peut travailler avec des tâches qui ne sont pas de même nature. C’est-à-dire que nous pouvons être amenés à écrire des scripts Python, à lancer des conteneurs Docker, à faire des requêtes http …etc. Dans notre exemple, nous allons utiliser : BashOperator, PythonOperator, et EmailOperator.
Xcom
Xcom veut dire cross communication. C’est un moyen de communiquer entre des tâches du fait qu’elles sont isolées entre elles.
Solution
Nous partons du principe qu’Airflow est déjà installé et paramétré sur votre machine. La configuration d’Airflow n’est pas abordé dans cet article.
En premier lieu, nous définissons notre DAG. Il sera exécuté toutes les 10 minutes.
Nous mettons le paramètre Catchup (rattrapage) à False sans quoi le Scheduler, à son initialisation, exécutera les planifications du DAG qui n’ont pas pu être exécutées depuis la dernière exécution.
dag = DAG(
'article_Airflow',
description = "ETL Airflow",
schedule_interval = timedelta(minutes=10),
start_date = datetime(2022, 10, 18),
catchup=False,
tags = ['ETL_airflow'],
)
Tâche 1 - Récupération des données
La première tâche de notre pipeline est celle de se connecter au site internet :
https://www.prix-carburants.gouv.fr/rubrique/opendata/
Puis on télécharge une archive ZIP contenant un fichier XML. Ce dernier contient les prix, en temps réel (moins de 10 minutes) du carburant, et d’autres informations concernant des stations de service en France métropolitaine. L’archive est disponible via ce lien :
https://donnees.roulez-eco.fr/opendata/instantane
Pour ce faire, nous allons créer un BashOperator et passer la requête suivante :
'curl -X GET https://donnees.roulez-eco.fr/opendata/instantane > /d/article_airflow/prix_carburant.zip'
Le fichier sera enregistré avec le nom ‘prix_carburant.zip’ sous le dossier ‘/d/article_airflow’. Ci-dessous le paramétrage du l’opérateur Bash :
tache1 = BashOperator(
task_id= "EXTRACTION_uploadData",
bash_command = 'curl -X GET https://donnees.roulez-eco.fr/opendata/instantane > /d/article_airflow/prix_carburant.zip',
retries=3,
dag=dag,
)
Bien entendu, nous pouvons télécharger le même fichier différemment. Nous avons cependant choisi l’opérateur Bash pour utiliser plus d’un opérateur dans cet article et montrer comment des commandes ou des scripts Bash peuvent être intégrés dans des Workflows Airflow.
Voici ce à quoi ressemble la structure du fichier XML :
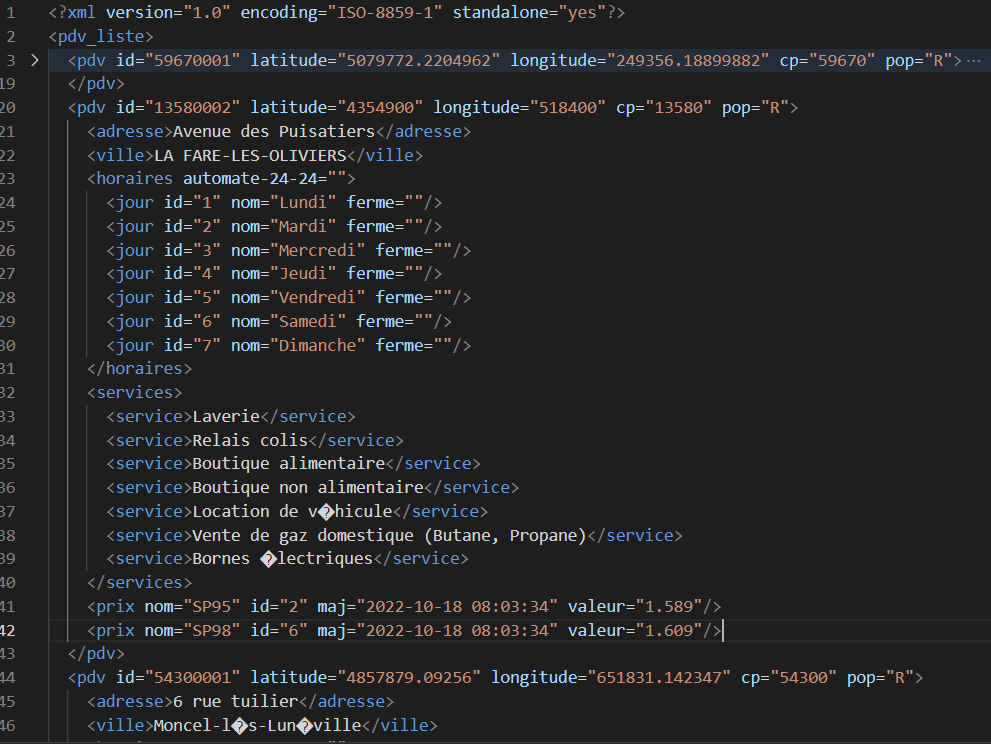
Tâche 2 - Transformation
Cette fois-ci, nous aurons recours à PythonOperator afin de pouvoir parser le fichier XML et transformer les données dans un DataFrame facilement avec Pandas.
tache2 = PythonOperator(
task_id='TRANSFORMATION_dataCalculation',
python_callable=TRANSFORMATION_data_calculation,
retries=3,
provide_context = True,
dag=dag,
)
Nous allons d’abord, dans la fonction TRANSFORMATION_data_calculation(), lire le fichier XML et le transformer en un DataFrame plat. Comme read_xml() supporte le format zip, nous n'avons pas à le décompresser.
df = pdx.read_xml('/d/article_airflow/prix_carburant.zip', encoding="ISO-8859-1").pipe(fully_flatten)
Nous obtiendrons ce DataFrame :
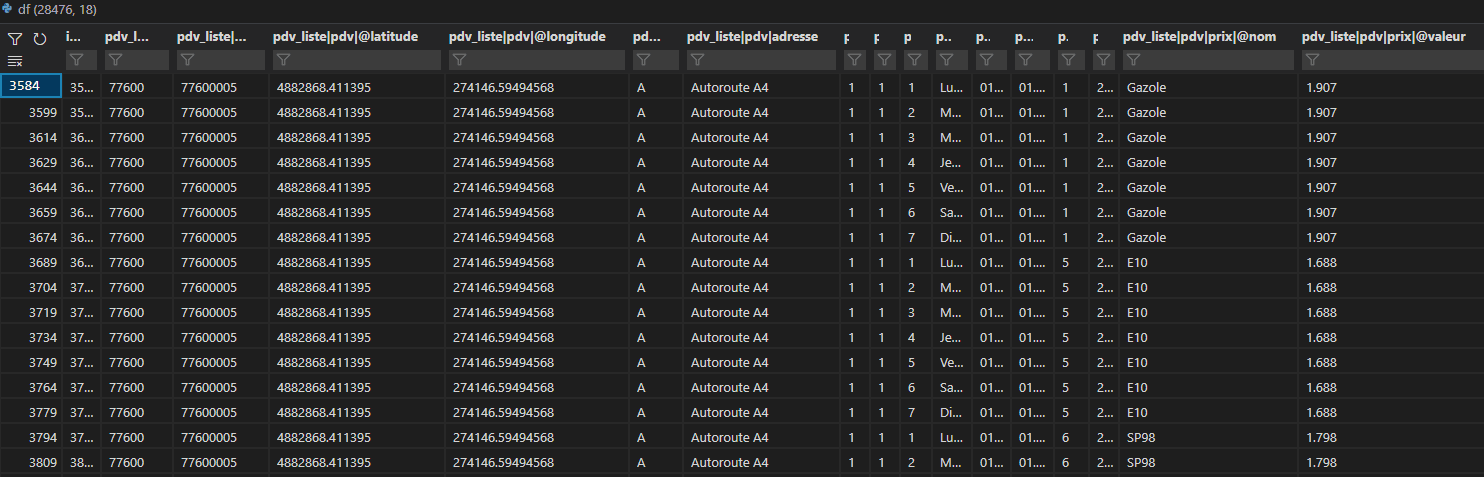
Maintenant nous appliquons un groupby pour regrouper le nom de la ville, le code postal, l’adresse, la latitude, la longitude, et les prix du carburant. Nous faisons une agrégation sur la colonne des prix :
df_final=df.groupby(["pdv_liste|pdv|ville","pdv_liste|pdv|@cp","pdv_liste|pdv|adresse","pdv_liste|pdv|@latitude","pdv_liste|pdv|@longitude","pdv_liste|pdv|prix|@nom"], as_index=False).agg({"pdv_liste|pdv|prix|@valeur": "min"})
Comme la colonne df_final["pdv_liste|pdv|prix|@nom"] contient tous les noms des carburants, elle cause la duplication des lignes. Ceci n'aidera pas pour analyser et visualiser les données. Nous allons donc pivoter cette colonne :
df_final = df_final.pivot(index=['pdv_liste|pdv|ville', 'pdv_liste|pdv|@cp', 'pdv_liste|pdv|adresse', 'pdv_liste|pdv|@latitude', 'pdv_liste|pdv|@longitude'], columns='pdv_liste|pdv|prix|@nom', values='pdv_liste|pdv|prix|@valeur').reset_index()
À présent, comme indiqué sur le site internet, nous devons diviser la latitude et la longitude par 100000 pour obtenir les bonnes valeurs. Avant cela il faudra convertir le type de ces colonnes en valeurs numériques.
df_final = df_final.astype({"pdv_liste|pdv|@latitude":'float',"pdv_liste|pdv|@longitude":'float', 'Gazole':'float', 'SP95':'float', 'SP98':'float'})
df_final["pdv_liste|pdv|@latitude"] = df_final["pdv_liste|pdv|@latitude"] / 100000
df_final["pdv_liste|pdv|@longitude"] = df_final["pdv_liste|pdv|@longitude"] / 100000
En passant la souris sur les stations de services, nous souhaitons faire apparaitre plusieurs détails. Nous rajoutons à notre DataFrame une colonne contenant ces informations :
date_time = datetime.now().strftime("%d/%m/%Y %H:%M:%S")
message = "Date: " + date_time + "<br>"
message += "Ville: " + df_final["pdv_liste|pdv|ville"].astype(str) + "<br>"
message += "Adresse: " + df_final['pdv_liste|pdv|adresse'].astype(str) + ', ' + df_final["pdv_liste|pdv|@cp"].astype(str) + "<br>"
message += "Diesel: " + df_final['Gazole'].astype(str) + '€' + "<br>"
message += "SP95: " + df_final['SP95'].astype(str)+ '€' + "<br>"
message += "SP98: " + df_final['SP98'].astype(str)+ '€' + "<br>"
df_final["pdv_liste|pdv|prix|@text"] = message
Nous allons maintenant sauvegarder notre DataFrame en local au format CSV. Nous le passerons par la suite à la tâche 3 afin de l’afficher sur une carte géographique.
df_final.to_csv('/d/article_airflow/prix_carburant.csv', header=True)
Voici le DataFrame final :
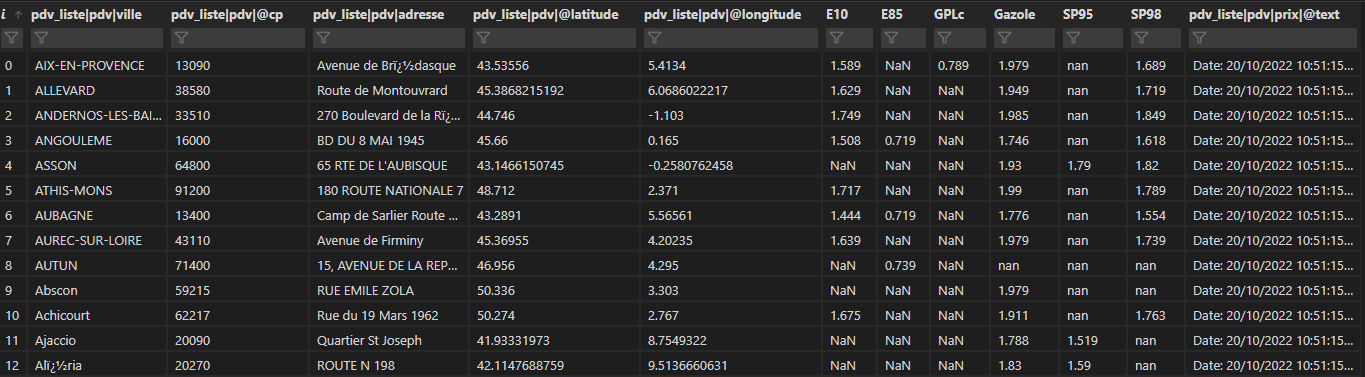
Pour aborder la notion de Xcom, nous allons vérifier si des prix sont trop élevés. Si tel est le cas, nous enverrons l’information à la tâche 4. Cette dernière à son tour envoie un email d’alerte.
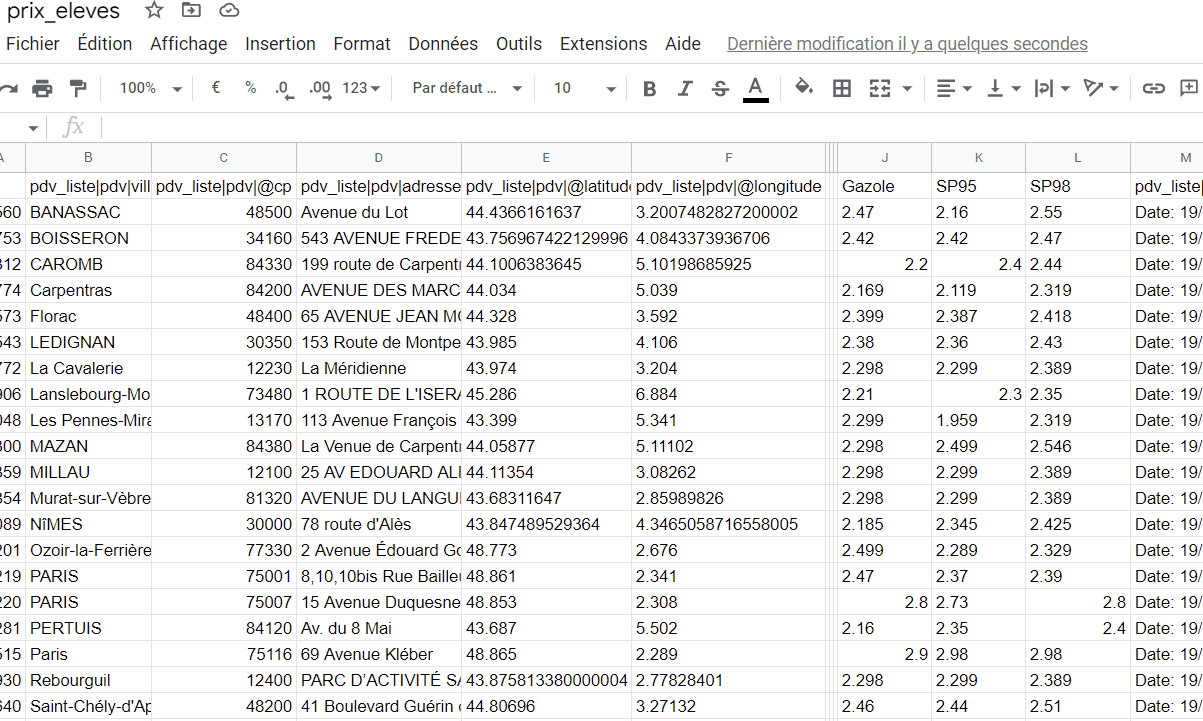
Comme le Xcom ne supporte pas des données non sérialisées, nous ne pouvons pas passer le DataFrame directement de la tâche 2 à la tâche 4. À la place, nous sauvegardons un autre fichier CSV, sous le nom ‘prix_eleves.csv’, ne contenant que les stations appliquant des prix élevés et nous passerons le dictionnaire :{‘expensive’ : True} en Xcom de la tâche 2 à la tâche 4.
df_expensive = df_final.where((df_final.Gazole > 2.5) | (df_final.SP95 > 2.3) | (df_final.SP98 > 2.3))
if not df_expensive.empty:
df_expensive.to_csv("/d/article_airflow/alerte/prix_eleves.csv", header=True)
context['task_instance'].xcom_push(key='expensive', value=True)
Tâche 3 - DataViz
Pour visualiser les données nous allons utiliser Plotly de Python. Nous allons donc paramétrer un autre opérateur Python de cette façon :
tache3 = PythonOperator(
task_id='LOAD_dataViz',
python_callable=LOAD_data_viz,
retries=3,
dag=dag,
)
Nous instancions une figure de type Scattergeo et passons en paramètre la latitude, la longitude, et les informations de chaque station. Nous mettons à jour la figure avec un titre en n'affichant que l’Europe. Malheureusement nous ne pouvons pas zoomer plus que ça. Le paramètre ne prend que ces valeurs : world, usa, europe, asia, africa, north america, south america. Il existe toutefois d'autres manière de n'afficher que la France, mais ce n’est pas le but de cet article.
df_final = pd.read_csv('/d/article_airflow/prix_carburant.csv',sep=',', encoding="UTF-8")
fig = go.Figure(data=go.Scattergeo(
lat = df_final['pdv_liste|pdv|@latitude'],
lon = df_final['pdv_liste|pdv|@longitude'],
text = df_final['pdv_liste|pdv|prix|@text'],
mode = 'markers',
marker = dict(
opacity = 0.8,
reversescale = True,
autocolorscale = True,
symbol = 'circle',
line = dict(
width=1,
color=df_final['Gazole']
),
cmin = df_final['Gazole'].min(),
color = df_final['Gazole'],
cmax = df_final['Gazole'].max(),
colorbar_title="Prix",
colorbar_x = -0.05
)
))
fig.update_layout(
title = 'Prix carburant à temp réel :)',
geo_scope='europe',
)
fig.show(
Tâche 4 - Alerting
Cette fois ci nous utilisons le EmailOperateur qui nous permettra d’envoyer un email lorsqu'il existe des prix trop élevés. Nous passons en paramètre : l’adresse email du destinataire, l’objet du email, son contenu. Avec le paramètre ‘fichier’, nous préciserons le chemin et le nom du fichier à envoyer en pièce jointe. Dans notre cas, nous allons envoyer le csv ‘expensive.csv’ sauvegardé par la tâche 2.
Lors de la définition de l’opérateur, il faudra préciser ‘provide_context = True’ pour que nous puissions Pull le dictionnaire qui a été Push par la tâche 2.
Pour que l’envoi des mails se fasse, il faudra définir un serveur SMTP dans le fichier airflow.cfg.
tache4 = PythonOperator(
task_id = 'Alerting',
python_callable = alerte_send_email,
dag=dag,
retries=3,
provide_context = True
)
context = kwargs['ti']
is_expensive = context.xcom_pull(task_ids= 'TRANSFORMATION_dataCalculation', key= 'expensive')
print(is_expensive)
if is_expensive:
email = EmailOperator(task_id="email_alerte",
to ="bachir.atmani.2011@gmail.com",
subject="Aletre sur les prix du carburant",
html_content="En pièce jointe la liste des
stations appliquant des prix trop élevés.",
files= ["/d/article_airflow/alerte/prix_eleves.csv"],
dag = dag )
email.execute(context=context)
Résultat final
Nous devons réinitialiser, à l’aide des commandes ci-dessous, la base de données d’Airflow pour que le nouveau DAG et le paramétrage du serveur SMTP soient pris en compte.
airflow db init
airflow scheduler
Ci-dessous nous pouvons voir les exécutions du DAG, toutes les 10 minutes, avec le statut succès.
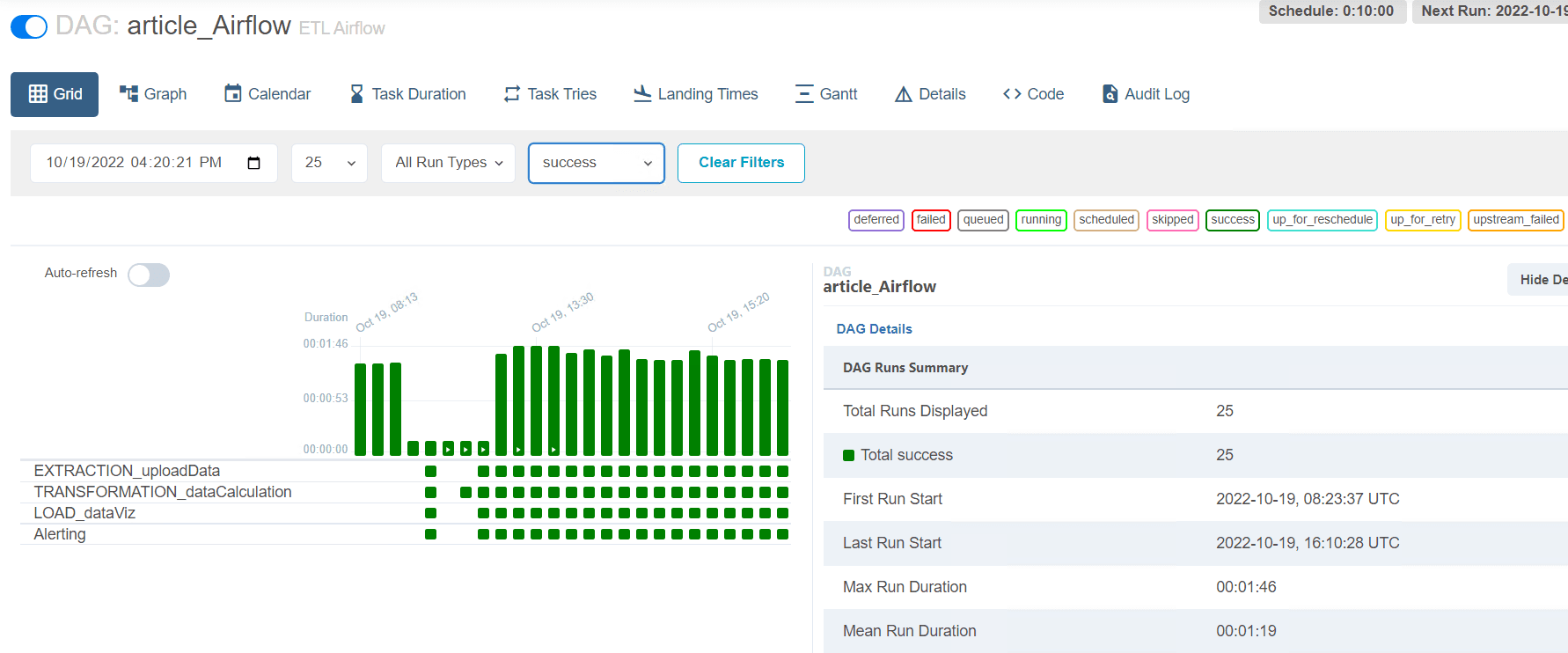
Et ci-dessous la carte avec les prix et les autres informations en temps réel de chaque station. La carte et les informations sont mises à jour toutes les dix minutes.
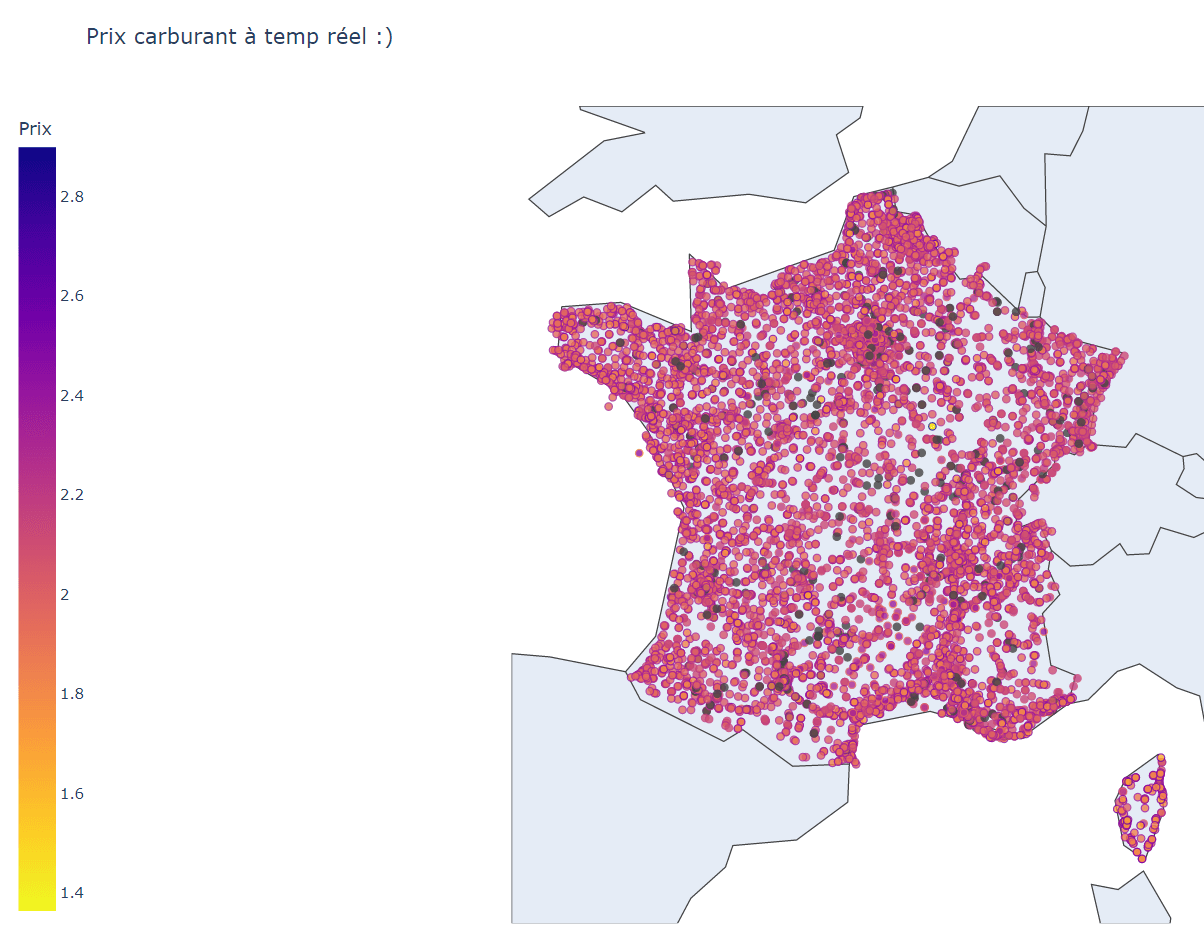
Nous pouvons remarquer qu’il y a effectivement des stations appliquant des prix élevés en ce moment, notamment en région parisienne. Nous ne sommes pas loin de 3€ le litre !


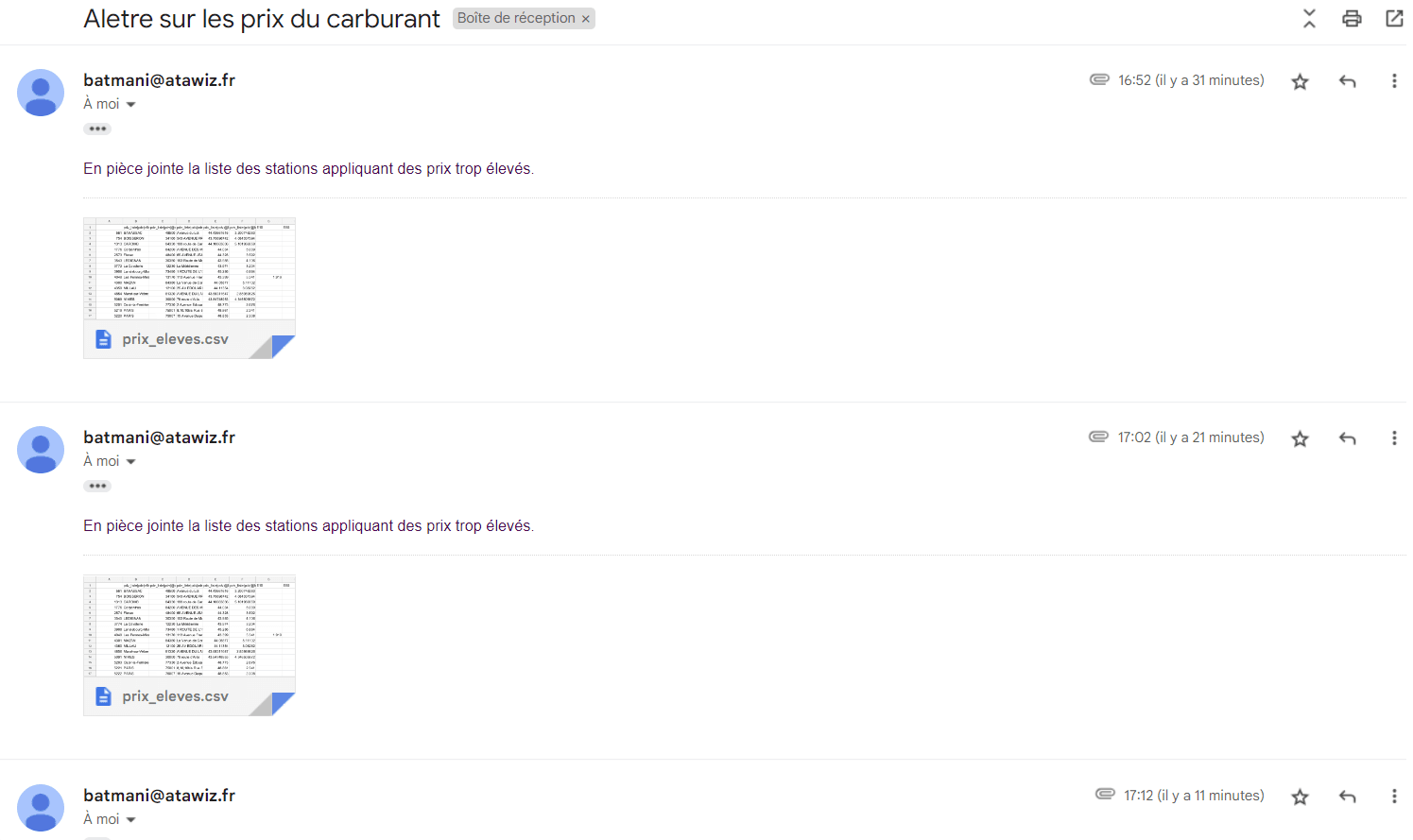
Ici nous voyons que les mails sont envoyés toutes les 10 minutes. En pièce jointe également le fichier CSV avec les prix élevés.
Conclusion
Dans cet article, nous avons vu comment exploiter certains composants d’Airflow pour l’orchestration d’un workflow. Airflow est le parfait outil pour ce genre de situation quand nous sommes on-premise.
Il est très puissant et nous offre la possibilité de travailler sur des pipelines très complexes en les orchestrant et en les administrant. Nous pouvons imaginer des pipelines d’ingestion de données et de déploiement de modèle Machine Learning. L’autre avantage, c’est qu’il nous permet également de manipuler des données avec Python, ce dernier étant l’un des langages les plus utilisés dans la Data.
Airflow est très populaire et très loin devant ses concourants comme Luigi ou Kuberflow, ayant près de 28 000 étoiles et plus de 2 200 contributeurs sur Github.
Rappelons tout de même une autre fois qu’il ne s’agit pas d’un ETL. Dans notre exemple simple, toutes les transformations de données ont été effectuées dans Airflow. Mais lorsqu’il s’agira de pipelines beaucoup plus complexes qui demandent d’importantes ressources, il est conseillé de faire des calculs, par exemple, sur des clusters Hadoop ou Spark.
Nous avons également vu que le transfert de données entre tâches est possible grâce à Xcom. Mais ce dernier est très limité. Il ne supporte que des données sérialisées et ne permet donc pas d’échanger des DataFrames par exemple.
Pour ce faire, il faudra penser à le passer en paramètre dans les tâches (chose que nous n'avons pas abordé dans cet article). Une autre solution est de créer des tables temporaires ou des fichiers en local dans lesquels les tasks pourront lire et écrire.
